Tekst zoeken voor nauwkeurige data-extractie uit PDF-bestanden
PDF-documenten worden in veel verschillende fasen van moderne bedrijfsprocessen gebruikt, en dienen vaak als het standaardformaat voor facturen, rapporten, juridische contracten en andere belangrijke documenten. Hoewel PDF's ideaal zijn voor het behouden van de inhoud en een specifieke visuele lay-out, maakt hun structuur het moeilijk om data automatisch te extraheren. Voor organisaties die zich bezighouden met data-integratie en ETL (Extract, Transform, Load), is het essentieel om informatie uit PDF-bestanden te kunnen ontsluiten – en dat is waar de MapForce PDF Extractor van pas komt.
De MapForce PDF Extractor bevat verschillende tools waarmee u visueel extractieregels kunt definiëren om PDF-gegevens om te zetten naar andere formaten. Een bijzonder nuttige functie om specifieke inhoud te selecteren is de tekstzoekfunctie. Hieronder wordt uitgelegd hoe deze functie werkt, inclusief een video-demonstratie.

Toegang tot PDF-gegevens voor ETL-processen
Hoewel PDF-bestanden vaak cruciale gegevens bevatten, zijn ze niet primair ontworpen voor dataverwerking. In tegenstelling tot gestructureerde formaten zoals XML of JSON, leggen PDF-bestanden de nadruk op de presentatie in plaats van op de toegankelijkheid van de inhoud.
Dit kan knelpunten veroorzaken, waardoor organisaties gedwongen worden om tijdrovende handmatige processen te gebruiken om de benodigde gegevens uit PDF-bestanden te halen. Het automatiseren van data-extractie elimineert handmatige data-invoer, waardoor menselijke fouten worden verminderd en er resources vrijkomen voor taken met een hogere waarde.
De MapForce PDF Extractor maakt dit eenvoudig. Het biedt een eenvoudige manier om de structuur van een PDF-document te definiëren, zodat u data automatisch uit het document kunt halen. Tijdens het definiëren van de extractieregels bouwt de tool een boomstructuur op die de datastructuur weergeeft. Met behulp van deze structuur kan de geëxtraheerde data in MapForce worden omgezet naar andere formaten, zoals databases, JSON en XML.
Met behulp van visuele hulpmiddelen en een functie waarmee u elementen kunt slepen en neerzetten, kunt u specifieke delen van de inhoud selecteren, elementen van verschillende pagina's combineren, tabellen opsplitsen in rijen, inhoud groeperen en nog veel meer. Naast de mogelijkheid om documentsecties handmatig toe te voegen via klikken en selecteren, bevat MapForce een suggestie-engine die tabellen identificeert, zodat deze automatisch kunnen worden geëxtraheerd. Vervolgens Regels voor het extraheren van gegevens uit PDF-bestanden Kan indien nodig verder worden verfijnd.
In PDF-documenten met veel tabellen kan het handig zijn om extractieregels te definiëren met behulp van een tekstzoekfunctie.
Zoek naar tekst om gegevens uit PDF-bestanden te extraheren
De MapForce PDF-extractor biedt de mogelijkheid om tekst in een document te zoeken, zowel in de gebruikersinterface als tijdens de uitvoering.
Dit is vooral handig bij grote PDF-documenten met veel tabellen, waarbij u mogelijk slechts een deel van de gegevens wilt extraheren, of wanneer u regels wilt definiëren voor terugkerende elementen. Bijvoorbeeld, bij het maken van een sjabloon om gegevens te extraheren uit jaarlijkse financiële rapporten, kunt u zoeken naar "Uitgaven" en vervolgens de tabel met cijfers die daarop volgt, op de juiste manier verwerken.
Gedetailleerde zoekopties, zoals hoofdlettergevoeligheid, filteren op opmaak (lettertype, vetgedrukt, etc.) en zoeken naar volledige of gedeeltelijke woorden, maken het mogelijk om zeer specifiek te zoeken.
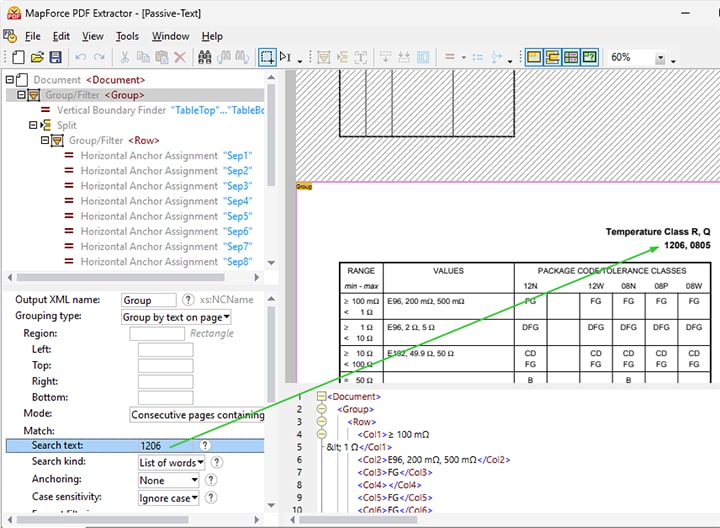
De zoekfunctionaliteit stelt u in staat om regels te definiëren voor het verwerken van gegevens in relatie tot het zoekwoord. Deze regels omvatten:
Verdeel een regio op basis van een zoekterm (bijvoorbeeld "artikelnummer" in de demonstratievideo hieronder)
Groepeer de gegevens op basis van tekst die op een pagina wordt gevonden (bijvoorbeeld "artikeldetails" in de video)
Het vermogen om relevante tabellen en fragmenten te identificeren en te extraheren op basis van een tekstzoekopdracht, vereenvoudigt het maken van templates, bespaart tijd en verhoogt de nauwkeurigheid.
Hieronder ziet u een demonstratie van de tekstzoekfunctionaliteit van de MapForce PDF Extractor. In deze tutorial leert u hoe u tekstzoekfunctionaliteit kunt gebruiken om een sjabloon te maken waarmee PDF-gegevens kunnen worden omgezet naar JSON, een veelvoorkomende vereiste in data-integratie- en ETL-processen.
Zodra uw PDF-extractie-sjabloon is gedefinieerd, kunt u deze toevoegen aan een MapForce project voor data-integratie om het om te zetten naar een ander formaat of om het te verwerken voor opslag in een database.
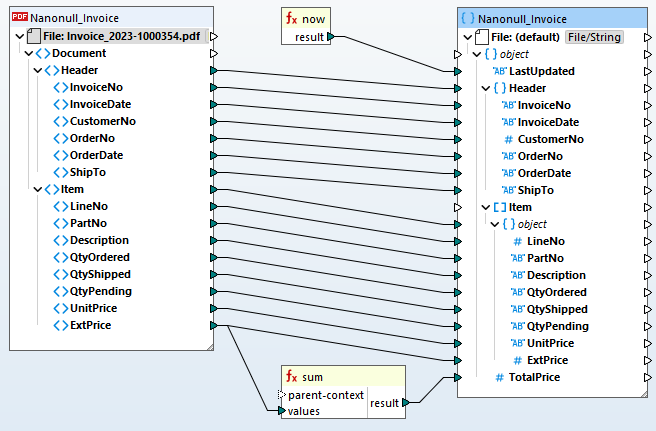
Voor het automatiseren van PDF-ETL-processen ondersteunt MapForce Server extractieregels voor PDF-bestanden die zijn gedefinieerd in MapForce.
Probeer het zelf met een gratis proefperiode van 30 dagen proces van MapForce.