Unlocking Scanned PDFs with OCR Support in MapForce
For many organizations, PDFs are both a vital data source and a persistent roadblock in ETL and data integration workflows. While modern PDFs with selectable text are relatively straightforward to process, a substantial portion of business-critical data remains trapped in scanned documents—digitized paper archives, legacy records, and image-based files where text exists only as pixels, not as machine-readable characters. The challenge lies in transforming their unstructured content into usable data.
OCR (optical character recognition) support in the MapForce PDF Extractor addresses this gap, transforming content in image-based PDFs into structured, extractable data ready for processing and mapping to other formats.

Transforming Scans into Structured Data
Organizations with decades of paper records face a challenge that digitalization alone cannot address: scanning preserves a document’s appearance but not its data, leaving scanned PDFs as mere images of text that computers can’t search or process. For data engineers building ETL pipelines, this means valuable historical information remains inaccessible despite being “digitized.” Many essential documents, such as handwritten forms, legacy financial reports, regulatory filings, and scanned contracts fall into this category, forcing teams to rely on manual, error-prone data entry that slows down otherwise automated workflows.
That’s why OCR is a critical component of any PDF data integration project.
OCR technology converts images of text into actual character data that applications can process. In the MapForce PDF Extractor, OCR functions as a preprocessing step that transforms scanned documents into the same structured format as text-based PDFs, enabling uniform downstream processing regardless of the source document's origin.
The MapForce implementation is based on Tesseract OCR, an open-source recognition engine known for being one of the most accurate engines available. The technology combines traditional pattern recognition with modern LSTM (Long Short-Term Memory) neural network approaches. This hybrid architecture provides the flexibility to handle a variety of document types and layouts while maintaining high accuracy across multiple languages, including English, German, French, Japanese, and Spanish. (The MapForce software itself is also available in these languages.)
Having OCR built into the MapForce PDF Extractor is a major advantage. Instead of forcing developers to run OCR as a separate preprocessing step with external tools and then import the results, MapForce integrates it directly into the PDF extraction workflow, which saves time and enables automation.
From OCR to Structured Data Extraction
Of course, recognizing text is only part of the solution. To make scanned content actionable, that text must be organized for further processing. The real value emerges when that text becomes structured data ready for mapping and transformation.
When you run OCR on a scanned PDF in MapForce, the processor displays the detected content in a tree of objects. An overlay of the document itself shows how the OCR processor has detected words in the scan area, displaying recognized words in green. Words highlighted in red were not added to the tree, as their confidence score did not meet the processor’s threshold. You can edit the tree, as well as green and red words manually, as required, using easy, point-and-click tools.
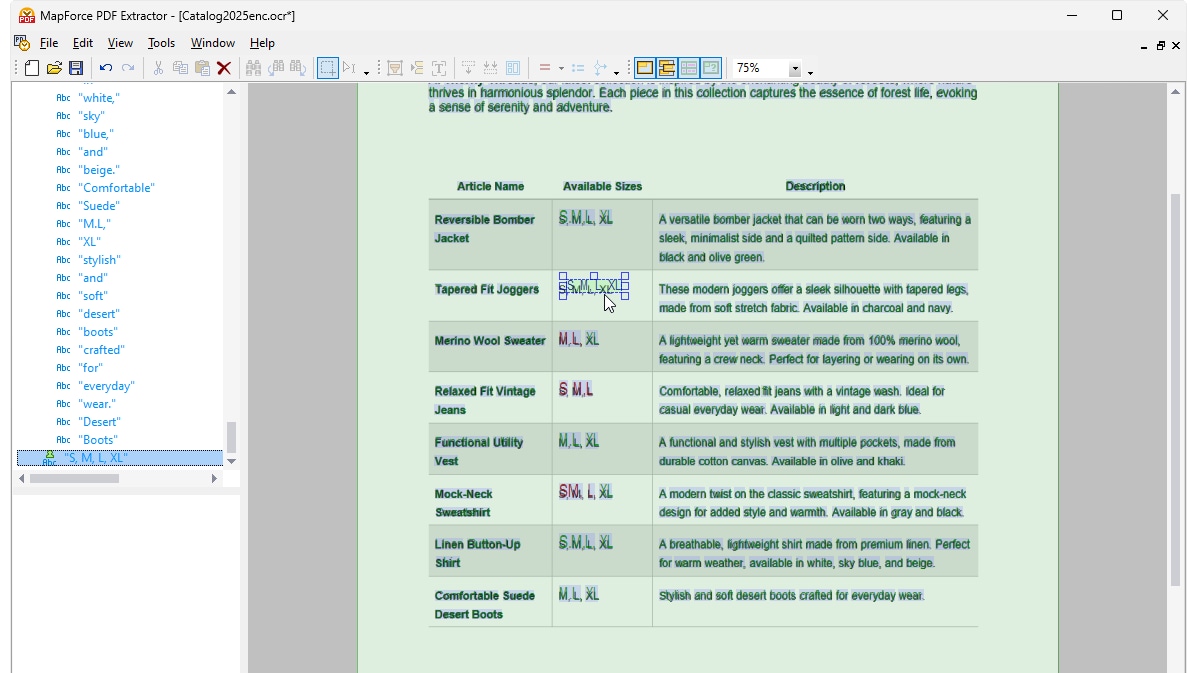
Once you are happy with the OCR results, the recognized text is added to the MapForce PDF Extractor's standard extraction workflow. The PDF Extractor includes a powerful suggestion engine that automatically identifies common document elements like tables and text blocks and attempts to detect their structure, which you can refine as needed by splitting content into rows/columns, anchoring extraction rules based on headers or keywords, etc. The template you define reflects the document structure to make it available for mapping.
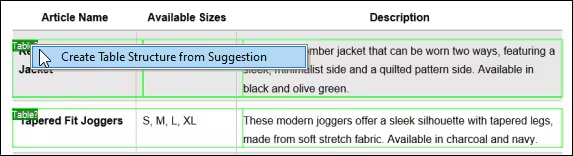
With this template-based setup, OCR runs only once when the template is created. After that, MapForce can process other documents with the same layout using the stored extraction rules—no need to repeat OCR. This saves time and resources in high-volume data integration or ETL jobs that process standardized forms or reports.
The extracted data becomes a visual mapping structure representing the PDF's content, which you can then then map to any supported target format (databases, JSON, Excel, XML, EDI, Shopify, etc.). The visual mapping paradigm makes it easy to define transformations using drag-and-drop to make connections between source and target schemas, with a comprehensive function library and Visual Function Builder handling data type conversions, filtering, and conditional logic.
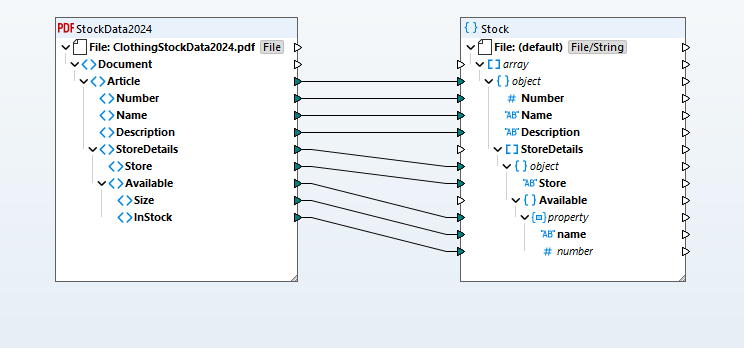
Based on your data mapping definition, MapForce transforms the data instantly. Or, you can take advantage of MapForce Server Advanced Edition for high-performance automation.
Try the OCR tools in the PDF Extractor with a free trial of MapForce today!