Das Entsperren von gescannten PDF-Dateien mit OCR-Unterstützung in MapForce
Für viele Organisationen sind PDFs sowohl eine wichtige Datenquelle als auch ein ständiges Hindernis in ETL- und Datenintegrationsprozessen. Während moderne PDFs mit auswählbarem Text relativ einfach zu verarbeiten sind, ist ein erheblicher Teil der geschäftskritischen Daten in gescannten Dokumenten eingeschlossen – digitalisierten Papierarchiven, veralteten Aufzeichnungen und bildbasierten Dateien, in denen Text nur als Pixel, nicht aber als maschinenlesbare Zeichen existiert. Die Herausforderung besteht darin, ihren unstrukturierten Inhalt in nutzbare Daten umzuwandeln.
Die OCR-Funktion (Optical Character Recognition) im MapForce PDF-Extraktor schließt diese Lücke, indem sie Inhalte aus PDF-Dokumenten, die auf Bildern basieren, in strukturierte, extrahierbare Daten umwandelt, die für die Verarbeitung und die Übertragung in andere Formate bereitstehen.

Die Umwandlung von Scans in strukturierte Daten
Organisationen, die über Jahrzehnte Papierdokumente gesammelt haben, stehen vor einer Herausforderung, die die Digitalisierung allein nicht lösen kann: Das Scannen bewahrt zwar das Aussehen eines Dokuments, aber nicht seine Daten. Gescannte PDFs bleiben somit lediglich Bilder von Text, die Computer nicht durchsuchen oder verarbeiten können. Für Datenexperten, die ETL-Pipelines entwickeln, bedeutet dies, dass wertvolle historische Informationen trotz ihrer „Digitalisierung“ unzugänglich bleiben. Viele wichtige Dokumente, wie handschriftliche Formulare, ältere Finanzberichte, regulatorische Unterlagen und gescannte Verträge, fallen in diese Kategorie und zwingen Teams, sich auf manuelle, fehleranfällige Dateneingabe zu verlassen, was ansonsten automatisierte Arbeitsabläufe verlangsamt.
Deshalb ist die optische Zeichenerkennung (OCR) ein entscheidender Bestandteil jedes Projekts zur Integration von PDF-Daten.
Die OCR-Technologie wandelt Bilder von Text in tatsächliche Zeicheninformationen um, die Anwendungen verarbeiten können. Im MapForce PDF Extractor fungiert die OCR-Funktion als Vorverarbeitungsschritt, der gescannte Dokumente in das gleiche strukturierte Format wie textbasierte PDFs umwandelt. Dadurch wird eine einheitliche Weiterverarbeitung ermöglicht, unabhängig vom Ursprung des Quelldokuments.
Die MapForce-Implementierung basiert auf Tesseract OCR, einer Open-Source-Erkennungssoftware, die für ihre hohe Genauigkeit bekannt ist. Die Technologie kombiniert traditionelle Mustererkennung mit modernen neuronalen Netzwerkansätzen, insbesondere LSTM (Long Short-Term Memory). Diese hybride Architektur bietet die Flexibilität, eine Vielzahl von Dokumenttypen und -layouts zu verarbeiten, während gleichzeitig eine hohe Genauigkeit in mehreren Sprachen gewährleistet wird, darunter Englisch, Deutsch, Französisch, Japanisch und Spanisch. (Die MapForce-Software selbst ist ebenfalls in diesen Sprachen verfügbar.)
Die Integration von Optical Character Recognition (OCR) in den MapForce PDF-Extraktor ist ein großer Vorteil. Anstatt Entwickler zu zwingen, OCR als separaten Vorverarbeitungsschritt mit externen Tools auszuführen und dann die Ergebnisse zu importieren, integriert MapForce diese Funktion direkt in den PDF-Extraktionsprozess, was Zeit spart und die Automatisierung ermöglicht.
Von der optischen Zeichenerkennung zur Extraktion strukturierter Daten
Natürlich ist die Texterkennung nur ein Teil der Lösung. Um gescannte Inhalte verwertbar zu machen, muss dieser Text für weitere Verarbeitungsschritte strukturiert werden. Der eigentliche Mehrwert entsteht, wenn dieser Text in strukturierte Daten umgewandelt wird, die für die Zuordnung und Transformation bereitstehen.
Wenn Sie eine optische Zeichenerkennung (OCR) auf eine gescannte PDF-Datei in MapForce durchführen, zeigt der Prozessor den erkannten Inhalt in einer Objektstruktur an. Eine Überlagerung des Dokuments selbst zeigt, wie der OCR-Prozessor Wörter im Scanbereich erkannt hat, wobei erkannte Wörter in Grün dargestellt werden. Wörter, die rot hervorgehoben sind, wurden nicht zur Struktur hinzugefügt, da ihre Zuverlässigkeitsbewertung den vom Prozessor festgelegten Schwellenwert nicht erreicht hat. Sie können die Struktur sowie die grünen und roten Wörter bei Bedarf manuell bearbeiten, und zwar mithilfe einfacher, intuitiver Werkzeuge.
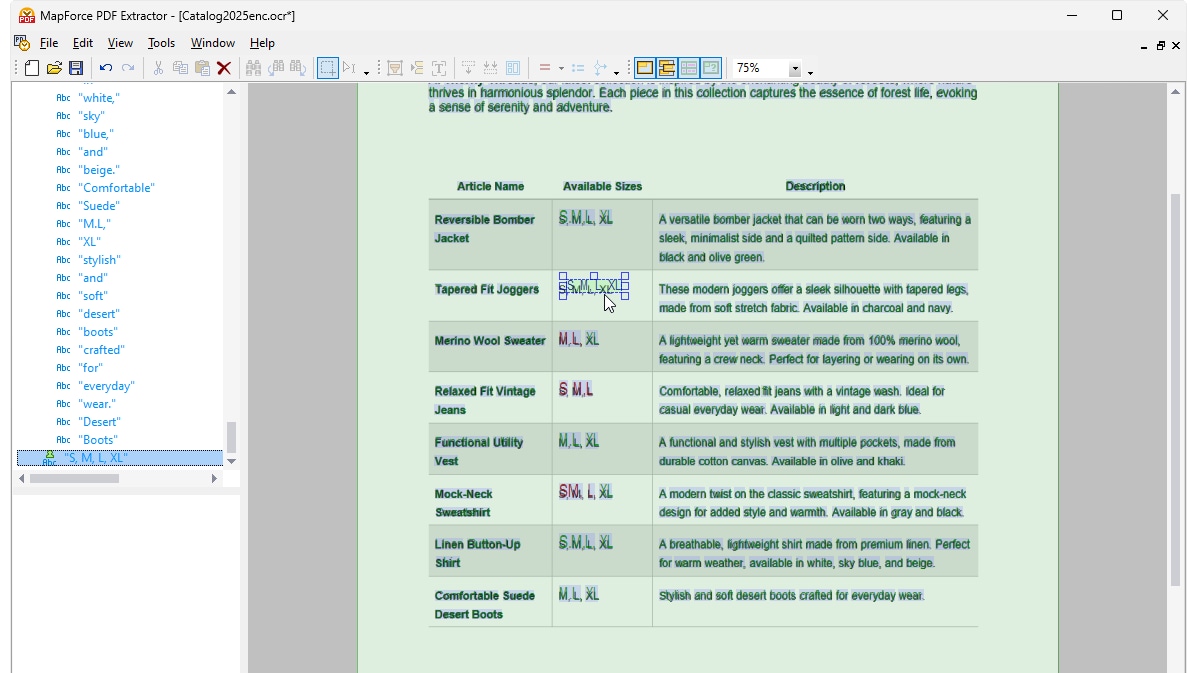
Sobald Sie mit den Ergebnissen der optischen Zeichenerkennung (OCR) zufrieden sind, wird der erkannte Text dem Standard-Extraktionsablauf des MapForce PDF Extractor hinzugefügt. Der PDF Extractor verfügt über eine leistungsstarke Vorschlagsfunktion, die automatisch häufige Dokumentelemente wie Tabellen und Textblöcke erkennt und versucht, deren Struktur zu bestimmen. Sie können diese Struktur bei Bedarf verfeinern, indem Sie Inhalte in Zeilen/Spalten aufteilen, Extraktionsregeln basierend auf Überschriften oder Schlüsselwörtern festlegen usw. Die von Ihnen definierte Vorlage spiegelt die Struktur des Dokuments wider, um sie für die Zuordnung verfügbar zu machen.
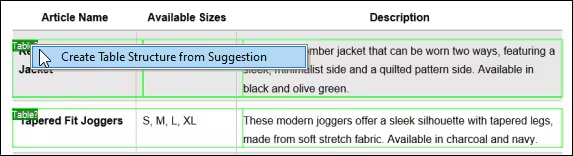
Mit dieser vorlagenbasierten Konfiguration läuft die optische Zeichenerkennung (OCR) nur einmalig bei der Erstellung der Vorlage. Danach kann MapForce andere Dokumente mit dem gleichen Layout mithilfe der gespeicherten Extraktionsregeln verarbeiten – eine erneute OCR-Verarbeitung ist nicht erforderlich. Dies spart Zeit und Ressourcen bei umfangreichen Datenintegrations- oder ETL-Prozessen, die standardisierte Formulare oder Berichte verarbeiten.
Die extrahierten Daten werden zu einer visuellen Struktur, die den Inhalt der PDF-Datei darstellt. Diese Struktur können Sie dann in ein beliebiges unterstütztes Zielformat überführen (Datenbanken, JSON, Excel, XML, EDI, Shopify usw.). Das visuelle Mapping-Konzept ermöglicht es, Transformationen einfach per Drag-and-Drop zu definieren, um Verbindungen zwischen den Quelldaten und den Zieldatenstrukturen herzustellen. Eine umfassende Funktionsbibliothek und ein visueller Funktionsersteller ermöglichen die Verarbeitung von Datentypkonvertierungen, Filterungen und bedingter Logik.
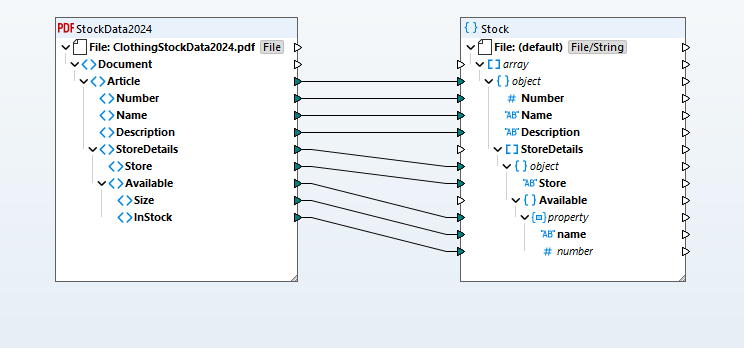
Basierend auf Ihrer Datendefinition transformiert MapForce die Daten sofort. Alternativ können Sie die erweiterte Version von MapForce Server nutzen, um eine leistungsstarke Automatisierung zu realisieren.
Testen Sie die OCR-Funktionen im PDF-Extraktor noch heute mit einer kostenlosen Testversion von MapForce!