Het toegankelijk maken van gescande PDF-bestanden met OCR-ondersteuning in MapForce
Voor veel organisaties zijn PDF-bestanden zowel een belangrijke bron van data als een voortdurend obstakel in ETL-processen (Extract, Transform, Load) en data-integratie workflows. Hoewel moderne PDF-bestanden met selecteerbare tekst relatief eenvoudig te verwerken zijn, blijft een aanzienlijk deel van de bedrijfskritische data vastzitten in gescande documenten: gedigitaliseerde papierenarchieven, oude dossiers en bestanden op basis van afbeeldingen, waarbij tekst alleen bestaat uit pixels en niet als machineleesbare karakters. De uitdaging ligt in het omzetten van deze ongestructureerde inhoud in bruikbare data.
De OCR-ondersteuning (Optical Character Recognition) in de MapForce PDF Extractor sluit dit gat, door de inhoud van PDF-bestanden die bestaan uit afbeeldingen om te zetten in gestructureerde, extraheerbare gegevens, klaar voor verwerking en omzetting naar andere formaten.

Het omzetten van scans naar gestructureerde gegevens
Organisaties met decennia aan papieren documenten staan voor een uitdaging die digitalisering alleen niet kan oplossen: het scannen behoudt de visuele presentatie van een document, maar niet de data. Hierdoor blijven gescande PDF-bestanden slechts afbeeldingen van tekst, die computers niet kunnen doorzoeken of verwerken. Voor data-engineers die ETL-pijplijnen bouwen, betekent dit dat waardevolle historische informatie onbereikbaar blijft, ondanks dat deze "gedigitaliseerd" is. Veel essentiële documenten, zoals handgeschreven formulieren, oude financiële rapporten, wettelijke documenten en gescande contracten, vallen in deze categorie, waardoor teams gedwongen worden om te vertrouwen op handmatige, foutgevoelige data-invoer, wat anders geautomatiseerde processen vertraagt.
Daarom is OCR een essentieel onderdeel van elk project waarbij PDF-gegevens worden geïntegreerd.
De OCR-technologie zet afbeeldingen van tekst om in daadwerkelijke tekengegevens die applicaties kunnen verwerken. In de MapForce PDF Extractor fungeert OCR als een voorbewerking die gescande documenten omzet in hetzelfde gestructureerde formaat als tekstgebaseerde PDF-bestanden, waardoor een uniforme verdere verwerking mogelijk is, ongeacht de oorsprong van het brondocument.
De MapForce-implementatie is gebaseerd op Tesseract OCR, een open-source herkenningsengine die bekend staat als een van de meest accurate systemen die beschikbaar zijn. De technologie combineert traditionele patroonherkenning met moderne LSTM (Long Short-Term Memory) neurale netwerktechnieken. Deze hybride architectuur biedt de flexibiliteit om een breed scala aan documenttypen en -indelingen te verwerken, terwijl tegelijkertijd een hoge nauwkeurigheid wordt gehandhaafd in verschillende talen, waaronder Engels, Duits, Frans, Japans en Spaans. (De MapForce-software zelf is ook in deze talen beschikbaar.)
Het feit dat OCR-functionaliteit is geïntegreerd in de MapForce PDF Extractor is een groot voordeel. In plaats van ontwikkelaars te verplichten om OCR als een aparte voorbewerkingstap met externe tools uit te voeren en vervolgens de resultaten te importeren, integreert MapForce het direct in de workflow voor het extraheren van PDF-bestanden, wat tijd bespaart en automatisering mogelijk maakt.
Van optische tekenherkenning naar gestructureerde data-extractie
Natuurlijk is het herkennen van tekst slechts een onderdeel van de oplossing. Om gescande content bruikbaar te maken, moet die tekst worden georganiseerd voor verdere verwerking. De werkelijke waarde komt tot uiting wanneer die tekst wordt omgezet in gestructureerde data, klaar om te worden gebruikt voor analyses en transformaties.
Wanneer u OCR uitvoert op een gescande PDF in MapForce, toont de processor de gedetecteerde inhoud in een boomstructuur. Een overlay van het document zelf laat zien hoe de OCR-processor woorden in het gescande gebied heeft herkend, waarbij de herkende woorden in het groen worden weergegeven. Woorden die in het rood zijn gemarkeerd, zijn niet aan de boomstructuur toegevoegd, omdat hun betrouwbaarheidsscore niet aan de vereiste drempelwaarde van de processor voldeed. U kunt de boomstructuur, evenals de groene en rode woorden, handmatig bewerken met behulp van eenvoudige, intuïtieve tools.
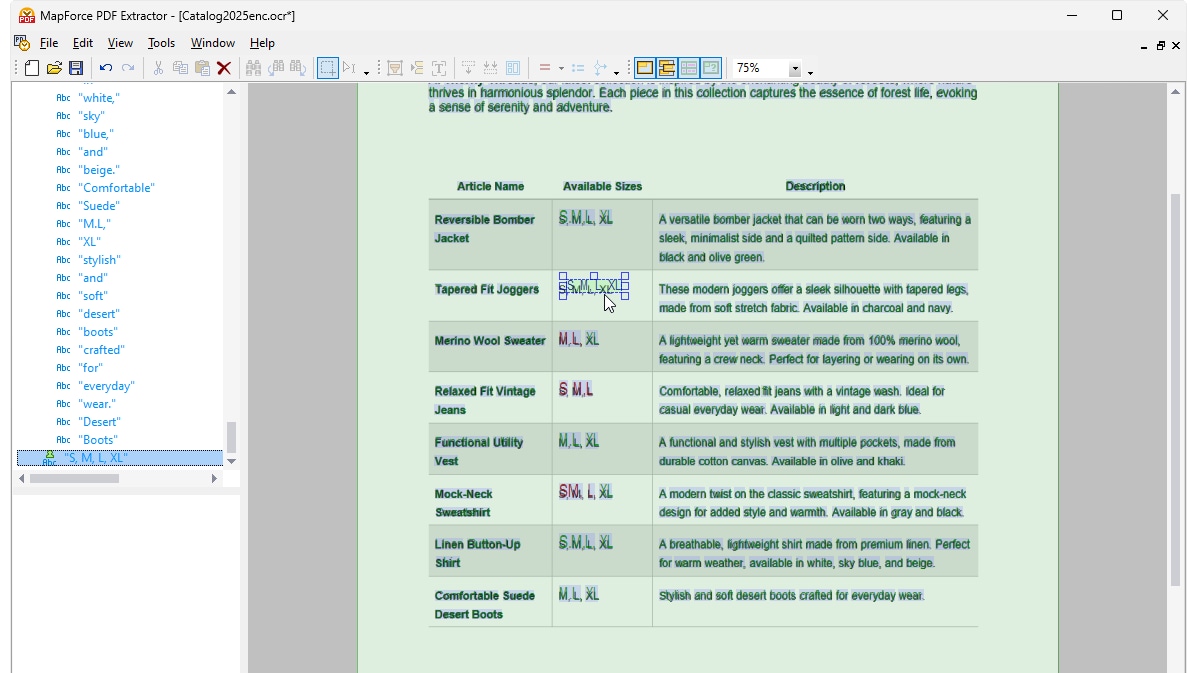
Zodra u tevreden bent met de resultaten van de optische tekenherkenning (OCR), wordt de herkende tekst toegevoegd aan de standaard extractieworkflow van de MapForce PDF Extractor. De PDF Extractor bevat een krachtige suggestiemotor die automatisch veelvoorkomende documentelementen, zoals tabellen en tekstblokken, identificeert en probeert hun structuur te detecteren. U kunt deze structuur indien nodig verfijnen door de inhoud op te delen in rijen/kolommen, extractieregels te definiëren op basis van koppen of trefwoorden, enzovoort. Het sjabloon dat u definieert, weerspiegelt de structuur van het document, waardoor het beschikbaar is voor het maken van koppelingen.
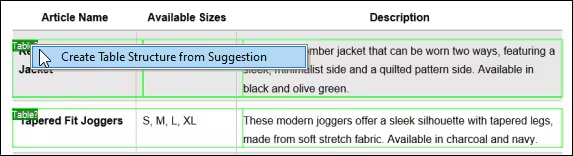
Met deze op sjabloon gebaseerde instelling wordt OCR slechts één keer uitgevoerd, namelijk bij het aanmaken van het sjabloon. Vervolgens kan MapForce andere documenten met dezelfde lay-out verwerken met behulp van de opgeslagen extractieregels – er is geen herhaalde OCR-verwerking nodig. Dit bespaart tijd en middelen bij grootschalige data-integratie of ETL-processen die gestandaardiseerde formulieren of rapporten verwerken.
De geëxtraheerde gegevens worden omgezet in een visuele structuur die de inhoud van het PDF-bestand weergeeft. Deze structuur kan vervolgens worden gekoppeld aan elk ondersteund doelformaat (databases, JSON, Excel, XML, EDI, Shopify, enz.). Het visuele mapping-principe maakt het eenvoudig om transformaties te definiëren door elementen te slepen en neer te zetten, waardoor verbindingen kunnen worden gemaakt tussen de bron- en doelstructuren. Een uitgebreide functiebibliotheek en een "Visuele Functiebouwer" verzorgen de conversie van datatypes, filtering en voorwaardelijke logica.
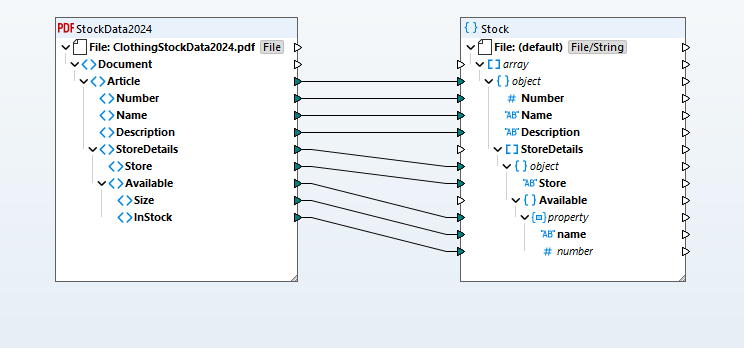
Op basis van uw datamappingspecificaties transformeert MapForce de gegevens direct. Of, u kunt gebruikmaken van MapForce Server Advanced Edition voor geavanceerde automatisering met hoge prestaties.
Probeer vandaag nog de OCR-tools in de PDF-extractor met een gratis proefversie van MapForce!