Textsuche für die präzise Extraktion von Daten aus PDF-Dokumenten
PDF-Dokumente werden in vielen Phasen moderner Geschäftsprozesse eingesetzt und dienen oft als bevorzugtes Format für Rechnungen, Berichte, rechtliche Verträge und andere wichtige Dokumente. Obwohl PDFs ideal sind, um die Inhaltstreue und ein bestimmtes Layout zu gewährleisten, erschwert ihre Struktur die automatisierte Datenextraktion. Für Unternehmen, die sich mit Datenintegration und ETL-Prozessen (Extract, Transform, Load) beschäftigt sind, ist es unerlässlich, Informationen aus PDFs zu extrahieren – und hier kommt der MapForce PDF Extractor ins Spiel.
Der MapForce PDF-Extraktor enthält verschiedene Werkzeuge, mit denen Sie Extraktionsregeln visuell definieren können, um PDF-Daten in andere Formate zu übertragen. Eine besonders nützliche Funktion, um sich auf bestimmte Inhalte zu konzentrieren, ist die Textsuche. Hier erfahren Sie, wie sie funktioniert – einschließlich einer Video-Demonstration.

Zugriff auf PDF-Daten für ETL-Prozesse
Obwohl PDFs oft wichtige Daten enthalten, sind sie grundsätzlich nicht für die Datenverarbeitung konzipiert. Im Gegensatz zu strukturierten Formaten wie XML oder JSON legen PDFs Wert auf die Darstellung anstatt auf die leichte Zugänglichkeit der Inhalte.
Dies kann zu Engpässen führen, wodurch Unternehmen gezwungen sind, auf zeitaufwändige manuelle Prozesse zurückzugreifen, um die benötigten Daten aus PDF-Dokumenten zu extrahieren. Die Automatisierung der Datenauswahl eliminiert die manuelle Dateneingabe, reduziert menschliche Fehler und setzt Ressourcen für Aufgaben mit höherem Mehrwert frei.
Der MapForce PDF-Extraktor macht dies einfach und bietet eine unkomplizierte Möglichkeit, die Struktur eines PDF-Dokuments zu definieren, um Daten daraus auf automatisierte Weise zu extrahieren. Während Sie Extraktionsregeln definieren, erstellt das Tool ein Baummodell, das die Datenstruktur darstellt. Mithilfe dieses Modells können die extrahierten Daten in MapForce anderen Formaten wie Datenbanken, JSON und XML zugeordnet werden.
Mithilfe von visuellen Werkzeugen und der Drag-and-Drop-Funktionalität können Sie nur bestimmte Teile des Inhalts extrahieren, Inhalte aus verschiedenen Seiten kombinieren, Tabellen in Zeilen aufteilen, Inhalte gruppieren und vieles mehr. Neben der Möglichkeit, Dokumentabschnitte manuell per Mausklick zu Ihrem Vorlagen hinzuzufügen, beinhaltet MapForce eine Vorschlagsfunktion, die Tabellen erkennt, sodass diese automatisch extrahiert werden können. Anschließend können Sie.. Regeln für die Extraktion von Daten aus PDF-Dokumenten Kann bei Bedarf weiter verfeinert werden.
Bei PDFs mit vielen Tabellen kann es hilfreich sein, Extraktionsregeln mithilfe einer Textsuche zu definieren.
Suchen Sie nach Text, um Daten aus PDF-Dokumenten zu extrahieren
Der MapForce PDF-Extraktor bietet die Möglichkeit, Text innerhalb eines Dokuments sowohl in der Benutzeroberfläche als auch zur Laufzeit zu suchen.
Dies ist besonders nützlich bei großen PDF-Dokumenten mit zahlreichen Tabellen, bei denen Sie möglicherweise nur bestimmte Daten extrahieren müssen, oder wenn Sie Regeln für wiederkehrende Elemente definieren möchten. Beispielsweise könnten Sie bei der Erstellung einer Vorlage zum Extrahieren von Daten aus jährlichen Finanzberichten nach dem Begriff "Ausgaben" suchen und die entsprechende Tabelle mit Zahlen entsprechend verarbeiten.
Detaillierte Suchoptionen wie die Unterscheidung zwischen Groß- und Kleinschreibung, die Filterung nach Format (Schriftart, Schriftstärke usw.) sowie die Suche nach ganzen oder einzelnen Wörtern ermöglichen eine präzise Eingrenzung der Suchergebnisse.
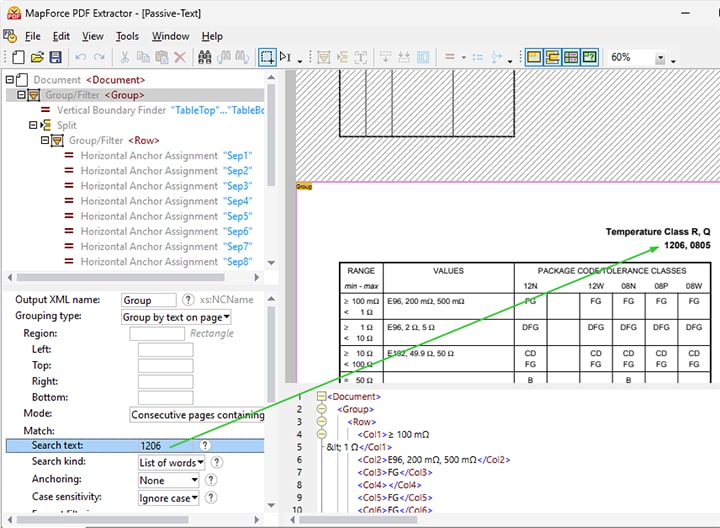
Die Suchfunktion ermöglicht es Ihnen, Regeln für die Verarbeitung von Daten in Bezug auf den Suchbegriff festzulegen. Dazu gehören:
Teilen Sie eine Region basierend auf einem Suchbegriff (z. B. "Artikelnummer" im Demo-Video unten)
Gruppieren Sie die Daten anhand von Text, der auf einer Seite gefunden wird (z. B. "Artikeldetails" im Video)
Die Fähigkeit, relevante Tabellen und Textausschnitte anhand einer Textsuche präzise zu identifizieren und zu extrahieren, vereinfacht die Erstellung von Vorlagen, spart Zeit und erhöht die Genauigkeit.
Hier ein Einblick in die Textsuche-Funktionalität des MapForce PDF-Extraktors in Aktion. In diesem Tutorial lernen Sie, wie Sie die Textsuche nutzen können, um eine Vorlage zu erstellen, mit der PDF-Daten in JSON-Format umgewandelt werden können. Dies ist eine häufige Anforderung in Datenintegrations- und ETL-Prozessen.
Sobald Ihre PDF-Extraktionsvorlage definiert ist, können Sie diese zu einem MapForce-Projekt hinzufügen Projekt zur Datenzuordnung um es in ein anderes Format zu konvertieren oder es zur Speicherung in einer Datenbank zu verarbeiten.
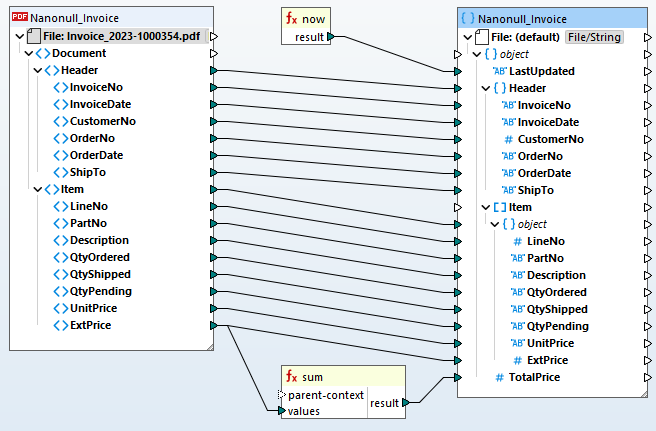
Für die Automatisierung von PDF-ETL-Prozessen unterstützt MapForce Server PDF-Extraktionsregeln, die in MapForce definiert sind.
Probieren Sie es selbst mit einer kostenlosen 30-tägigen Testversion Gerichtsverfahren von MapForce.