精确PDF数据提取的文本搜索功能
PDF文档在现代商业流程的许多环节中被广泛使用,通常是发票、报告、法律合同和其他重要文档的首选格式。虽然PDF格式非常适合保留内容完整性和特定的视觉布局,但其结构使得自动数据提取变得困难。对于从事数据集成和ETL(提取、转换、加载)的组织来说,提取PDF文档中包含的信息是必不可少的——而MapForce PDF提取器正是为此而生。
MapForce PDF提取器包含多种工具,可用于直观地定义提取规则,将PDF数据映射到其他格式。其中,文本搜索功能特别有用,可以帮助您精准定位特定内容。以下是其工作原理,并附有视频演示。

用于ETL的PDF数据访问
虽然PDF文件通常包含重要数据,但它们并非专门为数据处理而设计的。与XML或JSON等结构化格式不同,PDF文件更注重内容的呈现,而非内容的易于访问。
这可能会造成瓶颈,迫使组织依赖耗时的手动流程来从PDF文件中提取所需的数据。自动化数据提取可以消除手动数据录入,减少人为错误,同时释放资源,使其能够用于更具价值的任务。
MapForce PDF 提取器 能够轻松实现这一功能,它提供了一种简单的方法来定义 PDF 文档的结构,从而能够以自动化方式从中提取数据。在您定义提取规则时,该工具会构建一个树状模型,该模型代表了数据的结构。利用这个模型,提取的数据可以在 MapForce 中映射到其他格式,例如数据库、JSON 和 XML。
通过使用可视化工具和拖放功能,您可以提取内容的部分内容,将来自不同页面的内容片段进行组合,将表格拆分成行,对内容进行分组,等等。除了手动通过点击添加文档部分到模板的功能外,MapForce还包含一个智能引擎,它可以识别表格,以便自动提取。然后,您可以根据需要进一步完善PDF数据提取规则。
在包含大量表格的PDF文件中,使用文本搜索来定义提取规则可能会很有帮助。
搜索文本以提取PDF数据
MapForce PDF 提取工具提供了在界面上以及运行时搜索文档中文本的选项。
这在大型PDF文档中尤其有用,尤其是在文档包含大量表格,但您只需要提取其中一部分数据,或者需要为重复出现的元素定义规则时。例如,在创建用于提取年度财务报告数据的模板时,您可以搜索“支出”一词,然后相应地处理该文本后面的表格数据。
细粒度的搜索选项,例如区分大小写、格式过滤(字体、字重等)以及对完整单词或部分单词的搜索,可以实现精确的搜索目标。
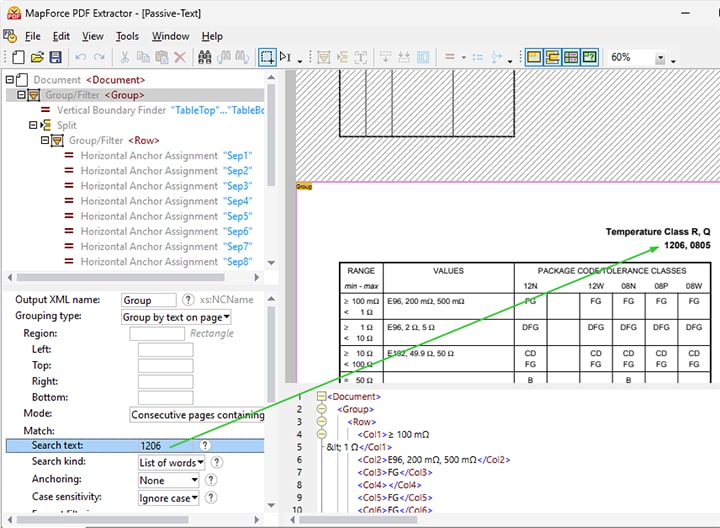
搜索功能允许您定义与搜索关键词相关的处理数据规则。这些规则包括:
根据搜索关键词(例如,在下面的演示视频中,关键词可以是“文章编号”)来划分区域
将页面上的文本内容进行分组(例如,在视频中,可以将“文章详情”等内容进行分组)
通过文本搜索,能够精准地定位并提取相关的数据表格和片段,这简化了模板的创建过程,节省了时间,并提高了准确性。
以下是 MapForce PDF 提取器中文本搜索功能的使用示例。在本教程中,您将学习如何使用文本搜索功能,从而创建一个模板,将 PDF 数据映射到 JSON 格式,这在数据集成和 ETL 流程中是一项常见的需求。
一旦您定义了PDF提取模板,就可以将其添加到MapForce中 数据映射项目 将其转换为另一种格式,或者对其进行处理以便存储在数据库中。
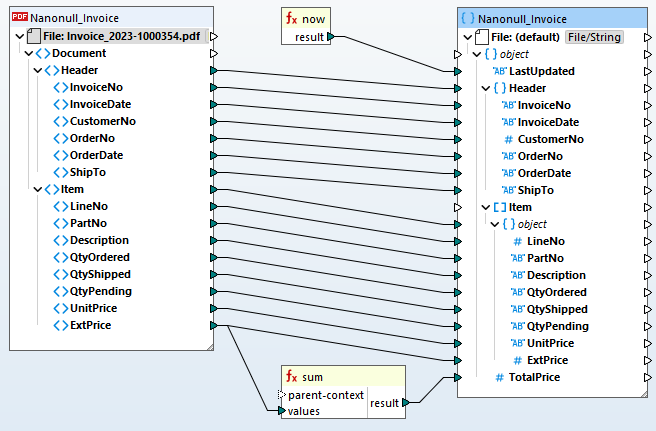
为了自动化 PDF 数据抽取转换加载 (ETL) 流程,MapForce Server 支持在 MapForce 中定义的 PDF 提取规则。
您可以免费试用30天,亲身体验一下 试验 关于 MapForce 的信息。