Sbloccare i file PDF scansionati con il supporto OCR in MapForce
Per molte organizzazioni, i file PDF rappresentano sia una fonte di dati essenziale che un ostacolo persistente nei processi di estrazione, trasformazione e caricamento (ETL) e nell'integrazione dei dati. Sebbene i PDF moderni, con testo selezionabile, siano relativamente facili da elaborare, una parte significativa dei dati fondamentali per l'attività rimane intrappolata in documenti scansionati: archivi cartacei digitalizzati, registri obsoleti e file basati su immagini, dove il testo esiste solo come pixel, e non come caratteri leggibili dalle macchine. La sfida consiste nel trasformare il loro contenuto non strutturato in dati utilizzabili.
Il supporto per l'OCR (riconoscimento ottico dei caratteri) integrato nell'estratto PDF di MapForce colma questa lacuna, trasformando i contenuti presenti nei PDF basati su immagini in dati strutturati e facilmente estraibili, pronti per essere elaborati e convertiti in altri formati.

Trasformare le scansioni in dati strutturati
Le organizzazioni che conservano da decenni archivi cartacei si trovano di fronte a una sfida che la digitalizzazione da sola non può risolvere: la scansione preserva l'aspetto di un documento, ma non i suoi dati, trasformando i PDF scansionati in semplici immagini di testo che i computer non possono cercare o elaborare. Per gli ingegneri dei dati che sviluppano pipeline ETL, questo significa che preziose informazioni storiche rimangono inaccessibili, nonostante siano state "digitalizzate". Molti documenti essenziali, come moduli scritti a mano, vecchi rapporti finanziari, documenti normativi e contratti scansionati, rientrano in questa categoria, costringendo i team a ricorrere a un inserimento manuale dei dati, soggetto a errori e che rallenta i flussi di lavoro che altrimenti sarebbero automatizzati.
Ecco perché l'OCR (riconoscimento ottico dei caratteri) è un elemento fondamentale in qualsiasi progetto di integrazione dei dati PDF.
La tecnologia OCR (riconoscimento ottico dei caratteri) converte le immagini di testo in dati di caratteri effettivi che le applicazioni possono elaborare. In MapForce PDF Extractor, le funzioni OCR agiscono come una fase di pre-elaborazione che trasforma i documenti scansionati nello stesso formato strutturato dei PDF basati su testo, consentendo un'elaborazione uniforme successiva, indipendentemente dall'origine del documento.
L'implementazione di MapForce si basa su Tesseract OCR, un motore di riconoscimento open source noto per essere uno dei più accurati disponibili. La tecnologia combina il riconoscimento di pattern tradizionale con approcci moderni basati su reti neurali LSTM (Long Short-Term Memory). Questa architettura ibrida offre la flessibilità necessaria per gestire una varietà di tipi e formati di documenti, mantenendo al contempo un'elevata precisione in diverse lingue, tra cui inglese, tedesco, francese, giapponese e spagnolo. (Anche il software MapForce è disponibile in queste lingue.)
Avere Il software di riconoscimento ottico dei caratteri (OCR) è integrato nell'estratto PDF di MapForce rappresenta un notevole vantaggio. Invece di costringere gli sviluppatori a eseguire l'OCR come fase di pre-elaborazione separata, utilizzando strumenti esterni e poi importando i risultati, MapForce integra direttamente l'OCR nel flusso di lavoro di estrazione dei dati dai PDF, il che consente di risparmiare tempo e consente l'automazione.
Dall'OCR all'estrazione di dati strutturati
Naturalmente, il riconoscimento del testo è solo una parte della soluzione. Per rendere i contenuti digitalizzati utilizzabili, quel testo deve essere organizzato per ulteriori elaborazioni. Il vero valore si manifesta quando quel testo viene trasformato in dati strutturati, pronti per essere analizzati e modificati.
Quando si esegue l'OCR su un file PDF scansionato in MapForce, il processore visualizza il contenuto rilevato in una struttura ad albero. Una sovrapposizione del documento stesso mostra come il processore OCR ha identificato le parole nell'area di scansione, evidenziando le parole riconosciute in verde. Le parole evidenziate in rosso non sono state aggiunte alla struttura ad albero, poiché il loro livello di affidabilità non ha raggiunto la soglia stabilita dal processore. È possibile modificare la struttura ad albero, nonché le parole evidenziate in verde e in rosso, manualmente, utilizzando strumenti semplici e intuitivi.
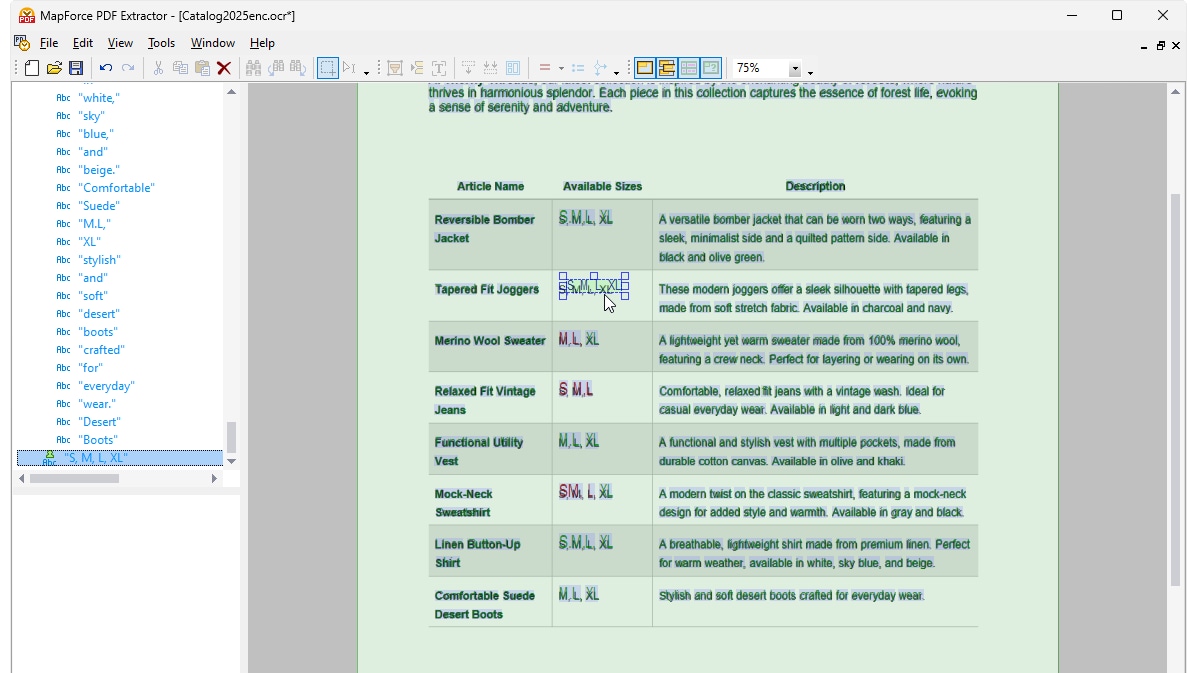
Una volta che si è soddisfatti dei risultati dell'OCR, il testo riconosciuto viene aggiunto al flusso di lavoro standard di estrazione di MapForce PDF Extractor. Il PDF Extractor include un potente motore di suggerimenti che identifica automaticamente elementi comuni dei documenti, come tabelle e blocchi di testo, e cerca di rilevare la loro struttura, che è possibile perfezionare a seconda delle necessità, suddividendo il contenuto in righe/colonne, definendo regole di estrazione basate su intestazioni o parole chiave, ecc. Il modello che si definisce riflette la struttura del documento, rendendola disponibile per la mappatura.
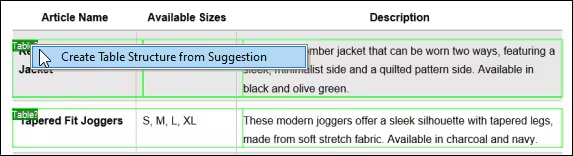
Grazie a questa configurazione basata su modelli, l'OCR viene eseguito una sola volta, al momento della creazione del modello. Successivamente, MapForce può elaborare altri documenti con lo stesso layout, utilizzando le regole di estrazione memorizzate, senza dover ripetere l'operazione di OCR. Questo consente di risparmiare tempo e risorse in processi di integrazione dati o ETL che elaborano documenti o report standardizzati.
I dati estratti vengono trasformati in una struttura di mappatura visiva che rappresenta il contenuto del file PDF, e che può quindi essere utilizzata per convertire i dati in qualsiasi formato supportato (database, JSON, Excel, XML, EDI, Shopify, ecc.). Questo approccio di mappatura visiva semplifica la definizione delle trasformazioni, consentendo di creare collegamenti tra gli schemi di origine e di destinazione tramite semplici operazioni di trascinamento, e offre una libreria di funzioni completa Costruttore di funzionalità visive gestione delle conversioni dei tipi di dati, del filtraggio e della logica condizionale.
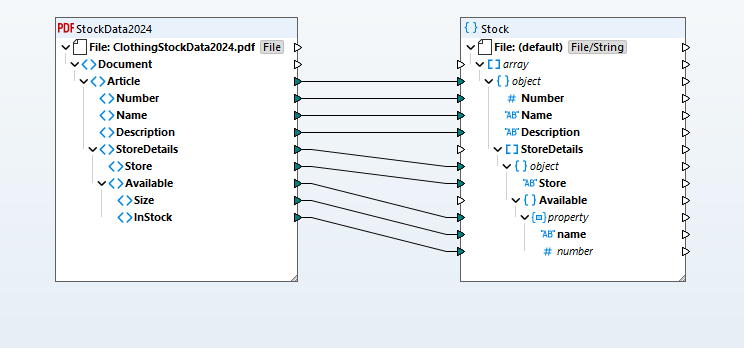
In base alla definizione della mappatura dei dati, MapForce trasforma i dati istantaneamente. In alternativa, è possibile utilizzare MapForce Server Advanced Edition per un'automazione ad alte prestazioni.
Provate gli strumenti di riconoscimento ottico dei caratteri (OCR) inclusi in PDF Extractor con una prova gratuita di MapForce oggi stesso!