在 MapForce 中,利用 OCR 技术处理扫描的 PDF 文件
对于许多组织来说,PDF文件既是重要的数据来源,也是ETL(提取、转换、加载)和数据集成流程中的一个持续障碍。虽然现代PDF文件通常包含可选择的文本,处理起来相对简单,但大量关键业务数据仍然被困在扫描文档中——这些包括数字化纸质档案、旧系统记录以及基于图像的文件,其中文本仅以像素的形式存在,而无法被机器识别。挑战在于将这些非结构化内容转化为可用数据。
MapForce PDF提取工具中的OCR(光学字符识别)功能解决了这一问题,它可以将基于图像的PDF文件中的内容转换为结构化、可提取的数据,从而为后续处理和转换为其他格式做好准备。

将扫描图像转换为结构化数据
拥有数十年纸质档案的机构面临着一个数字化技术本身无法完全解决的难题:扫描技术虽然可以保留文档的外观,但无法保留其中的数据,导致扫描生成的PDF文件仅仅是文本的图像,计算机无法对其进行搜索或处理。对于构建ETL数据管道的数据工程师来说,这意味着宝贵的历史信息虽然被“数字化”了,但仍然无法访问。许多重要的文档,例如手写表格、旧的财务报告、合规文件以及扫描的合同,都属于这一类,这迫使团队依赖手动、容易出错的数据录入,从而延缓了原本可以自动化的工作流程。
这就是为什么光学字符识别(OCR)是任何PDF数据集成项目的关键组成部分。
OCR技术将文本图像转换为应用程序可以处理的实际字符数据。在MapForce PDF Extractor中,OCR功能作为一种预处理步骤,将扫描的文档转换为与基于文本的PDF文件相同的结构化格式,从而实现对源文档的统一后续处理,无论其来源如何。
MapForce 的实现基于 Tesseract OCR,这是一款开源的识别引擎,以其卓越的准确性而闻名。该技术结合了传统的模式识别方法和现代的 LSTM(长短期记忆)神经网络方法。这种混合架构具有很强的灵活性,可以处理各种文档类型和布局,同时在多种语言(包括英语、德语、法语、日语和西班牙语)中保持高准确率。(MapForce 软件本身也提供这些语言的版本。)
拥有 MapForce PDF 提取器内置了光学字符识别 (OCR) 功能 这是一个重要的优势。与以往的做法不同,以往需要开发者使用外部工具进行OCR处理作为独立的预处理步骤,然后再导入结果,MapForce将OCR功能直接集成到PDF提取的工作流程中,从而节省了时间 和 实现自动化。
从光学字符识别到结构化数据提取
当然,识别文本只是解决方案的一部分。为了让扫描后的内容发挥实际作用,这些文本必须进行整理,以便进行进一步的处理。真正的价值在于,当这些文本转化为结构化数据,可以进行映射和转换时。
在 MapForce 中,当您对扫描的 PDF 文件进行光学字符识别 (OCR) 时,处理器会以对象树的形式显示检测到的内容。文档本身会以叠加的方式显示,展示 OCR 处理器如何在扫描区域检测到单词,并将识别出的单词以绿色突出显示。以红色突出显示的单词未被添加到对象树中,因为它们的置信度得分未达到处理器的阈值。您可以根据需要,使用简单易用的点选工具,手动编辑对象树以及绿色和红色标记的单词。
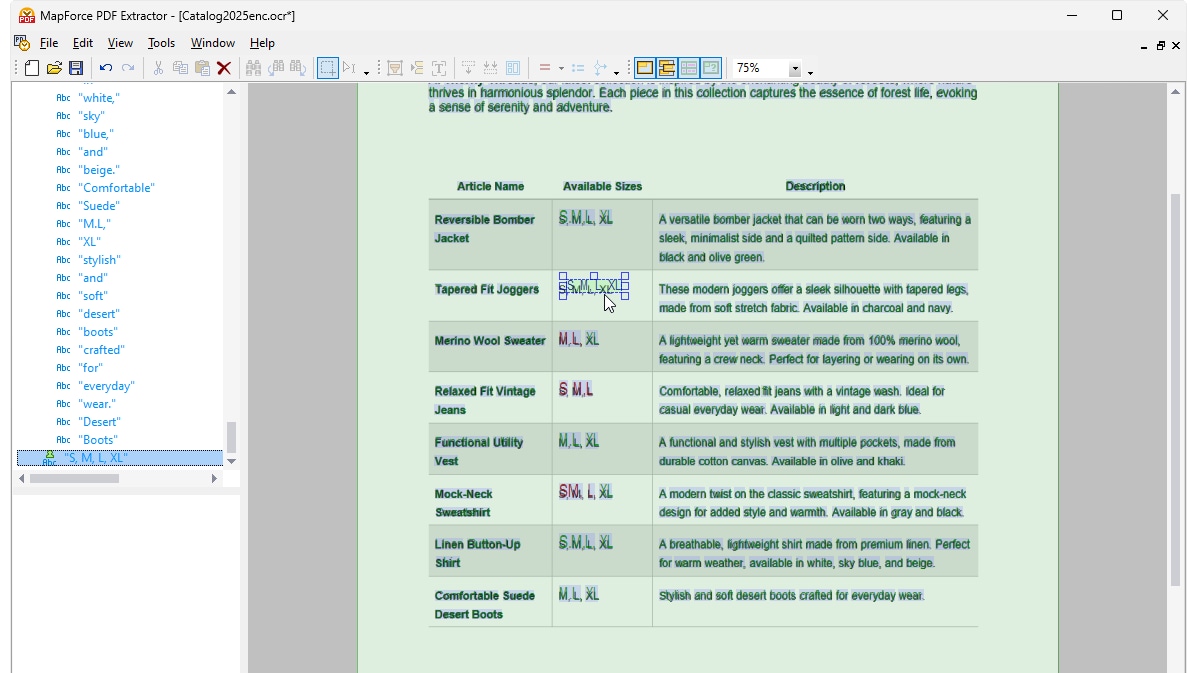
一旦您对OCR结果感到满意,则识别出的文本将被添加到MapForce PDF提取器的标准提取工作流程中。PDF提取器包含一个强大的建议引擎,该引擎可以自动识别常见文档元素,如表格和文本块,并尝试检测其结构。您可以根据需要对这些结构进行调整,例如将内容拆分为行/列,或者根据标题或关键词来设置提取规则等。您定义的模板反映了文档的结构,以便将其用于后续的映射操作。
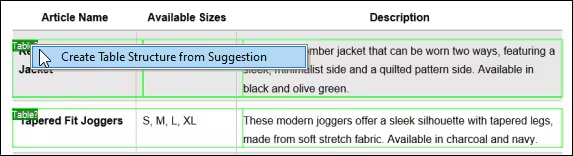
通过这种基于模板的设置,OCR 只在模板创建时运行一次。之后,MapForce 可以使用存储的提取规则来处理其他具有相同布局的文档,无需重复进行 OCR。这在需要处理大量标准化表格或报告的数据集成或 ETL 任务中,可以节省时间和资源。
提取的数据会形成一种可视化的映射结构,该结构代表PDF文档的内容。您可以将这种结构映射到任何支持的目标格式(例如数据库、JSON、Excel、XML、EDI、Shopify等)。这种可视化的映射方式使得定义转换变得简单,只需通过拖放操作即可在源数据结构和目标数据结构之间建立连接。同时,一个全面的函数库以及可视化函数构建器可以处理数据类型转换、过滤和条件逻辑。
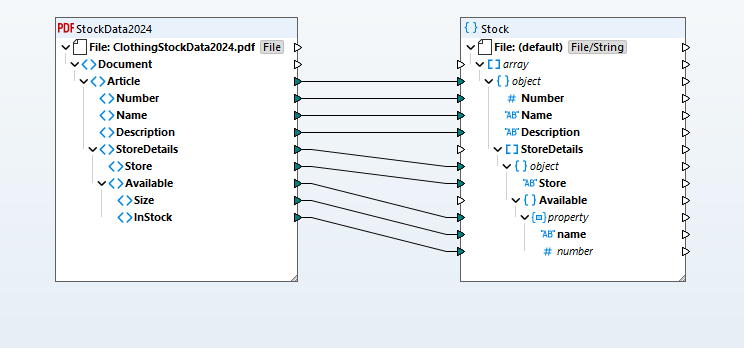
根据您定义的映射规则,MapForce 可以立即转换数据。或者,您可以使用 MapForce Server 高级版,以实现高性能的自动化处理。
尝试使用 PDF 提取工具中的 OCR 功能 MapForce 免费试用版 今天!