Pesquisa por texto para extração precisa de dados em documentos PDF
Os documentos PDF são utilizados em várias etapas dos fluxos de trabalho empresariais modernos, servindo frequentemente como o formato preferencial para faturas, relatórios, contratos legais e outros documentos importantes. Embora os PDFs sejam ideais para preservar a integridade do conteúdo e um determinado layout visual, a sua estrutura dificulta a extração automatizada de dados. Para organizações envolvidas na integração de dados e no processo ETL (Extração, Transformação e Carga), a capacidade de extrair informações contidas em PDFs é fundamental, e é aqui que o MapForce PDF Extractor entra em jogo.
O extrator PDF do MapForce inclui várias ferramentas para definir visualmente regras de extração, permitindo mapear dados PDF para outros formatos. Uma ferramenta particularmente útil para identificar conteúdo específico é a pesquisa de texto. Veja como funciona, incluindo uma demonstração em vídeo.

Aceder aos dados em formato PDF para ETL
Embora os documentos PDF contenham frequentemente dados importantes, eles não foram concebidos, em si, para o processamento de dados. Ao contrário de formatos estruturados como XML ou JSON, os PDFs priorizam a apresentação em vez da acessibilidade do conteúdo.
Isto pode criar gargalos, obrigando as organizações a recorrer a processos manuais demorados para obter os dados de que necessitam a partir de documentos PDF. A automatização da extração de dados elimina a introdução manual de dados, reduzindo os erros humanos e libertando recursos para tarefas de maior valor.
O MapForce PDF Extractor facilita esta tarefa, oferecendo uma forma simples de definir a estrutura de um documento PDF para extrair dados de forma automatizada. À medida que define as regras de extração, a ferramenta cria um modelo de árvore que representa a estrutura dos dados. Com base neste modelo, os dados extraídos podem ser convertidos para outros formatos, como bases de dados, JSON e XML, no MapForce.
Utilizando ferramentas visuais e a funcionalidade de arrastar e soltar, pode extrair apenas partes do conteúdo, combinar elementos de diferentes páginas, dividir tabelas em linhas, agrupar conteúdos e muito mais. Além da funcionalidade de clicar e selecionar para adicionar manualmente secções do documento ao seu modelo, o MapForce inclui um motor de sugestões que identifica tabelas para que possam ser extraídas automaticamente. Em seguida, as regras de extração de dados PDF podem ser refinadas, se necessário.
Em documentos PDF que contenham muitas tabelas, pode ser útil definir regras de extração utilizando uma pesquisa de texto.
Pesquisar texto para extrair dados de documentos PDF
O extrator PDF do MapForce inclui a opção de pesquisar texto num documento, tanto na interface do programa como durante a sua execução.
Isto é particularmente útil em documentos PDF extensos com inúmeras tabelas, onde pode ser necessário extrair apenas alguns dados, ou quando é preciso definir regras para elementos recorrentes. Por exemplo, ao criar um modelo para extrair dados de relatórios financeiros anuais, pode procurar por "Despesas" e processar a tabela de números que se encontra após esse texto, de acordo.
Opções de pesquisa detalhadas, como a distinção entre maiúsculas e minúsculas, a filtragem por formato (tipo de letra, espessura da letra, etc.) e a pesquisa por palavras inteiras ou parciais, permitem uma pesquisa precisa e direcionada.
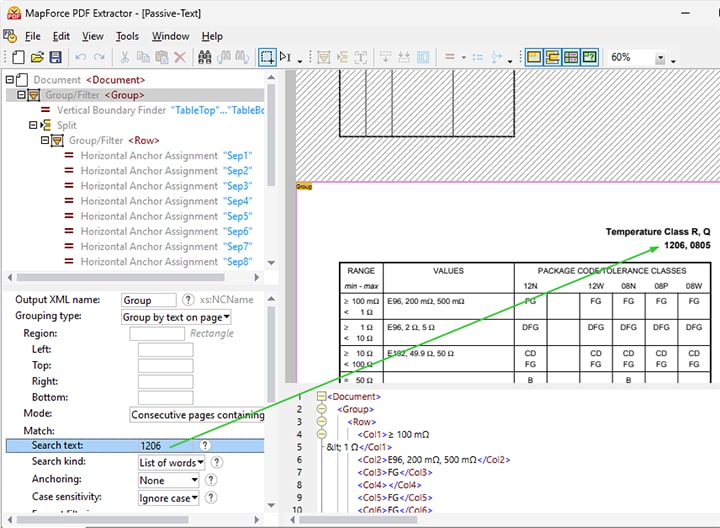
A funcionalidade de pesquisa permite definir regras para o processamento de dados em relação ao termo de pesquisa. Estas incluem:
Divida uma região com base num termo de pesquisa (por exemplo, "número do artigo" no vídeo de demonstração abaixo)
Agrupar os dados com base no texto que é encontrado numa página (por exemplo, "detalhes do artigo" no vídeo)
A capacidade de identificar e extrair apenas as tabelas e fragmentos de texto relevantes, com base numa pesquisa textual, simplifica a criação de modelos, poupando tempo e aumentando a precisão.
Aqui está uma demonstração da funcionalidade de pesquisa de texto do MapForce PDF Extractor em ação. Neste tutorial, irá aprender a utilizar a pesquisa de texto para criar um modelo que mapeie dados PDF para JSON, uma necessidade comum em processos de integração de dados e ETL.
Depois de definir o modelo de extração de PDF, pode adicioná-lo ao MapForce projeto de mapeamento de dados para o converter para outro formato ou processá-lo para armazenamento numa base de dados.
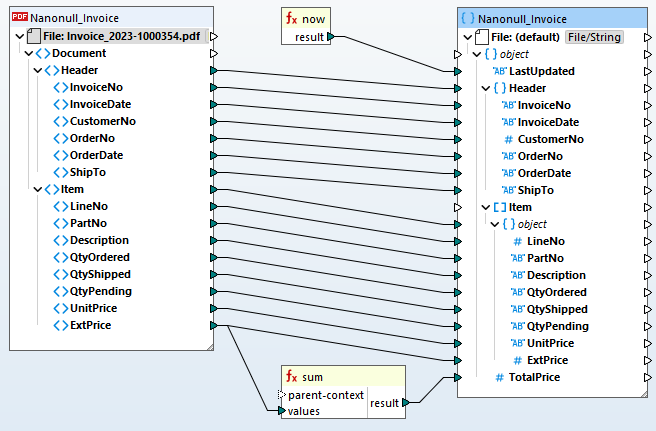
Para automatizar pipelines de ETL de documentos PDF, o MapForce Server suporta regras de extração de PDF definidas no MapForce.
Experimente por si mesmo com um período de teste gratuito de 30 dias ensaio da MapForce.