Wyszukiwanie tekstowe umożliwiające precyzyjne wydobywanie danych z plików PDF
Pliki PDF są wykorzystywane na wielu etapach nowoczesnych procesów biznesowych, często stanowiąc preferowany format dla faktur, raportów, umów prawnych oraz innych ważnych dokumentów. Chociaż pliki PDF są idealne do zachowania integralności treści i określonego układu wizualnego, ich struktura utrudnia automatyczne wyodrębnianie danych. Dla organizacji zajmujących się integracją danych i procesami ETL, dostęp do informacji zawartych w plikach PDF jest niezbędny – i właśnie tutaj wkracza narzędzie MapForce PDF Extractor.
Program MapForce PDF Extractor zawiera szereg narzędzi umożliwiających wizualne definiowanie reguł ekstrakcji danych z plików PDF i przekształcanie ich do innych formatów. Jednym z narzędzi szczególnie przydatnych do precyzyjnego wyodrębniania konkretnych fragmentów jest funkcja wyszukiwania tekstu. Poniżej opis działania tej funkcji, wraz z demonstracją wideo.

Dostęp do danych PDF do celów ETL
Chociaż pliki PDF często zawierają ważne dane, nie zostały one pierwotnie zaprojektowane do przetwarzania danych. W przeciwieństwie do formatów strukturalnych, takich jak XML lub JSON, pliki PDF priorytetowo traktują prezentację nad dostępnością zawartości.
Może to prowadzić do wąskich gardeł, zmuszając organizacje do korzystania z czasochłonnych, ręcznych procesów, aby uzyskać potrzebne dane z plików PDF. Automatyzacja ekstrakcji danych eliminuje ręczne wprowadzanie danych, redukując ryzyko błędów ludzkich, jednocześnie uwalniając zasoby do realizacji zadań o większej wartości.
Program MapForce PDF Extractor ułatwia to zadanie, oferując prosty sposób na zdefiniowanie struktury dokumentu PDF, aby móc automatycznie wyodrębnić z niego dane. Podczas definiowania reguł wyodrębniania, program tworzy model drzewiastą, który reprezentuje strukturę danych. Dzięki temu, wyodrębnione dane można przekształcić do innych formatów, takich jak bazy danych, JSON i XML, w programie MapForce.
Dzięki wykorzystaniu narzędzi wizualnych oraz funkcji przeciągania i upuszczania, można wyodrębnić tylko fragmenty treści, łączyć elementy z różnych stron, dzielić tabele na wiersze, grupować treści i wiele więcej. Oprócz możliwości ręcznego dodawania sekcji dokumentu do szablonu za pomocą kliknięć, MapForce zawiera mechanizm rekomendacji, który identyfikuje tabele, umożliwiając ich automatyczne wyodrębnianie. Następnie Zasady ekstrakcji danych z plików PDF Można go dodatkowo udoskonalić w razie potrzeby.
W plikach PDF zawierających wiele tabel, może być pomocne zdefiniowanie reguł ekstrakcji danych za pomocą wyszukiwania tekstowego.
Wyszukaj tekst, aby wyodrębnić dane z pliku PDF
Program MapForce PDF Extractor oferuje możliwość wyszukiwania tekstu w dokumencie zarówno w interfejsie użytkownika, jak i podczas działania programu.
Jest to szczególnie przydatne w przypadku dużych dokumentów PDF zawierających liczne tabele, gdzie może być konieczne wyodrębnienie tylko niektórych danych, lub gdy trzeba zdefiniować reguły dla powtarzających się elementów. Na przykład, tworząc szablon do wyodrębniania danych z rocznych raportów finansowych, można wyszukać frazę „Wydatki” i przetworzyć tabelę zawierającą dane, która występuje po tym tekście.
Zaawansowane opcje wyszukiwania, takie jak uwzględnianie wielkości liter, filtrowanie według formatu (czcionka, grubość czcionki itp.) oraz wyszukiwanie całych lub fragmentów słów, umożliwiają precyzyjne doprecyzowanie wyników.
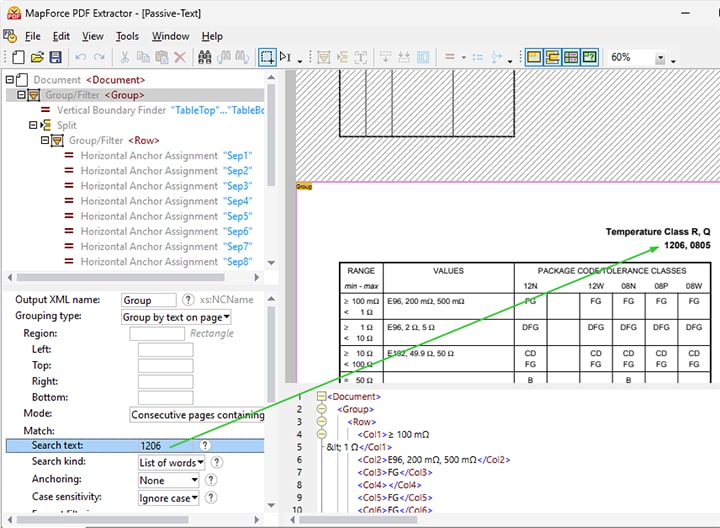
Funkcja wyszukiwania umożliwia zdefiniowanie reguł przetwarzania danych w odniesieniu do słowa kluczowego użytego w wyszukiwaniu. Obejmują one:
Podziel obszar na podstawie słowa kluczowego (np. "numer artykułu" w filmie demonstracyjnym poniżej)
Grupuj dane na podstawie tekstu występującego na stronie (np. "szczegóły artykułu" w filmie)
Możliwość precyzyjnego wyszukiwania i wyodrębniania tylko istotnych tabel i fragmentów tekstu, oparta na wyszukiwaniu tekstowym, usprawnia tworzenie szablonów, oszczędzając czas i zwiększając dokładność.
Oto demonstracja funkcji wyszukiwania tekstu w programie MapForce PDF Extractor. W tym poradniku dowiesz się, jak wykorzystać wyszukiwanie tekstu do tworzenia szablonu, który mapuje dane z plików PDF do formatu JSON, co jest częstym wymaganiem w procesach integracji danych i ETL.
Po zdefiniowaniu szablonu ekstrakcji danych PDF, można go dodać do programu MapForce projekt mapowania danych aby przekonwertować go do innego formatu lub przetworzyć go w celu przechowywania w bazie danych.
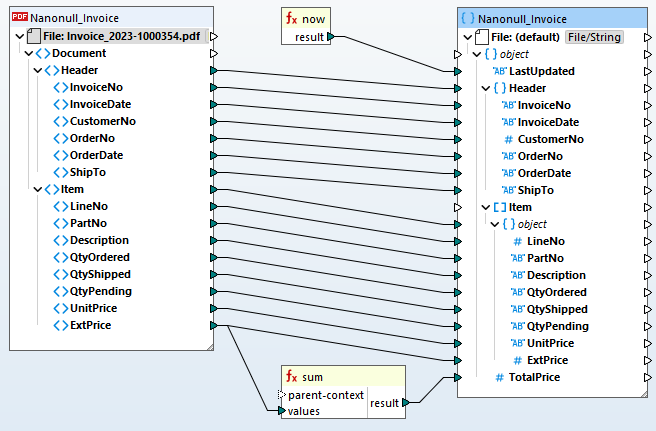
Do automatyzacji procesów ETL dla plików PDF, MapForce Server obsługuje reguły ekstrakcji danych z plików PDF, które są zdefiniowane w programie MapForce.
Wypróbuj to samodzielnie, korzystając z bezpłatnej 30-dniowej wersji próbnej proces dotyczące MapForce.