PDFファイルから正確なデータを抽出するためのテキスト検索機能
現代のビジネスワークフローにおいて、PDFドキュメントは多くの段階で使用されており、請求書、レポート、法的契約書、その他の重要な文書の形式として頻繁に利用されています。PDFはコンテンツの正確性と特定の視覚的なレイアウトを維持するのに理想的ですが、その構造上、自動的なデータ抽出は困難です。データ統合やETL(抽出、変換、ロード)に取り組む企業にとって、PDFに含まれる情報を活用することは不可欠であり、そこでMapForce PDF Extractorが役立ちます。
MapForce PDFエクストラクターには、PDFデータから特定の情報を抽出し、他の形式に変換するための様々なツールが搭載されています。その中でも、特に特定のコンテンツをピンポイントで抽出するのに役立つのが、テキスト検索機能です。以下に、その機能の使い方を動画デモとともにご紹介します。

ETL 処理のための PDF データへのアクセス
PDFファイルは、重要なデータが含まれていることがよくありますが、本来、データ処理のために設計されたものではありません。XMLやJSONのような構造化された形式とは異なり、PDFはコンテンツのアクセシビリティよりも、表示を重視しています。
これにより、データ取得がボトルネックとなり、組織は必要なデータをPDFから得るために、時間のかかる手作業に頼らざるを得なくなることがあります。データ抽出の自動化は、手作業によるデータ入力の必要性をなくし、人的ミスを減らすとともに、より重要な業務にリソースを集中させることができます。
MapForce PDF抽出ツールは、この作業を容易にします。このツールは、PDFドキュメントからデータを自動的に抽出するために、ドキュメントの構造を定義する簡単な方法を提供します。抽出ルールを定義すると、このツールはデータの構造を表すツリーモデルを構築します。このモデルを利用することで、抽出されたデータを、MapForce上でデータベース、JSON、XMLなどの他の形式に変換することができます。
視覚的なツールやドラッグ&ドロップ機能を使用することで、コンテンツの一部だけを抽出したり、異なるページからコンテンツを組み合わせて使用したり、テーブルを行ごとに分割したり、コンテンツをグループ化したりすることができます。 また、手動でドキュメントのセクションをテンプレートに追加する機能に加えて、MapForceには、テーブルを自動的に抽出できるように識別する機能が搭載されています。 その後、必要に応じて、PDFデータ抽出ルールをさらに詳細に調整することができます。
多くの表が含まれるPDFファイルの場合、テキスト検索機能を使って抽出ルールを定義すると便利です。
テキストを検索して、PDFファイルからデータを抽出します
MapForce PDFエクストラクターには、インターフェース上だけでなく、実行時にもドキュメント内のテキストを検索する機能が備わっています。
これは、特に、多くの表が含まれる大規模なPDF文書において非常に役立ちます。例えば、データの一部だけを抽出したい場合や、繰り返し現れる要素に対してルールを定義したい場合に有効です。例えば、年次財務報告書からデータを抽出するためのテンプレートを作成する場合、"支出"というキーワードを検索し、そのテキストに続く数値表を適切に処理することができます。
詳細な検索オプション(大文字・小文字の区別、書式によるフィルタリング(フォント、フォントの太さなど)、完全一致または部分一致の検索など)を利用することで、より正確な検索が可能です。
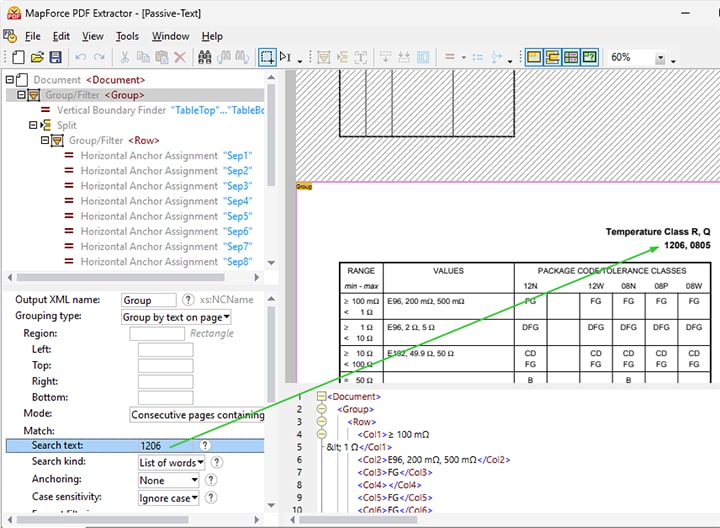
検索機能を使用すると、検索キーワードに関連するデータの処理方法を定義するルールを設定できます。そのルールには、以下のようなものが含まれます
特定の検索キーワードに基づいて、領域を分割します(例:以下のデモ動画では「記事番号」)
ページ上に表示されているテキストに基づいてデータを分類します(例:動画内の「記事詳細」)
テキスト検索に基づいて、関連するテーブルやデータのみを特定し抽出する機能は、テンプレート作成を効率化し、作業時間を短縮するとともに、精度を高めます。
ここでは、MapForce PDF Extractorのテキスト検索機能が実際にどのように動作するかをご紹介します。このチュートリアルでは、データ統合やETLプロセスでよく必要となる、PDFデータをJSON形式に変換するためのテンプレートを作成する際に、テキスト検索をどのように活用するかを学びます。
PDF抽出テンプレートを定義したら、それをMapForceに追加することができます データマッピングプロジェクト それを別の形式に変換したり、データベースに保存するために処理したりすることができます。
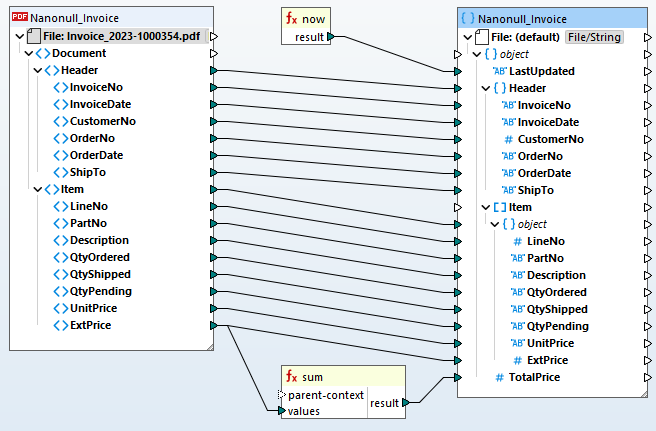
PDFデータのETLパイプラインを自動化するために、MapForce Serverは、MapForceで定義されたPDFデータ抽出ルールをサポートしています。
無料で30日間お試しいただけます。ぜひご自身で体験してみてください 試験 MapForceに関する情報です。