MapForce umożliwia dynamiczny dostęp do nazw węzłów
W niektórych sytuacjach, zwłaszcza podczas pracy z danymi o luźnej strukturze, może być konieczne mapowanie i transformacja elementów strukturalnych strumienia danych wraz z jego zawartością. MapForce umożliwia dynamiczne odczytywanie nazw węzłów elementów XML, atrybutów lub kolumn plików tekstowych, takich jak zawartość plików CSV, w celu przypisania ich do odpowiednich komponentów.
Dynamiczne odwoływanie się do nazw elementów pozwala na tworzenie w czasie rzeczywistym elementów i atrybutów, których nazwy nie muszą być znane z góry ani konkretnie określone w mapowaniu danych. Ta funkcja umożliwia tworzenie znacznie bardziej ogólnych, elastycznych i wielokrotnego użytku mapowań, które wymagają mniejszej interwencji ręcznej, jeśli modele danych ulegają zmianom.

Oto przykład bardzo popularnego formatu pliku CSV, w którym pola danych nie są identyfikowane za pomocą nazw kolumn, ale za pomocą etykiet znajdujących się w sąsiedniej komórce w obrębie tego samego wiersza:
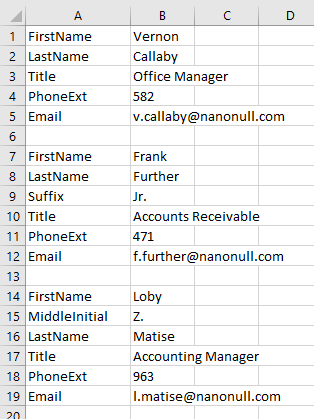
W tym przykładzie dane nie są nawet spójne pod względem struktury, ponieważ w jednym przypadku po nazwisku występuje przyrostek, a w innym – inicjał imienia środkowego.
Prawdopodobnym wymaganiem dotyczącym mapowania danych dla plików tego typu jest przypisanie zawartości komórek w kolumnie A jako nazw elementów XML, a zawartości komórek w kolumnie B jako wartości odpowiadających im elementów. Obecnie można to łatwo osiągnąć dzięki dynamicznemu mapowaniu nazw węzłów. Przyjrzyjmy się, jak to zrobić.
Dynamiczne uzyskiwanie nazw elementów XML
Zaczniemy od stworzenia bardzo prostego schematu XML dla celu mapowania, który używa elementu <xs:any> do zdefiniowania złożonego elementu

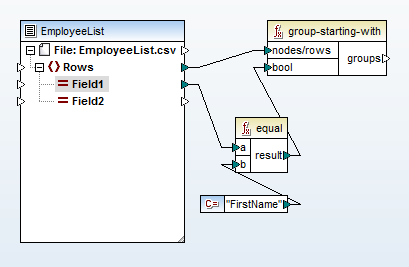
Rozpoczynamy proces mapowania, importując plik CSV i używając funkcji grupowania, która za każdym razem, gdy wartość "FirstName" pojawia się w kolumnie A pliku wejściowego, tworzy nowy element
Następnie wczytujemy docelowy schemat XML i klikamy prawym przyciskiem myszy na element
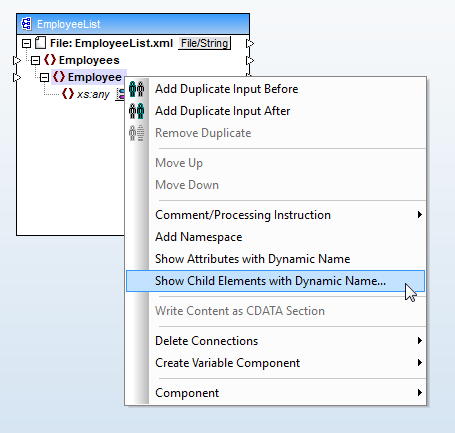
Wybierzemy opcję "Wyświetl elementy potomne o dynamicznej nazwie", która otworzy okno dialogowe, w którym wybierzemy "tekst" jako typ danych dla elementów potomnych. Dzięki temu zostaną wyświetlone nazwy węzłów i zawartość elementów potomnych elementu
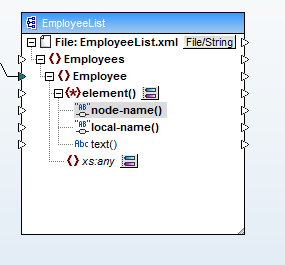
Teraz proces mapowania jest prosty: można mapować dane z pola Field1 (kolumna A pliku CSV) na nazwy elementów potomnych, a z pola Field2 (kolumna B) na zawartość tych elementów. Poniżej znajduje się ostateczne mapowanie danych:
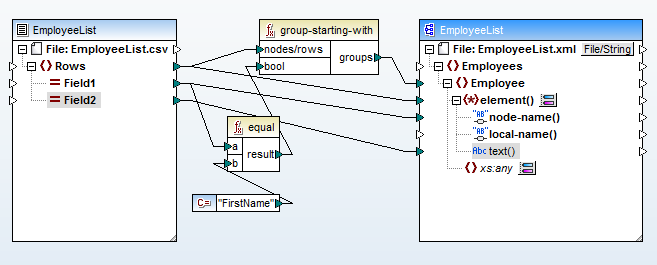
Funkcja "group-starting-with" znajdująca się na początku tworzy nowy element
Wynik działania powyższego odwzorowania wygląda następująco:
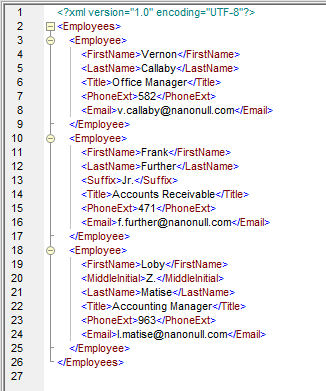
Zaleta mapowania danych, które wykorzystuje dynamiczny dostęp do nazw węzłów, polega na tym, że nie trzeba przeprowadzać szczegółowej analizy danych wejściowych w celu zidentyfikowania i przyporządkowania każdej możliwej nazwy elementu.
Rozważmy typową sytuację produkcyjną, w której akceptujesz wiele plików wejściowych z jednego lub więcej zewnętrznych źródeł i automatyzujesz proces mapowania za pomocą serwerów MapForce i FlowForce. Jeśli do systemu trafi plik wejściowy, który nagle zawiera nieoczekiwany element potomny – na przykład "OfficeLocation" lub "MailStop" – dane nie zostaną utracone.
Dynamiczne uzyskiwanie nazw atrybutów XML
Można również dynamicznie mapować nazwy atrybutów XML, co pozwala na tworzenie elementów i atrybutów docelowych w czasie rzeczywistym, bez konieczności ich wcześniejszego zdefiniowania.