Desbloquear ficheiros PDF digitalizados com suporte OCR no MapForce
Para muitas organizações, os documentos PDF são tanto uma fonte de dados essencial como um obstáculo constante nos processos de ETL (extração, transformação e carregamento) e integração de dados. Embora os documentos PDF modernos, com texto selecionável, sejam relativamente fáceis de processar, uma parte significativa dos dados críticos para o negócio permanece presa em documentos digitalizados – arquivos de papel digitalizados, registos antigos e ficheiros baseados em imagens, onde o texto existe apenas como pixels, e não como caracteres legíveis por máquina. O desafio reside em transformar o conteúdo não estruturado destes documentos em dados utilizáveis.
O suporte para OCR (reconhecimento ótico de caracteres) no MapForce PDF Extractor resolve esta lacuna, transformando o conteúdo de documentos PDF baseados em imagens em dados estruturados e extraíveis, prontos para serem processados e mapeados para outros formatos.

Transformar digitalizações em dados estruturados
Organizações com décadas de registos em papel enfrentam um desafio que a digitalização, por si só, não consegue resolver: a digitalização preserva a aparência de um documento, mas não os seus dados, deixando os documentos PDF digitalizados como meras imagens de texto que os computadores não conseguem pesquisar ou processar. Para os engenheiros de dados que estão a desenvolver.. Pipelines de ETL, Isto significa que informações históricas valiosas permanecem inacessíveis, apesar de terem sido "digitalizadas". Muitos documentos essenciais, como formulários manuscritos, relatórios financeiros antigos, documentos regulatórios e contratos digitalizados, pertencem a esta categoria, o que obriga as equipas a recorrer à introdução manual de dados, sujeita a erros, e que retarda processos de trabalho que, de outra forma, seriam automatizados.
É por isso que o OCR (reconhecimento ótico de caracteres) é um componente essencial em qualquer projeto de integração de dados em formato PDF.
A tecnologia OCR (Reconhecimento Óptico de Caracteres) converte imagens de texto em dados de caracteres reais que as aplicações podem processar. No MapForce PDF Extractor, a função OCR atua como uma etapa de pré-processamento que transforma documentos digitalizados num formato estruturado semelhante aos PDFs baseados em texto, permitindo um processamento uniforme, independentemente da origem do documento.
A implementação do MapForce baseia-se no Tesseract OCR, um motor de reconhecimento de código aberto conhecido por ser um dos mais precisos disponíveis. A tecnologia combina o reconhecimento de padrões tradicional com abordagens modernas de redes neurais LSTM (Long Short-Term Memory). Esta arquitetura híbrida oferece a flexibilidade necessária para lidar com uma variedade de tipos e formatos de documentos, mantendo, ao mesmo tempo, um elevado nível de precisão em várias línguas, incluindo inglês, alemão, francês, japonês e espanhol. (O próprio software MapForce também está disponível nestas línguas.)
A integração do reconhecimento ótico de caracteres (OCR) no MapForce PDF Extractor é uma grande vantagem. Em vez de obrigar os programadores a executar o OCR como uma etapa de pré-processamento separada, utilizando ferramentas externas, e depois importar os resultados, o MapForce integra-o diretamente no fluxo de trabalho de extração de PDFs, o que poupa tempo e permite a automatização.
Da Reconhecimento Óptico de Caracteres à Extração de Dados Estruturados
Claro que, reconhecer texto é apenas parte da solução. Para que o conteúdo digitalizado seja útil, esse texto deve ser organizado para processamento posterior. O verdadeiro valor surge quando esse texto se transforma em dados estruturados, prontos para serem mapeados e transformados.
Quando executa o OCR num ficheiro PDF digitalizado no MapForce, o processador exibe o conteúdo detetado numa estrutura de objetos. Uma sobreposição do próprio documento mostra como o processador de OCR detetou as palavras na área digitalizada, exibindo as palavras reconhecidas em verde. As palavras destacadas em vermelho não foram adicionadas à estrutura, pois a sua pontuação de confiança não atingiu o limite definido pelo processador. Pode editar a estrutura, bem como as palavras em verde e em vermelho, manualmente, conforme necessário, utilizando ferramentas simples e intuitivas.
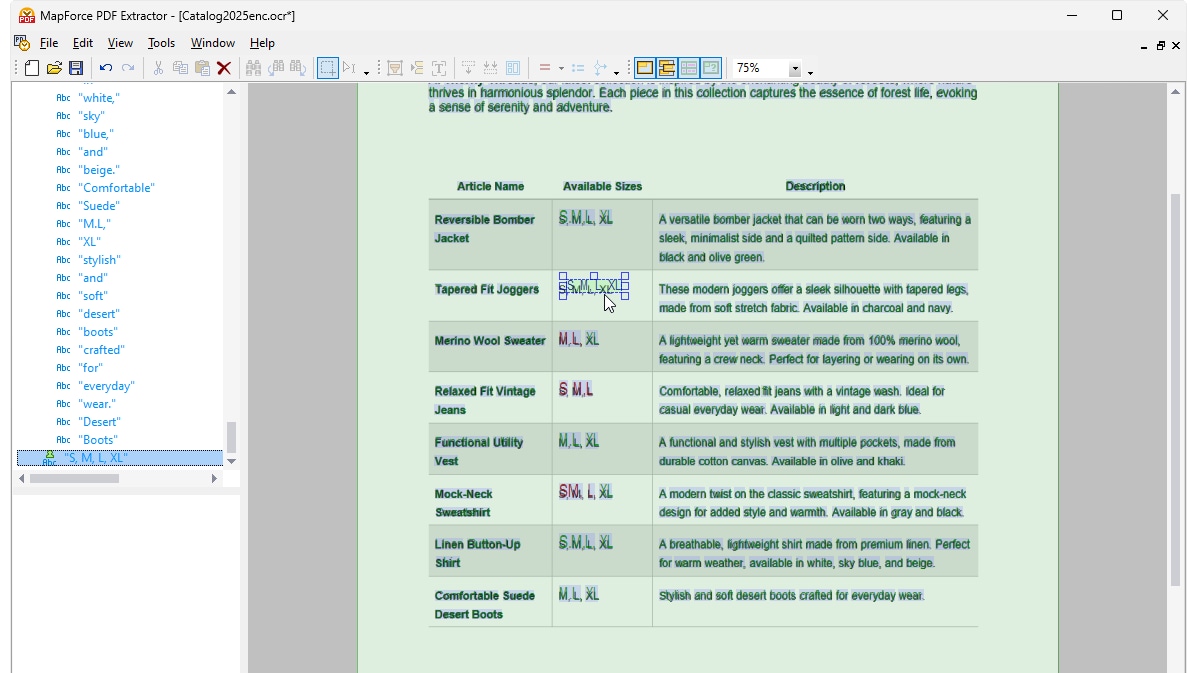
Assim que estiver satisfeito com os resultados da OCR, o texto reconhecido é adicionado ao fluxo de trabalho de extração padrão do MapForce PDF Extractor. O PDF Extractor inclui um motor de sugestões poderoso que identifica automaticamente elementos comuns em documentos, como tabelas e blocos de texto, e tenta detetar a sua estrutura. Pode refinar esta estrutura, se necessário, dividindo o conteúdo em linhas/colunas, definindo regras de extração com base em cabeçalhos ou palavras-chave, etc. O modelo que define reflete a estrutura do documento, tornando-o disponível para mapeamento.
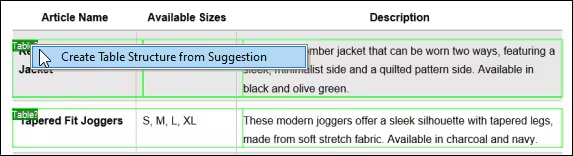
Com esta configuração baseada em modelos, o OCR é executado apenas uma vez, no momento da criação do modelo. Depois disso, o MapForce pode processar outros documentos com o mesmo layout, utilizando as regras de extração armazenadas, eliminando a necessidade de repetir o processo de OCR. Isto poupa tempo e recursos em projetos de integração de dados ou ETL que processam formulários ou relatórios padronizados.
Os dados extraídos transformam-se numa estrutura de mapeamento visual que representa o conteúdo do PDF, podendo então ser mapeados para qualquer formato de destino suportado (bases de dados, JSON, Excel, XML, EDI, Shopify, etc.). Este paradigma de mapeamento visual facilita a definição de transformações através de arrastar e soltar, permitindo estabelecer ligações entre os esquemas de origem e destino, com uma biblioteca de funções abrangente e um Construtor Visual de Funções que gerencia conversões de tipos de dados, filtragem e lógica condicional.
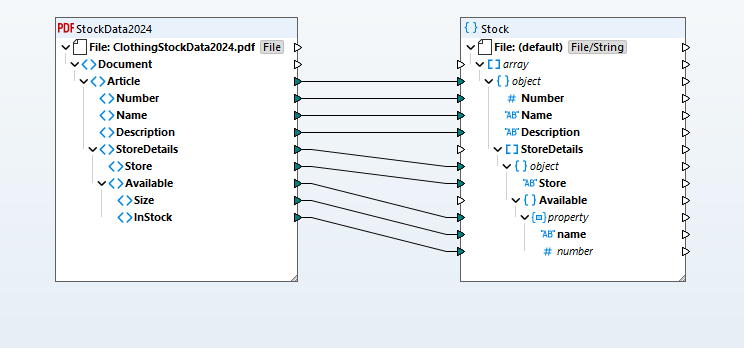
Com base na definição de mapeamento de dados que você fornecer, o MapForce transforma os dados instantaneamente. Ou, pode utilizar o MapForce Server Advanced Edition para automatizar processos com alto desempenho.
Experimente as ferramentas de reconhecimento ótico de caracteres (OCR) no extrator de PDF com um período de teste gratuito do MapForce hoje mesmo!