Déverrouiller les fichiers PDF numérisés grâce à la prise en charge de la reconnaissance optique de caractères (OCR) dans MapForce
Pour de nombreuses organisations, les fichiers PDF constituent à la fois une source de données essentielle et un obstacle majeur dans les processus d'extraction, de transformation et de chargement (ETL) ainsi que dans les flux d'intégration de données. Bien que les fichiers PDF modernes, contenant du texte sélectionnable, soient relativement faciles à traiter, une part importante des données critiques pour l'entreprise reste piégée dans des documents numérisés : archives papier numérisées, anciens enregistrements et fichiers basés sur des images, où le texte n'existe qu'en tant que pixels, et non sous forme de caractères lisibles par machine. Le défi consiste à transformer leur contenu non structuré en données utilisables.
La fonctionnalité de reconnaissance optique de caractères (OCR) intégrée à l'outil MapForce PDF Extractor comble cette lacune en transformant le contenu des fichiers PDF basés sur des images en données structurées et exploitables, prêtes à être traitées et converties vers d'autres formats.

Transformer les scans en données structurées
Les organisations qui disposent d'archives papier accumulées depuis des décennies sont confrontées à un défi que la numérisation seule ne peut résoudre : la numérisation préserve l'apparence d'un document, mais pas ses données, transformant ainsi les fichiers PDF numérisés en de simples images de texte que les ordinateurs ne peuvent ni rechercher ni traiter. Pour les ingénieurs de données qui construisent des pipelines ETL, cela signifie que des informations historiques précieuses restent inaccessibles, malgré leur "numérisation". De nombreux documents essentiels, tels que les formulaires manuscrits, les rapports financiers anciens, les déclarations réglementaires et les contrats numérisés, entrent dans cette catégorie, obligeant les équipes à recourir à une saisie manuelle de données, source d'erreurs et qui ralentit les processus automatisés.
C'est pourquoi la reconnaissance optique de caractères (OCR) est un élément essentiel de tout projet d'intégration de données PDF.
La technologie OCR (reconnaissance optique de caractères) convertit les images de texte en données de caractères réelles que les applications peuvent traiter. Dans le MapForce PDF Extractor, la fonction OCR joue le rôle d'une étape de prétraitement qui transforme les documents numérisés en un format structuré similaire à celui des fichiers PDF basés sur du texte, permettant ainsi un traitement uniforme des données, quel que soit l'origine du document source.
L'implémentation de MapForce est basée sur Tesseract OCR, un moteur de reconnaissance open source réputé pour être l'un des plus précis disponibles. Cette technologie combine la reconnaissance de motifs traditionnelle avec des approches modernes basées sur les réseaux neuronaux LSTM (Long Short-Term Memory). Cette architecture hybride offre la flexibilité nécessaire pour traiter une grande variété de types et de mises en page de documents, tout en maintenant une grande précision dans de nombreuses langues, notamment l'anglais, l'allemand, le français, le japonais et l'espagnol. (Le logiciel MapForce lui-même est également disponible dans ces langues.)
Ayant La fonctionnalité de reconnaissance optique de caractères (OCR) est intégrée à l'outil d'extraction de fichiers PDF MapForce constitue un avantage majeur. Au lieu d'obliger les développeurs à exécuter la reconnaissance optique de caractères (OCR) comme une étape de prétraitement distincte, en utilisant des outils externes, puis à importer les résultats, MapForce l'intègre directement dans le processus d'extraction des données PDF, ce qui permet de gagner du temps et Permet l'automatisation.
De la reconnaissance optique de caractères à l'extraction de données structurées
Bien sûr, la reconnaissance de texte n'est qu'une partie de la solution. Pour que le contenu numérisé soit exploitable, ce texte doit être organisé pour un traitement ultérieur. La véritable valeur réside dans le fait que ce texte se transforme en données structurées, prêtes à être utilisées pour la cartographie et la transformation.
Lorsque vous effectuez une reconnaissance optique de caractères (OCR) sur un fichier PDF numérisé dans MapForce, le processeur affiche le contenu détecté sous forme d'une arborescence d'objets. Une superposition du document lui-même montre comment le processeur OCR a détecté les mots dans la zone numérisée, en affichant les mots reconnus en vert. Les mots mis en surbrillance en rouge n'ont pas été ajoutés à l'arborescence, car leur niveau de confiance n'atteignait pas le seuil défini par le processeur. Vous pouvez modifier l'arborescence, ainsi que les mots en vert et en rouge, manuellement, si nécessaire, à l'aide d'outils simples et intuitifs.
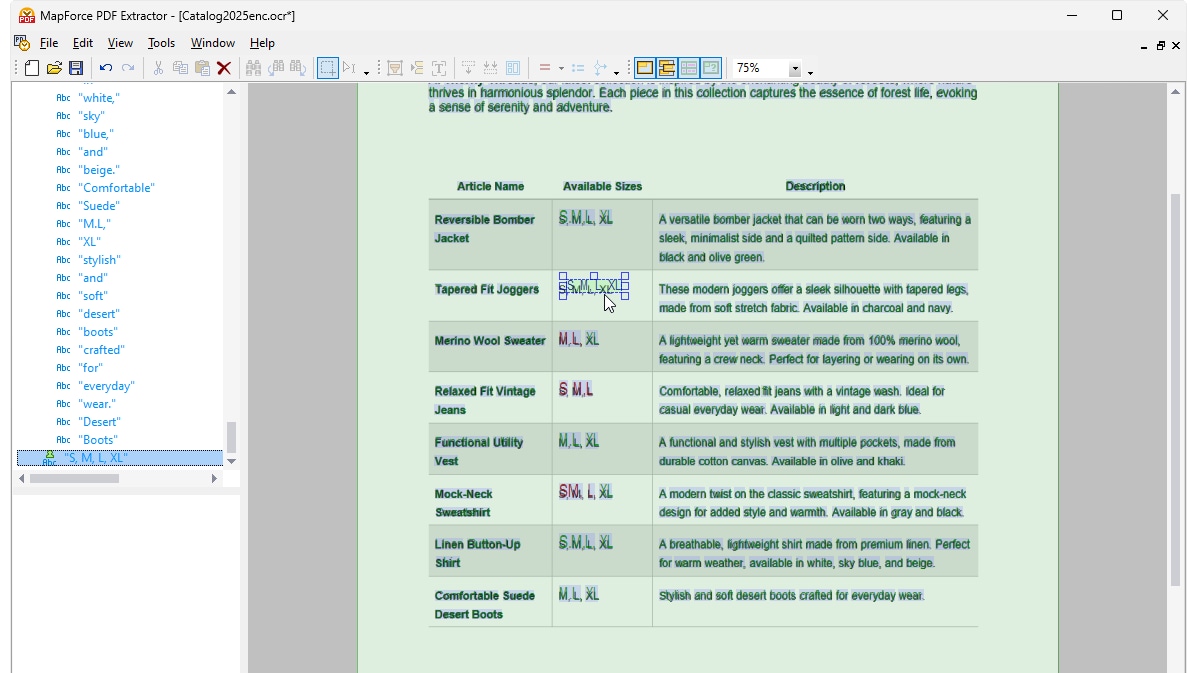
Une fois que vous êtes satisfait des résultats de la reconnaissance optique de caractères (OCR), le texte reconnu est ajouté au flux de travail d'extraction standard de MapForce PDF Extractor. L'outil PDF Extractor intègre un moteur de suggestions puissant qui identifie automatiquement les éléments courants des documents, tels que les tableaux et les blocs de texte, et tente de détecter leur structure. Vous pouvez affiner cette structure si nécessaire en divisant le contenu en lignes/colonnes, en définissant des règles d'extraction en fonction des en-têtes ou des mots-clés, etc. Le modèle que vous définissez reflète la structure du document, ce qui le rend disponible pour la mise en correspondance.
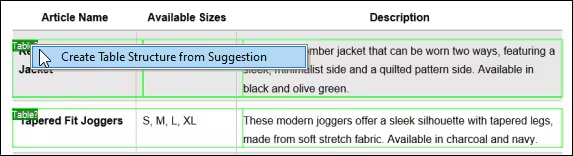
Grâce à cette configuration basée sur des modèles, la reconnaissance optique de caractères (OCR) n'est effectuée qu'une seule fois, lors de la création du modèle. Par la suite, MapForce peut traiter d'autres documents ayant le même format en utilisant les règles d'extraction enregistrées, sans avoir à répéter l'opération de reconnaissance optique. Cela permet de gagner du temps et des ressources dans les projets d'intégration de données ou d'ETL qui traitent des formulaires ou des rapports standardisés.
Les données extraites se transforment en une structure de cartographie visuelle représentant le contenu du PDF, que vous pouvez ensuite associer à n'importe quel format cible pris en charge (bases de données, JSON, Excel, XML, EDI, Shopify, etc.). Ce paradigme de cartographie visuelle facilite la définition des transformations grâce à une interface de glisser-déposer pour établir des liens entre les schémas source et cible, avec une bibliothèque de fonctions complète et un constructeur de fonctions visuel qui gère les conversions de types de données, le filtrage et la logique conditionnelle.
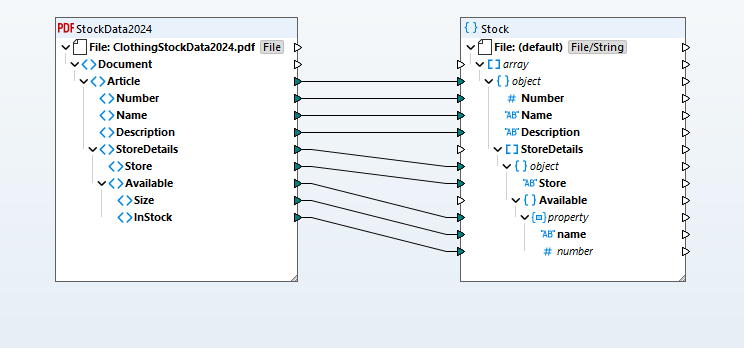
En fonction de la définition de la correspondance de données que vous avez spécifiée, MapForce transforme les données instantanément. Vous pouvez également utiliser l'édition avancée de MapForce Server pour une automatisation performante.
Essayez les outils de reconnaissance optique de caractères (OCR) intégrés à l'outil PDF Extractor grâce à une version d'essai gratuite de MapForce dès aujourd'hui !