MapForceにおけるOCR機能によるスキャンされたPDFファイルの読み込み機能について
多くの組織にとって、PDFファイルは重要なデータソースであると同時に、ETL(抽出、変換、ロード)やデータ統合のプロセスにおける大きな課題となっています。現代のPDFファイルの中には、テキストを選択できるものが比較的容易に処理できますが、ビジネスにとって重要なデータの多くは、スキャンされた文書、デジタル化された紙媒体のアーカイブ、古い記録、画像ベースのファイルといった形式で存在しており、その中にあるテキストは機械が読み取れる文字としてではなく、単なるピクセルとして保存されているため、処理が困難です。課題は、これらの構造化されていない情報を、活用可能なデータに変換することにあります。
MapForce PDF Extractorに搭載されたOCR(光学文字認識)機能は、この課題を解決し、画像ベースのPDFに含まれるコンテンツを、処理や他の形式への変換に適した、構造化された抽出可能なデータに変換します。

スキャンデータを構造化されたデータに変換する
長年にわたって紙媒体で記録を蓄積してきた組織にとって、デジタル化だけでは解決できない課題があります。それは、スキャン技術が文書の外観を保存するものの、そのデータまでは保存できないという点です。その結果、スキャンされたPDFファイルは、コンピュータが検索や処理できない単なるテキストの画像として扱われてしまいます。データエンジニアが構築する際には、この点を考慮する必要があります ETLパイプライン, これは、デジタル化されているにもかかわらず、貴重な歴史的情報が依然として利用できないことを意味します。手書きの書類、過去の財務報告書、規制関連の書類、スキャンされた契約書など、多くの重要な文書がこのカテゴリーに該当し、その結果、チームは本来であれば自動化できる作業プロセスを、手作業による、エラーが発生しやすいデータ入力に頼らざるを得なくなり、作業効率が低下します。
そのため、OCR(光学文字認識)は、PDFデータの統合プロジェクトにおいて非常に重要な要素となります。
OCR(光学文字認識)技術は、テキストの画像データを、アプリケーションが処理できる実際の文字データに変換します MapForce PDF抽出ツール, OCR(光学文字認識)は、スキャンされた文書を、テキストベースのPDFファイルと同様の構造化された形式に変換する前処理段階として機能します。これにより、元の文書の形式に関わらず、その後の処理を統一的に行うことが可能になります。
MapForceの機能は、オープンソースの認識エンジンであるTesseract OCRを基盤としています。Tesseract OCRは、非常に高い精度を誇るエンジンの一つとして知られています。この技術は、従来のパターン認識と、最新のLSTM(Long Short-Term Memory)ニューラルネットワークの手法を組み合わせたものです。このハイブリッドなアーキテクチャにより、多様な文書の種類やレイアウトに対応しながら、英語、ドイツ語、フランス語、日本語、スペイン語など、複数の言語において高い精度を維持することができます。(MapForceソフトウェア自体も、これらの言語で利用可能です。)
所有している MapForce PDF抽出機能に、光学文字認識(OCR)機能が組み込まれています 大きな利点として、MapForceは、開発者が外部ツールを使ってOCR処理を別工程として実行し、その結果をインポートする必要をなくします。代わりに、OCR処理をPDFデータ抽出のワークフローに直接統合することで、時間と手間を大幅に削減できます そして 自動化を可能にします。
光学文字認識(OCR)から構造化データ抽出へ
もちろん、テキストの認識は解決策の一部に過ぎません。スキャンされたコンテンツを実用的なものにするためには、そのテキストをさらに処理するために整理する必要があります。真価は、そのテキストが構造化されたデータとなり、マッピングや変換の準備が整ったときに生まれます。
MapForceでスキャンされたPDFに対してOCR処理を行うと、処理エンジンは検出された内容をオブジェクトのツリー構造で表示します。同時に、元のドキュメント上にオーバーレイが表示され、OCRエンジンがスキャン領域内の単語をどのように認識したかを示します。認識された単語は緑色で表示されます。赤色で強調表示された単語は、信頼度スコアがエンジンの設定値に達しなかったため、ツリー構造に追加されていません。必要に応じて、このツリー構造や、緑色および赤色の単語を手動で編集できます。簡単な操作で、マウスをクリックするだけで編集が可能です。
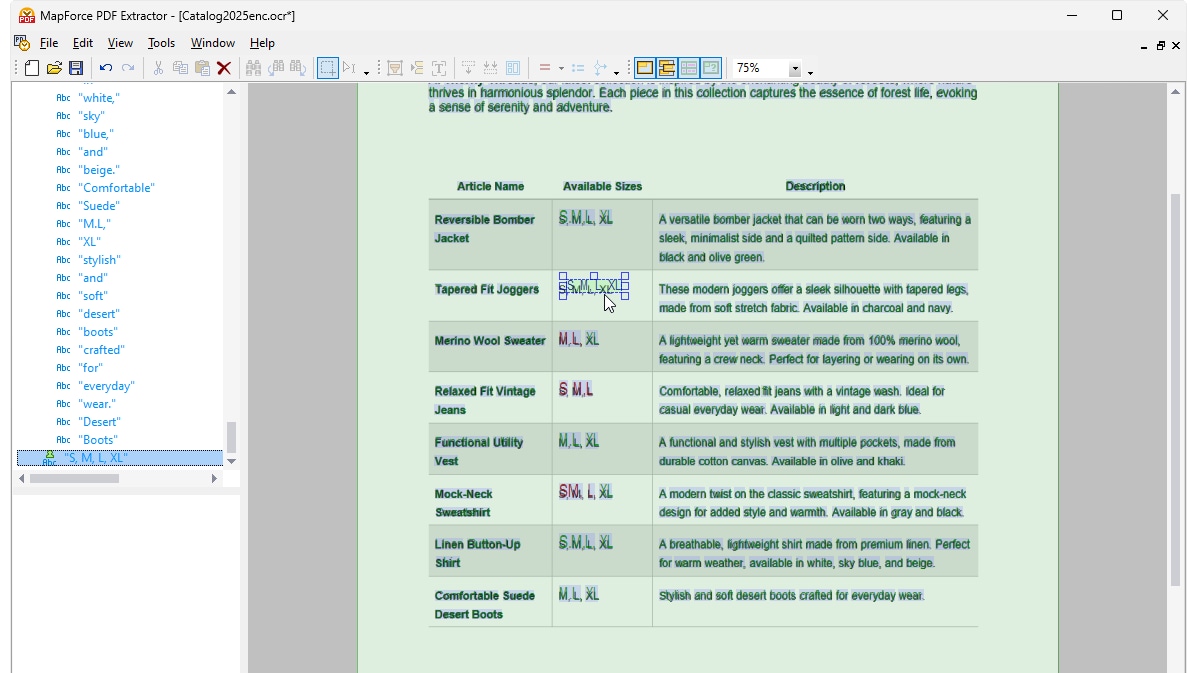
OCR処理の結果にご満足いただけたら、認識されたテキストがMapForce PDF Extractorの標準的な抽出ワークフローに追加されます PDF Extractorには、強力な提案機能が搭載されており、テーブルやテキストブロックなど、一般的なドキュメント要素を自動的に識別し、その構造を検出しようとします。必要に応じて、コンテンツを行/列に分割したり、ヘッダーやキーワードに基づいて抽出ルールを調整したりするなど、構造を調整することができます。定義したテンプレートは、ドキュメントの構造を反映し、マッピングに使用できるようにします。
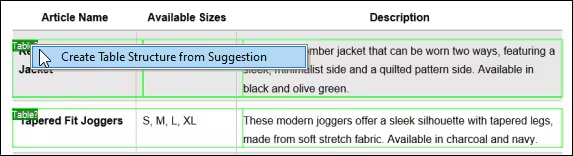
このテンプレートベースの仕組みでは、OCR処理はテンプレートが作成される際に一度だけ実行されます。その後、MapForceは、保存された抽出ルールを利用して、同じレイアウトの他の文書を処理できます。そのため、OCR処理を繰り返す必要はありません。これにより、標準化されたフォームやレポートを大量に処理するデータ統合やETLジョブにおいて、時間とリソースを節約できます。
抽出されたデータは、PDFの内容を視覚的に表現する構造となり、それをサポートされている様々な形式(データベース、JSON、Excel、XML、EDI、Shopifyなど)に変換することができます。この視覚的なマッピング機能により、ドラッグ&ドロップ操作でソースとターゲットのスキーマ間の関連性を簡単に定義でき、包括的な関数ライブラリとビジュアル関数ビルダーが、データ型の変換、フィルタリング、条件分岐などの処理をサポートします。
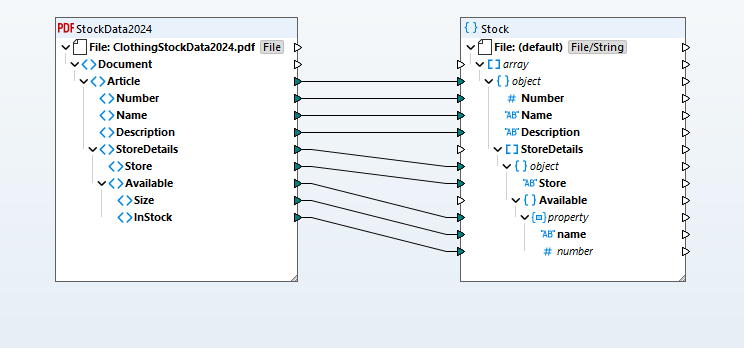
お客様が定義されたデータマッピングに基づいて、MapForceはデータを瞬時に変換します。または、高性能な自動化を実現するために、MapForce ServerのAdvanced Editionをご利用いただくことも可能です。
PDF抽出ツールに含まれるOCR機能をお試しください MapForceの無料トライアル版 本日!