Poznajcie Inline XBRL i pakiety taksonomii XBRL
Wraz ze wzrostem popularności języka XBRL (eXtensible Business Reporting Language) do raportowania finansowego na całym świecie, powstają nowe standardy, które mają zaspokoić potrzeby zarówno firm składających raporty, jak i programistów. Oferta firmy Altova, obejmująca produkty wspierające standard XBRL, obejmuje szeroki zakres standardów XBRL i jest regularnie aktualizowana wraz z pojawianiem się nowych specyfikacji.
Przyjrzyjmy się bliżej dwóm nowszym standardom XBRL – Inline XBRL i pakietom taksonomii XBRL – i przeanalizujmy, jak one działają.

XBRL osadzony w tekście (iXBRL)
Specyfikacja Inline XBRL opracowana przez organizację XBRL International rozszerza standard XBRL, mając na celu zwiększenie efektywności. Umożliwia ona firmom umieszczanie danych XBRL bezpośrednio w dokumencie HTML, zamiast przechowywania tych danych oddzielnie od raportu, który jest czytelny dla ludzi. To rozwiązanie zapewnia większą elastyczność i łączy zalety danych oznaczonych tagami z przyjaznym dla użytkownika sposobem prezentacji raportu: ludzie mogą zrozumieć informacje, po prostu wyświetlając je w przeglądarce internetowej, a oprogramowanie może przetwarzać raport w celu automatycznej analizy.
Korzystając z Inline XBRL, przygotowujący dane wbudowują informacje w formacie XBRL bezpośrednio w kod HTML w sposób ustandaryzowany, co umożliwia łatwe wyodrębnienie tych danych do dokumentu XBRL, w razie potrzeby, a następnie przesyłają pojedynczy dokument zawierający informacje finansowe.
Dla organizacji korzystających z tej specyfikacji, program XMLSpy (wersja 2017 lub nowsza) umożliwia walidację plików Inline XBRL.
Ponieważ dane w formacie XBRL zawarte w dokumencie iXBRL nadal muszą zostać wyekstrahowane do dokumentu instancji XBRL w celu dalszej obróbki, program XMLSpy oferuje tę funkcjonalność za pomocą polecenia "Transform Inline XBRL".
To narzędzie wyodrębnia dane Inline XBRL z aktualnego raportu HTML i generuje jeden lub więcej dokumentów XBRL zawierających wyodrębnione dane. Wygenerowane dokumenty XBRL są otwierane w nowych oknach i można je zapisać do pliku, edytować itp.
Mapowanie danych w formacie iXBRL
Wsparcie dla tego standardu jest również dostępne podczas mapowania danych XBRL w programie MapForce, gdzie pliki zawierające Inline XBRL można dodać jako komponenty źródłowe do mapowania na bazy danych relacyjnych lub inne formaty danych.
Generowanie raportów XBRL osadzonych w tekście
Dla organizacji pracujących z formatem iXBRL, program StyleVision ułatwia projektowanie i generowanie raportów HTML. Dzięki intuicyjnemu procesowi projektowania raportów, opartemu na przeciąganiu i upuszczaniu elementów, użytkownicy mogą szybko i łatwo tworzyć atrakcyjne, czytelne dla człowieka raporty w formacie iXBRL.

Wysokowydajna walidacja danych w formacie iXBRL
Na koniec, Inline XBRL dołącza się do długiej listy specyfikacji XBRL, które można weryfikować za pomocą serwera RaptorXML+XBRL w celu szybkiego przetwarzania dużych ilości danych. W pierwszym etapie weryfikacji, wykonanie polecenia przekształca raport na format XBRL, wyodrębniając dane Inline XBRL i weryfikując wygenerowany dokument instancji XBRL w odniesieniu do odpowiedniej taksonomii XBRL. Wygenerowaną instancję XBRL można opcjonalnie zapisać.
Pakiety taksonomii XBRL
Taksonomie XBRL zazwyczaj składają się z wielu powiązanych dokumentów, które często są pakowane razem w plik ZIP dla wygody. Nowa specyfikacja XBRL, o nazwie Pakiety taksonomii XBRL, została stworzona, aby ułatwić pracę z tymi dokumentami.
Specyfikacja pakietu taksonomii XBRL określa standardowy format i lokalizację pliku w archiwum ZIP, który zawiera opis pakietu oraz punkt wejścia. Pakiet taksonomii zawiera również plik katalogu XML, który mapuje URI na lokalizacje plików offline'owej taksonomii, dzięki czemu taksonomia jest łatwo dostępna offline dla aplikacji, bez konieczności dodatkowej konfiguracji przez użytkowników.
Mamy wielu klientów, którzy już korzystają z pakietów taksonomii XBRL, a od wersji 2017 zarówno program XMLSpy, jak i serwer RaptorXML+XBRL obsługują weryfikację zawartości tych pakietów.
Po pobraniu pakietu taksonomii, można go zarejestrować w programie XMLSpy, aby automatycznie identyfikować i wykorzystywać plik katalogu punktu wejściowego tego pakietu. Pliki katalogów aktywnych pakietów będą następnie wykorzystywane do lokalizowania zasobów, przeprowadzania walidacji oraz innych operacji.
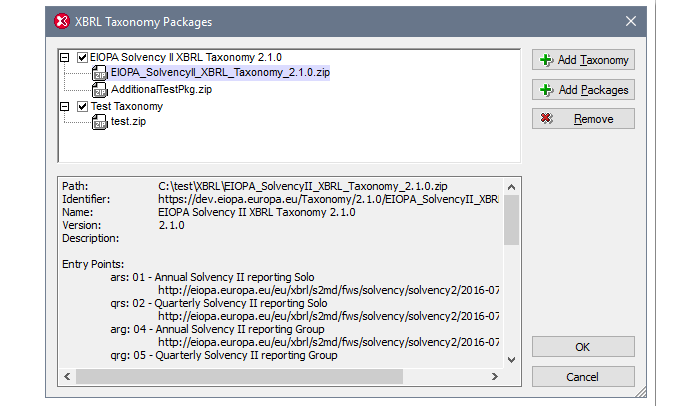
Po dodaniu, pakiety taksonomii będą dostępne dla wszystkich produktów Altova obsługujących standard XBRL na komputerze programisty (np. MapForce, StyleVision, itp.).
Wraz z pojawianiem się nowych standardów XBRL, należy spodziewać się, że zostaną one dodane do kompleksowego wsparcia oferowanego przez narzędzia Altova, które umożliwiają edycję, generowanie, konwersję, renderowanie i walidację danych XBRL, aby zaspokoić różnorodne potrzeby podmiotów składających raporty oraz organów regulacyjnych.
Dowiedz się więcej o narzędziach Altova XBRL i pobierz bezpłatną wersję próbną w dowolnym momencie.