MapForce bietet dynamischen Zugriff auf Knotennamen
Es gibt Situationen, insbesondere wenn man mit unstrukturierten Daten arbeitet, in denen es wünschenswert sein kann, sowohl die strukturellen Komponenten als auch den Inhalt eines Datenstroms zu verarbeiten und zu transformieren. MapForce kann dynamisch auf Knotennamen von XML-Elementen, Attributen oder Spalten von Textdateien, wie beispielsweise den Inhalten von CSV-Dateien, zugreifen, um diese als Zielkomponenten zu verwenden.
Der dynamische Zugriff auf Knotennamen ermöglicht die sofortige Erstellung von Ziel-Elementen und -Attributen, deren Namen nicht im Voraus bekannt sein müssen oder speziell in der Datenzuordnung definiert werden müssen. Diese Funktion ermöglicht die Erstellung von viel allgemeineren, flexibleren und wiederverwendbaren Zuordnungen, die weniger manuelle Eingriffe erfordern, falls sich die Datenmodelle weiterentwickeln.

Hier ist ein Beispiel für eine sehr häufige CSV-Dateiformat, bei der die Datenfelder nicht durch Spaltennamen, sondern durch Beschriftungen in einer benachbarten Zelle innerhalb der Zeile gekennzeichnet sind:
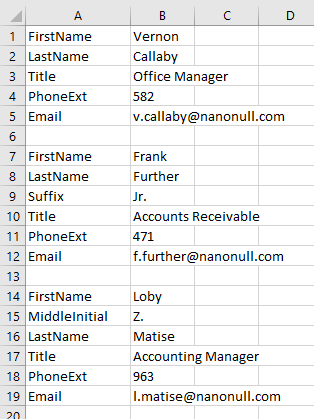
Die Datensätze in diesem Beispiel sind nicht einmal konsistent aufgebaut, da ein Datensatz einen zusätzlichen Teil nach dem Nachnamen enthält, während ein anderer einen Vornameninitiale enthält.
Eine typische Anforderung bei der Datenzuordnung für Dateien dieser Art besteht darin, die Zellen in Spalte A als XML-Elementnamen und die Zellen in Spalte B als Werte für jedes entsprechende Element zuzuordnen. Dies lässt sich jetzt einfach mit dynamischer Zuordnung von Knotennamen realisieren. Sehen wir uns an, wie das funktioniert.
Dynamischer Zugriff auf die Namen von XML-Elementen
Wir beginnen damit, ein sehr einfaches XML-Schema für das Ziel der Datenabbildung zu erstellen. Dieses Schema verwendet das Element <xs:any>, um ein komplexes

Wir beginnen die Zuordnung, indem wir die CSV-Datei importieren und eine Gruppierungsfunktion verwenden, die jedes Mal, wenn "FirstName" in Spalte A der Eingabedatei vorkommt, ein neues
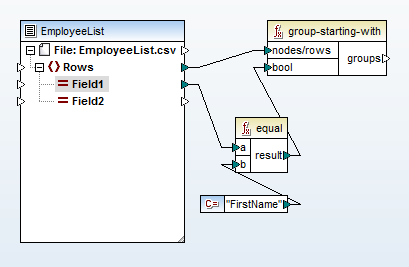
Als Nächstes fügen wir das gewünschte XML-Schema hinzu und klicken mit der rechten Maustaste auf das Element
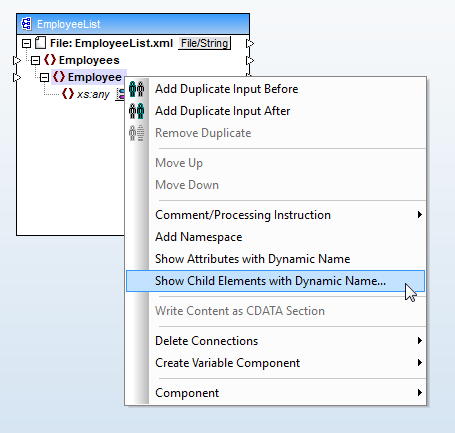
Wir wählen die Option "Kindelemente mit dynamischem Namen anzeigen", wodurch ein Dialogfenster geöffnet wird, in dem wir den Datentyp für die Kindelemente als Text auswählen. Dadurch werden der Knotenname und der Inhalt der Kindelemente von
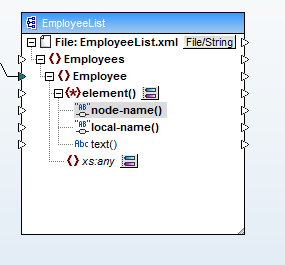
Jetzt ist es ein einfacher Prozess, die Daten aus Feld 1 (Spalte A der CSV-Datei) den Namen der Kindelemente zuzuordnen und die Daten aus Feld 2 (Spalte B) dem Inhalt der Elemente. Hier ist die endgültige Datenzuordnung:
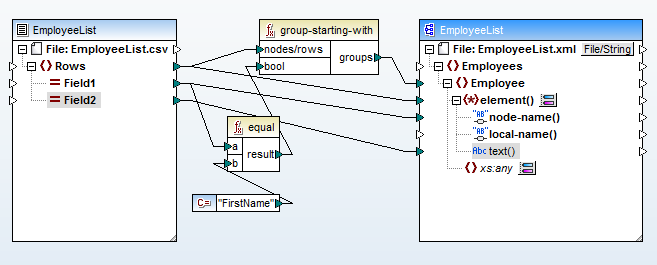
Die Funktion "group-starting-with" am Anfang erstellt jedes Mal ein neues
Die Ausgabe der oben genannten Zuordnung sieht wie folgt aus:
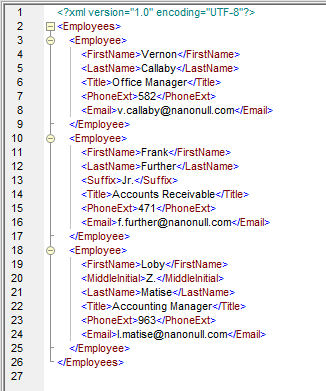
Der Vorteil einer Datenzuordnung, die dynamischen Zugriff auf die Namen der Knoten verwendet, besteht darin, dass Sie keine umfassende Analyse der Eingabedaten durchführen müssen, um jeden möglichen Elementnamen zu identifizieren und zuzuordnen.
Stellen Sie sich ein typisches Produktionsszenario vor, in dem Sie mehrere Eingabedateien von einer oder mehreren externen Quellen empfangen und die Ausführung von Mapping-Prozessen mit MapForce Server und FlowForce Server automatisieren. Wenn eine Eingabedatei plötzlich ein unerwartetes Unterelement enthält – beispielsweise "OfficeLocation" oder "MailStop" – gehen die Daten nicht verloren.
Dynamischer Zugriff auf die Namen von XML-Attributen
Sie können auch die Namen von XML-Attributen dynamisch zuordnen, wobei Sie die gleiche Möglichkeit haben, Ziel-Elemente und -Attribute zur Laufzeit zu erstellen, ohne diese notwendigerweise im Voraus definieren zu müssen.