MapForceは、ノード名への動的なアクセス機能を提供します
特に、構造が明確でないデータを取り扱う場合、データストリームの内容だけでなく、その構造要素もマッピングおよび変換したいという状況があります。MapForceは、XML要素のノード名、属性、またはテキストファイルのカラム(例えば、CSVファイルのコンテンツ)など、さまざまな要素を動的に参照し、それらをターゲットの要素にマッピングすることができます。
ノード名への動的なアクセスにより、事前に名前を知る必要がない、または特定する必要がないターゲット要素や属性を、その場で作成することができます データマッピング. この機能を使用すると、より汎用的で柔軟性があり、再利用可能なデータマッピングを作成できます。これにより、データモデルが変更された場合でも、手動での調整を大幅に減らすことができます。

以下に、非常に一般的なCSVファイルの形式の例を示します。この形式では、データフィールドが列名で識別されるのではなく、同じ行内の隣接するセルに記述されたラベルによって識別されます
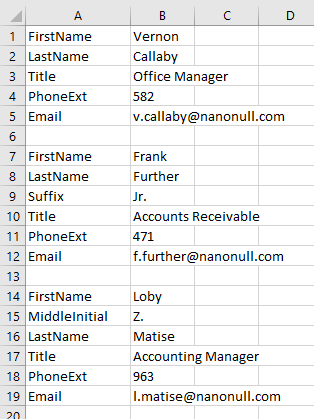
この例のデータは、一貫した形式で構成されていません。なぜなら、あるレコードには姓の後に接尾辞が付いているのに対し、別のレコードにはミドルネームのイニシャルが含まれているからです。
このようなファイルの場合、データマッピングの一般的な要件として、A列の各セルをXML要素の名前として、B列の各セルをそれぞれの要素に対応する値としてマッピングすることが挙げられます。現在では、ノード名の動的なマッピングにより、これは容易に実現できます。具体的な方法を見ていきましょう。
XML要素のノード名への動的なアクセス
まず、マッピングの対象となる非常にシンプルなXMLスキーマを作成します。このスキーマでは、<xs:any>要素を使用して、任意のサブ要素を持つ複雑な

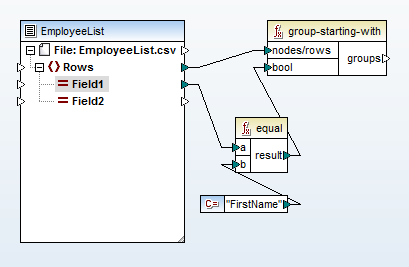
まず、CSVファイルを読み込み、グループ関数を使用して、入力データのA列に「FirstName」という文字列が現れるたびに、新しい
次に、対象のXMLスキーマを読み込み、
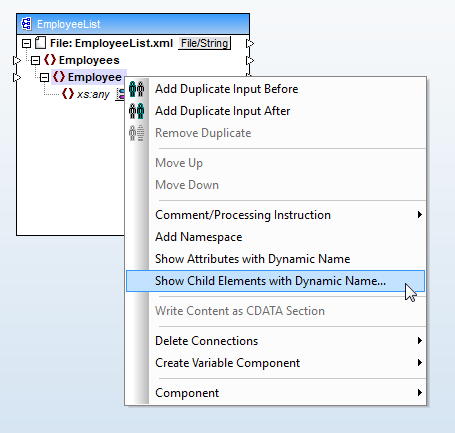
「子要素の動的名前を表示」というオプションを選択します。これにより、子要素のデータ型としてテキストを選択するためのダイアログが表示されます。この設定により、
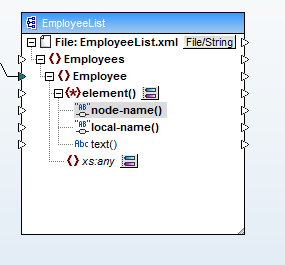
現在、CSVファイルのField1(A列)から子要素のノード名へのマッピング、およびField2(B列)から要素の内容へのマッピングは、簡単なプロセスで行うことができます。以下に最終的なデータマッピングを示します
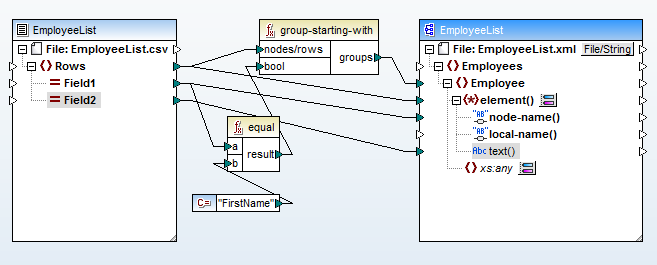
最上部に配置された「group-starting-with」という関数は、入力ファイル内で「FirstName」という文字列が検出されるたびに、新しい
上記の対応関係に基づいて生成される出力は、以下のようになります
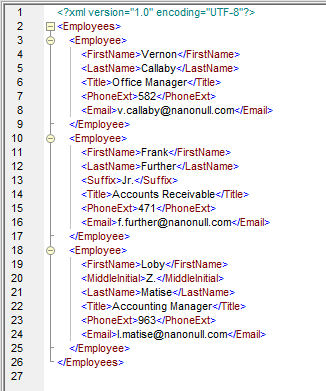
ノード名に対して動的なアクセスを利用したデータマッピングの利点は、入力データ全体を詳細に調査して、すべての可能な要素名を特定し、それらをマッピングする必要がないことです。
一般的なデータ処理のシナリオとして、複数の外部ソースから複数の入力ファイルを受け取り、MapForce ServerとFlowForce Serverを使用してデータ変換処理を自動化する場合を考えてみましょう。もし、予期せぬ子要素(例えば、"OfficeLocation"や"MailStop"など)が突然入力ファイルに含まれる場合でも、データが失われることはありません。
XML属性のノード名への動的なアクセス
また、XML属性の名前を動的にマッピングすることも可能です。これにより、事前にすべてを特定しなくても、必要に応じてターゲット要素や属性をその場で作成することができます。