Erfahren Sie mehr über Inline-XBRL und XBRL-Taxonomie-Pakete
Mit der weltweit zunehmenden Verbreitung der Sprache für elektronische Geschäftsberichte (XBRL) für die Finanzberichterstattung entstehen neue Standards, um den Bedürfnissen sowohl der Unternehmen, die Berichte einreichen, als auch der Entwickler gerecht zu werden. Die Produktpalette von Altova, die XBRL-fähig ist, unterstützt eine Vielzahl von XBRL-Standards und wird regelmäßig aktualisiert, sobald neue Spezifikationen verfügbar sind.
Schauen wir uns nun zwei der neueren XBRL-Standards – Inline XBRL und XBRL-Taxonomie-Pakete – genauer an und untersuchen, wie sie funktionieren.

Inline XBRL (iXBRL)
Die Inline XBRL-Spezifikation von XBRL International erweitert XBRL mit dem Ziel, die Effizienz zu steigern, indem sie es Unternehmen ermöglicht, ihre XBRL-Daten direkt in ein HTML-Dokument einzubetten, anstatt die XBRL-Daten vollständig von dem entsprechenden, für Menschen lesbaren Bericht zu trennen. Dies bietet zusätzliche Flexibilität und kombiniert die Vorteile von strukturierten Daten mit einer benutzerfreundlichen Darstellung eines Berichts: Menschen können die Informationen einfach durch Betrachten im Webbrowser verstehen, und Software kann den Bericht für automatisierte Analysen nutzen.
Mit Inline XBRL können Unternehmen die XBRL-Daten auf standardisierte Weise in das HTML einbetten. Dadurch lassen sich die Daten bei Bedarf einfach in ein XBRL-Dokument extrahiert werden, und anschließend kann ein einziges Dokument eingereicht werden, um die Finanzinformationen zu übermitteln.
Für Organisationen, die diese Spezifikation verwenden, unterstützt XMLSpy (Version 2017 oder höher) die Validierung von Inline-XBRL-Dateien.
Da die in einem iXBRL-Dokument enthaltenen Daten weiterhin in ein XBRL-Instanzdokument extrahiert werden müssen, um weiterverarbeitet zu werden, bietet XMLSpy diese Funktionalität mit dem Befehl "Transform Inline XBRL".
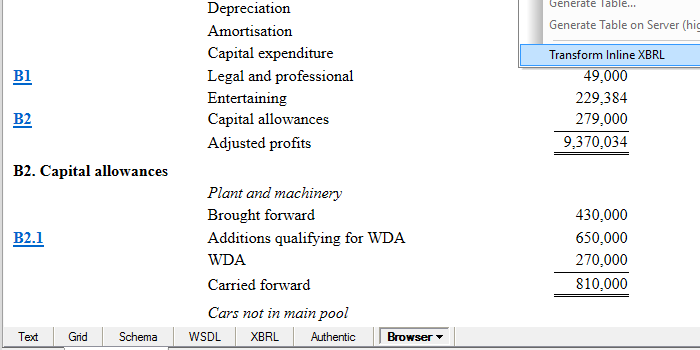
Diese Funktion extrahiert die Inline-XBRL-Daten aus dem aktuellen HTML-Bericht und generiert ein oder mehrere XBRL-Dokumente, die die extrahierten Daten enthalten. Die generierten XBRL-Dokumente werden in neuen Fenstern geöffnet und können gespeichert, bearbeitet usw. werden.
iXBRL-Datenabbildung
Unterstützung für die Spezifikation ist auch während der Zuordnung von XBRL-Daten in MapForce verfügbar, wo Dateien, die Inline-XBRL enthalten, als Quelldaten für die Zuordnung zu relationalen Datenbanken oder anderen Datenformaten hinzugefügt werden können.
Erstellung von Inline-XBRL-Berichten
Für Organisationen, die mit iXBRL arbeiten, ermöglicht StyleVision die einfache Gestaltung und Erstellung des HTML-Berichts. Der von StyleVision verwendete, intuitive Berichtsentwurfsprozess mit Drag-and-Drop-Funktion ermöglicht es Kunden, schnell und einfach einen ansprechenden, für Menschen lesbaren iXBRL-Bericht zu erstellen.

Hochleistungsfähige Validierung von iXBRL-Daten
Schließlich erweitert Inline XBRL die lange Liste der XBRL-Spezifikationen, die mit dem RaptorXML+XBRL Server für schnelle und umfangreiche Aufgaben validiert werden können. Im ersten Schritt der Validierung wandelt die Ausführung eines Befehls den Bericht in das XBRL-Format um, indem das Inline XBRL extrahiert und das erstellte XBRL-Dokument anhand der relevanten XBRL-Taxonomie validiert wird. Das erstellte XBRL-Dokument kann optional gespeichert werden.
XBRL-Taxonomiepakete
XBRL-Taxonomien bestehen in der Regel aus zahlreichen miteinander verbundenen Dokumenten, die oft aus Gründen der Benutzerfreundlichkeit in einer ZIP-Datei zusammengefasst sind. Eine neue XBRL-Spezifikation namens "XBRL-Taxonomie-Pakete" wurde entwickelt, um die Arbeit mit diesen Dokumenten zu vereinfachen.
Das XBRL-Taxonomie-Paket definiert ein Standardformat und einen Speicherort für eine Datei innerhalb des ZIP-Archivs, die eine Beschreibung des Pakets sowie den Einstiegspunkt enthält. Das Taxonomie-Paket enthält außerdem eine Katalog-XML-Datei, die URIs auf die Dateipfade der Offline-Taxonomie abbildet. Dadurch ist die Taxonomie für Anwendungen ohne zusätzliche Konfiguration durch menschliche Benutzer offline verfügbar.
Wir haben bereits zahlreiche Kunden, die XBRL-Taxonomie-Pakete nutzen. Ab Version 2017 unterstützen sowohl XMLSpy als auch RaptorXML+XBRL Server die Validierung ihres Inhalts.
Nachdem Sie ein Taxonomie-Paket heruntergeladen haben, können Sie es in XMLSpy registrieren, um die zugehörige Katalogdatei des Pakets automatisch zu erkennen und zu verwenden. Die Katalogdateien der aktivierten Pakete werden dann verwendet, um Ressourcen zu finden, Validierungen durchzuführen und andere Operationen auszuführen.
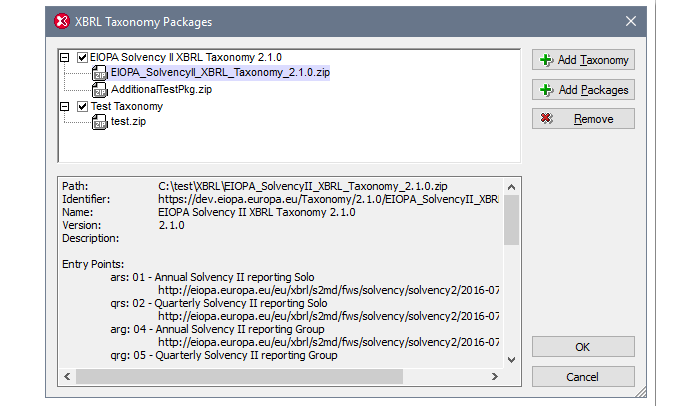
Sobald die Taxonomie-Pakete hinzugefügt wurden, stehen sie allen Altova-Produkten zur Verfügung, die die XBRL-Technologie unterstützen, auf dem Computer des Entwicklers (z. B. MapForce, StyleVision usw.).
Mit der Entwicklung neuer XBRL-Standards werden diese in die umfassende Unterstützung durch die Altova-Tools integriert, um die Bearbeitung, Erstellung, Konvertierung, Darstellung und Validierung von XBRL-Daten zu ermöglichen und damit den vielfältigen Anforderungen von Unternehmen und Aufsichtsbehörden gerecht zu werden.
Erfahren Sie mehr über die Altova XBRL-Tools und laden Sie jederzeit eine kostenlose Testversion herunter.