Recherche textuelle pour une extraction précise des données à partir de fichiers PDF
Les documents PDF sont utilisés à de nombreuses étapes des processus métier modernes, et servent souvent de format privilégié pour les factures, les rapports, les contrats juridiques et autres documents importants. Bien que les PDF soient idéaux pour préserver l'intégrité du contenu et une mise en page spécifique, leur structure rend l'extraction automatisée des données difficile. Pour les organisations impliquées dans l'intégration de données et l'ETL (Extraction, Transformation, Chargement), l'accès aux informations contenues dans les PDF est essentiel, et c'est là que le logiciel MapForce PDF Extractor entre en jeu.
L'outil MapForce PDF Extractor comprend plusieurs outils permettant de définir visuellement des règles d'extraction pour convertir les données PDF vers d'autres formats. L'une de ces fonctionnalités, particulièrement utile pour cibler un contenu spécifique, est la recherche de texte. Voici comment elle fonctionne, avec une démonstration vidéo.

Accéder aux données PDF pour l'ETL
Bien que les fichiers PDF contiennent souvent des données importantes, ils ne sont pas conçus intrinsèquement pour le traitement de données. Contrairement aux formats structurés tels que XML ou JSON, les fichiers PDF privilégient la présentation plutôt que l'accessibilité du contenu.
Cela peut créer des goulots d'étranglement, obligeant les organisations à recourir à des processus manuels chronophages pour obtenir les données dont elles ont besoin à partir de fichiers PDF. L'automatisation de l'extraction de données élimine la saisie manuelle, réduisant ainsi les erreurs humaines tout en libérant des ressources pour des tâches à plus forte valeur ajoutée.
L'outil MapForce PDF Extractor facilite cette tâche en offrant un moyen simple de définir la structure d'un document PDF afin d'en extraire les données de manière automatisée. Au fur et à mesure que vous définissez les règles d'extraction, l'outil crée un modèle arborescent qui représente la structure des données. Grâce à cela, les données extraites peuvent être converties vers d'autres formats, tels que les bases de données, JSON et XML, dans MapForce.
Grâce à des outils visuels et à une fonctionnalité de glisser-déposer, vous pouvez extraire uniquement des portions du contenu, combiner des éléments de différentes pages, diviser les tableaux en lignes, regrouper du contenu, et bien plus encore. En plus de la possibilité d'ajouter manuellement des sections de documents à votre modèle en utilisant des clics, MapForce inclut un moteur de suggestions qui identifie les tableaux afin qu'ils puissent être extraits automatiquement. Par la suite, les règles d'extraction de données PDF peuvent être affinées si nécessaire.
Dans les fichiers PDF contenant de nombreux tableaux, il peut être utile de définir des règles d'extraction en utilisant une recherche de texte.
Rechercher du texte pour extraire des données à partir de fichiers PDF
L'outil d'extraction PDF de MapForce offre la possibilité de rechercher du texte dans un document, soit directement dans l'interface utilisateur, soit pendant l'exécution du programme.
Ceci est particulièrement utile pour les documents PDF volumineux contenant de nombreux tableaux, où vous n'avez peut-être besoin d'extraire que certaines données, ou lorsque vous devez définir des règles pour les éléments récurrents. Par exemple, lors de la création d'un modèle pour extraire des données à partir de rapports financiers annuels, vous pouvez rechercher le terme "Dépenses" et traiter le tableau de chiffres qui suit ce texte en conséquence.
Des options de recherche granulaires, telles que la sensibilité à la casse, le filtrage par format (police, épaisseur de la police, etc.) et les recherches de mots entiers ou partiels, permettent de cibler précisément les résultats.
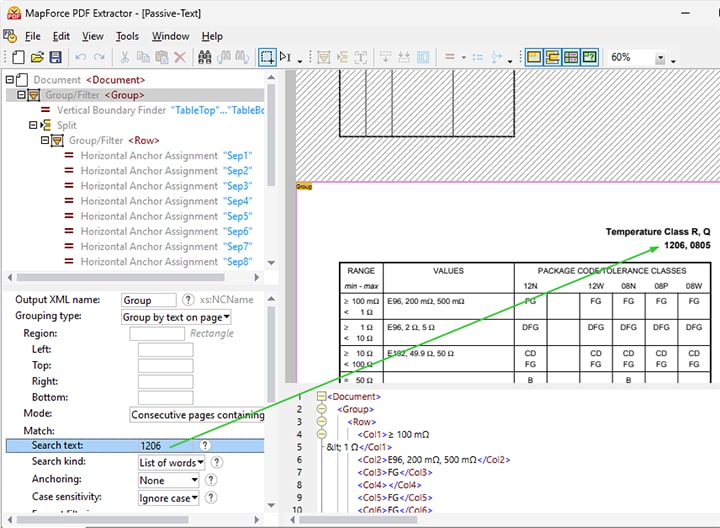
La fonction de recherche vous permet de définir des règles pour le traitement des données en fonction du terme de recherche. Ces règles comprennent :
Diviser une région en fonction d'un terme de recherche (par exemple, "numéro d'article" dans la vidéo de démonstration ci-dessous)
Regrouper les données en fonction du texte présent sur une page (par exemple, les "détails de l'article" dans la vidéo)
La possibilité d'identifier et d'extraire uniquement les tableaux et les extraits pertinents, en fonction d'une recherche textuelle, simplifie la création de modèles, ce qui permet de gagner du temps et d'améliorer la précision.
Voici une démonstration du fonctionnement de la fonction de recherche de texte de l'outil MapForce PDF Extractor. Dans ce tutoriel, vous apprendrez à utiliser la recherche de texte pour créer un modèle permettant de convertir des données PDF en format JSON, une exigence courante dans les processus d'intégration de données et d'ETL (Extraction, Transformation, Chargement).
Une fois que votre modèle d'extraction PDF est défini, vous pouvez l'ajouter à un projet MapForce projet de cartographie des données pour la convertir vers un autre format ou pour la traiter afin de la stocker dans une base de données.
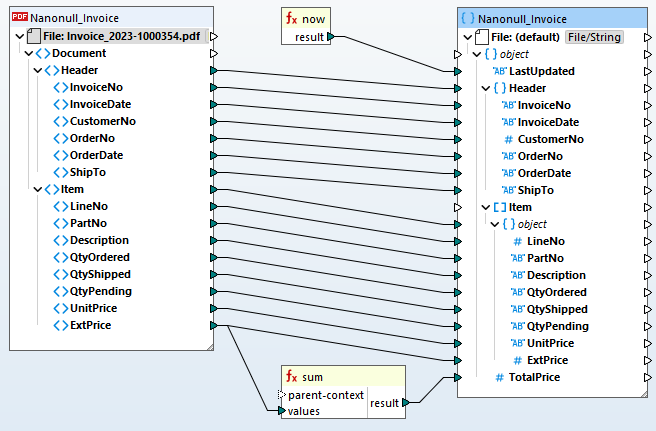
Pour automatiser les pipelines ETL de fichiers PDF, MapForce Server prend en charge les règles d'extraction PDF définies dans MapForce.
Essayez par vous-même grâce à une période d'essai gratuite de 30 jours essai de MapForce.