Búsqueda por texto para una extracción precisa de datos de archivos PDF
Los documentos PDF se utilizan en muchas etapas de los flujos de trabajo empresariales modernos, y a menudo sirven como el formato preferido para facturas, informes, contratos legales y otros documentos importantes. Si bien los PDF son ideales para preservar la integridad del contenido y un diseño visual específico, su estructura dificulta la extracción automatizada de datos. Para las organizaciones que participan en la integración de datos y en procesos ETL, la posibilidad de acceder a la información contenida en los PDF es fundamental, y es aquí donde entra en juego el extractor de PDF de MapForce.
El extractor de PDF de MapForce incluye múltiples herramientas para definir visualmente las reglas de extracción y así convertir los datos de PDF a otros formatos. Una de las herramientas especialmente útil para identificar contenido específico es la búsqueda de texto. A continuación, se explica cómo funciona, incluyendo una demostración en video.

Acceder a los datos en formato PDF para procesos de ETL
Aunque los archivos PDF a menudo contienen datos importantes, no están diseñados intrínsecamente para el procesamiento de datos. A diferencia de formatos estructurados como XML o JSON, los archivos PDF priorizan la presentación visual sobre la accesibilidad del contenido.
Esto puede generar cuellos de botella, obligando a las organizaciones a depender de procesos manuales que consumen mucho tiempo para obtener los datos que necesitan de los archivos PDF. La automatización de la extracción de datos elimina la introducción manual de datos, reduciendo los errores humanos y liberando recursos para tareas de mayor valor.
El Extractor de PDF de MapForce facilita esta tarea, ofreciendo una forma sencilla de definir la estructura de un documento PDF para extraer datos de él de manera automatizada. A medida que se definen las reglas de extracción, la herramienta crea un modelo de árbol que representa la estructura de los datos. Utilizando este modelo, los datos extraídos pueden ser transformados a otros formatos, como bases de datos, JSON y XML, dentro de MapForce.
Utilizando herramientas visuales y la función de arrastrar y soltar, puede extraer solo partes del contenido, combinar elementos de diferentes páginas, dividir tablas en filas, agrupar contenido, y mucho más. Además de la función de "punto y clic" para agregar secciones de documentos a su plantilla de forma manual, MapForce incluye un motor de sugerencias que identifica tablas para que puedan extraerse automáticamente. Posteriormente, las reglas de extracción de datos PDF pueden refinarse aún más según sea necesario.
En los archivos PDF que contienen muchas tablas, puede ser útil definir reglas de extracción utilizando una búsqueda de texto.
Buscar texto para extraer datos de archivos PDF
El extractor de PDF de MapForce incluye la opción de buscar texto dentro de un documento, tanto en la interfaz de usuario como durante la ejecución del programa.
Esto es especialmente útil en documentos PDF extensos que contienen numerosas tablas, donde quizás solo necesite extraer parte de los datos, o cuando necesita definir reglas para elementos recurrentes. Por ejemplo, al crear una plantilla para extraer datos de informes financieros anuales, podría buscar la palabra "Gastos" y procesar la tabla de cifras que siga a ese texto de la manera adecuada.
Las opciones de búsqueda detalladas, como la distinción entre mayúsculas y minúsculas, el filtrado por formato (tipo de fuente, grosor, etc.) y las búsquedas de palabras completas o parciales, permiten una selección precisa.
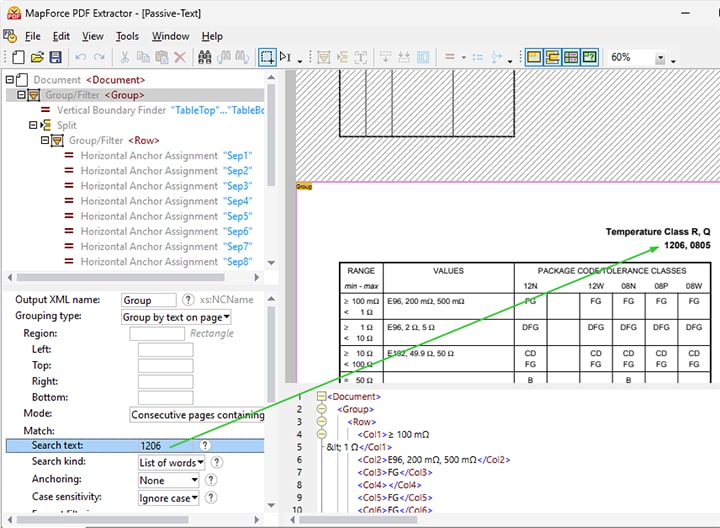
La función de búsqueda permite definir reglas para el procesamiento de datos en relación con el término de búsqueda. Estas incluyen:
Divida una región basándose en un término de búsqueda (por ejemplo, "número de artículo" en el vídeo de demostración que se muestra a continuación)
Agrupar los datos según el texto que se encuentra en una página (por ejemplo, "detalles del artículo" en el video)
La capacidad de identificar y extraer únicamente las tablas y fragmentos de texto relevantes mediante una búsqueda textual agiliza la creación de plantillas, ahorrando tiempo y aumentando la precisión.
Aquí se muestra el funcionamiento de la función de búsqueda de texto del extractor de PDF de MapForce. En este tutorial, aprenderá a utilizar la búsqueda de texto para crear una plantilla que permita convertir datos de PDF a formato JSON, una necesidad común en los procesos de integración de datos y ETL.
Una vez que haya definido su plantilla de extracción de PDF, puede agregarla a un MapForce proyecto de mapeo de datos para convertirlo a otro formato o procesarlo para almacenarlo en una base de datos.
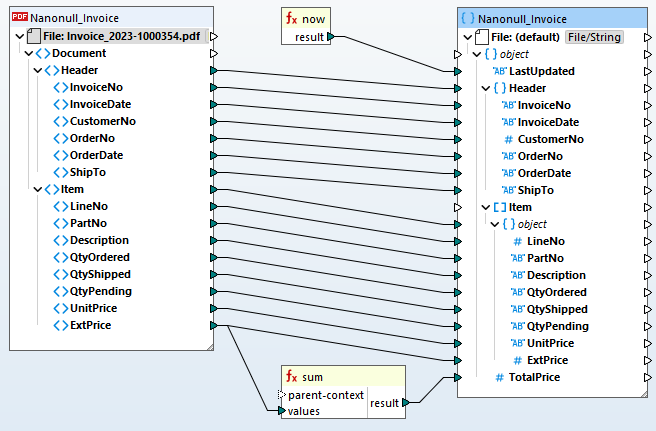
Para automatizar los procesos de extracción, transformación y carga (ETL) de archivos PDF, MapForce Server admite las reglas de extracción de PDF definidas en MapForce.
Pruébalo tú mismo con una versión gratuita de 30 días juicio de MapForce.