Ricerca testuale per l'estrazione precisa di dati dai file PDF
I documenti PDF sono utilizzati in molte fasi dei moderni processi aziendali, spesso fungendo da formato preferito per fatture, report, contratti legali e altri documenti importanti. Sebbene i PDF siano ideali per preservare l'integrità del contenuto e una specifica impaginazione, la loro struttura rende difficile l'estrazione automatica dei dati. Per le aziende che si occupano di integrazione dei dati e di processi ETL, l'estrazione delle informazioni contenute nei PDF è una necessità, ed è qui che entra in gioco il MapForce PDF Extractor.
L'estratto PDF di MapForce include diversi strumenti per definire visivamente le regole di estrazione, al fine di convertire i dati PDF in altri formati. Uno strumento particolarmente utile per individuare contenuti specifici è la ricerca testuale. Ecco come funziona, con una dimostrazione video.

Accesso ai dati PDF per l'ETL
Sebbene i file PDF spesso contengano dati importanti, non sono progettati intrinsecamente per l'elaborazione dei dati. A differenza dei formati strutturati come XML o JSON, i PDF danno priorità alla presentazione rispetto all'accessibilità dei contenuti.
Questo può creare dei colli di bottiglia, costringendo le aziende a ricorrere a processi manuali che richiedono molto tempo per estrarre i dati necessari dai file PDF. L'automazione dell'estrazione dei dati elimina l'inserimento manuale dei dati, riducendo gli errori umani e liberando risorse per attività di maggiore valore.
Il MapForce PDF Extractor semplifica questo processo, offrendo un modo semplice per definire la struttura di un documento PDF al fine di estrarre i dati in modo automatizzato. Man mano che si definiscono le regole di estrazione, l'applicazione crea un modello ad albero che rappresenta la struttura dei dati. Utilizzando questo modello, i dati estratti possono essere convertiti in altri formati, come database, JSON e XML, all'interno di MapForce.
Utilizzando strumenti visivi e la funzionalità di trascinamento, è possibile estrarre solo porzioni del contenuto, combinare elementi di contenuto provenienti da pagine diverse, suddividere tabelle in righe, raggruppare contenuti e molto altro. Oltre alla possibilità di aggiungere manualmente sezioni del documento al modello tramite semplici clic, MapForce include un sistema di suggerimenti che identifica le tabelle, consentendo di estrarle automaticamente. Successivamente, le regole di estrazione dei dati PDF possono essere ulteriormente perfezionate, se necessario.
Nei file PDF che contengono molte tabelle, può essere utile definire regole di estrazione utilizzando una ricerca testuale.
Cerca il testo per estrarre i dati dal file PDF
L'estrazione PDF di MapForce include la possibilità di cercare testo all'interno di un documento, sia nell'interfaccia utente che durante l'esecuzione del programma.
Questo strumento è particolarmente utile in documenti PDF di grandi dimensioni, contenenti numerose tabelle, quando è necessario estrarre solo una parte dei dati, oppure quando si devono definire regole per elementi ricorrenti. Ad esempio, quando si crea un modello per estrarre dati da bilanci annuali, si potrebbe cercare la parola "Spese" e, di conseguenza, elaborare la tabella dei dati che segue quel testo.
Opzioni di ricerca granulari, come la distinzione tra maiuscole e minuscole, il filtraggio per formato (tipo di carattere, spessore del carattere, ecc.) e la ricerca di parole intere o parziali, consentono di effettuare ricerche molto precise.
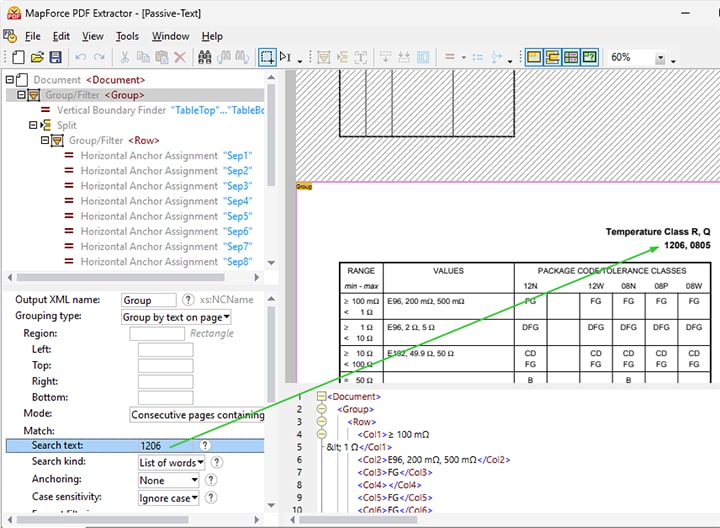
La funzione di ricerca consente di definire regole per l'elaborazione dei dati relativi al termine di ricerca. Queste includono:
Dividere una regione in base a un termine di ricerca (ad esempio, "numero dell'articolo" nel video dimostrativo qui sotto)
Raggruppare i dati in base al testo presente in una pagina (ad esempio, "dettagli dell'articolo" nel video)
La capacità di individuare e estrarre solo le tabelle e i frammenti di testo pertinenti, in base a una ricerca testuale, semplifica la creazione di modelli, risparmiando tempo e aumentando la precisione.
Ecco una dimostrazione pratica della funzionalità di ricerca testuale del MapForce PDF Extractor. In questo tutorial, imparerete a utilizzare la ricerca testuale per creare un modello che permetta di convertire i dati PDF in formato JSON, una necessità comune nei processi di integrazione dati e ETL.
Una volta definito il modello di estrazione PDF, è possibile aggiungerlo a un progetto MapForce progetto di mappatura dei dati per convertirlo in un altro formato o per elaborarlo al fine di archiviarlo in un database.
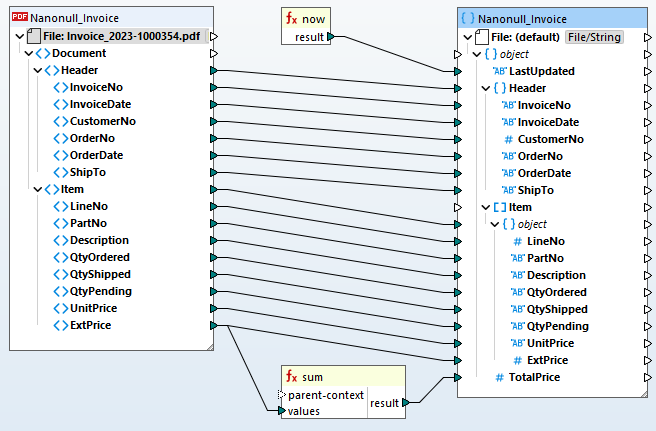
Per automatizzare i processi ETL (estrazione, trasformazione e caricamento) dei file PDF, MapForce Server supporta le regole di estrazione dei PDF definite in MapForce.
Provatelo di persona con una prova gratuita di 30 giorni prova di MapForce.