データマッピング:バイナリオブジェクトの処理
データベースにおけるバイナリオブジェクトの管理は困難です。それらはサイズが大きく、内容が人間にとって読み取りにくく、また、制御文字と誤解される可能性のあるデータが含まれていることがあります。バイナリオブジェクトのデータ型名である「BLOB」自体が、多くのデータベース管理者がそれらを好まないことを反映しています。リレーショナルデータベースが登場する以前、BLOBは「定義が曖昧または不定形なもの」と定義されていました
Altova MapForceは、数々の賞を受賞している、 あらゆるデータ形式間の変換と統合を可能にする、グラフィカルなデータマッピングツール, この機能は、あらゆる主要なリレーショナルデータベースとの間で、バイナリオブジェクトのデータマッピングを簡単に行うための機能を提供します。画像、PDFファイル、ビデオファイル、またはその他のバイナリデータなど、様々なデータをマッピングできます。具体的な例を見てみましょう。

MapForceには、バイナリオブジェクトとデータベース間のマッピングを行うための、組み込み関数として「read-binary-file」と「write-binary-file」が含まれています。この記事では、MapForceのオンラインヘルプに掲載されている「read-binary-file」の例を拡張し、様々なバイナリオブジェクトをリレーショナルデータベースに挿入するための完全なマッピングを作成します。
以下に、データベースに画像を取り込む方法を示すサンプルコードを示します
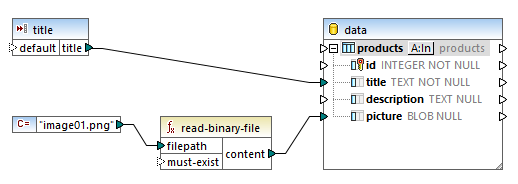
このマッピング処理では、ローカルファイルである「image01.png」をデータベースのテーブルに挿入します。データベースの構造を見ると、画像に関するメタデータが別の列に格納されており、これらの情報を利用して同じ画像を検索できることがわかります。大量のバイナリデータファイルを、後で検索する方法がない状態でデータベースに格納するのは避けるべきです。
今回の利用事例では、マーケティング部門が複数の製品をサポートする様々なバイナリファイルを管理するために、SQLiteデータベースを作成します。このバイナリデータには、ロゴ画像ファイル、製品データシートのPDF、製品の使用状況を示すスクリーンショット、写真、ビデオファイルなどが含まれる可能性があります。
まず、挿入したい情報を記述するための、シンプルなCSV形式のテキストファイルから始めます
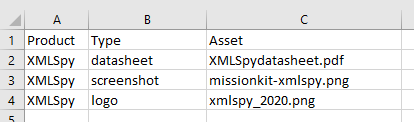
このプロジェクトが完了する頃には、データベース内に数十個、あるいは数百個ものデータが蓄積されている可能性があります。後で特定のデータを抽出する際に、データ種類の名前は、検索を行う上で非常に重要なメタデータとなります。しかし、もしデータ種類の列にある個々の項目に誤字や不整合があった場合、膨大なバイナリデータが孤立し、復元不可能になってしまう可能性があります。
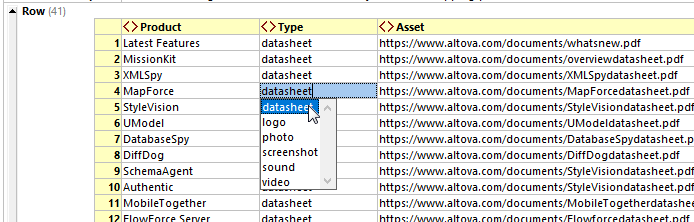
資産の種類を特定の一覧から選択できるように、CSVファイルをXMLSpyに取り込み、XMLスキーマを生成することができます。その際、スキーマ内の「Type」要素は、あらかじめ定義された一覧から選択されるように設定します。こうすることで、経験の浅いマーケティングインターンでも、資産の一覧を簡単に作成できるようになります XMLSpy のグリッド表示機能. 「タイプ」フィールドは、指定された形式で入力する必要があります
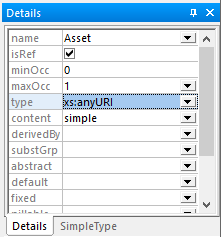
XMLスキーマに製品名のリストを追加することも可能ですし、少なくとも「Product」要素が存在することを必須にすることもできます。さらに、アセットの型をxs:anyURIに設定することで、ファイルへの参照を強制することも可能です。以下に、XMLSpyのスキーマビューで表示される「詳細」ヘルプウィンドウの例を示します。この例では、アセット要素のデータ型設定が示されています
MapForceにおいて、CSV形式またはXML形式のデータソースからデータをマッピングする場合、バイナリオブジェクトのマッピング方法は基本的に同じです。
まず、新しいMapForceを開き、資産リストとデータベースのテーブルをデータマッピングの対象として設定します。
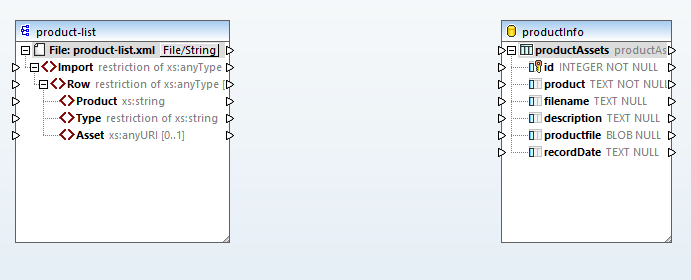
データベースの分析には、DatabaseSpyを使用しました 新しいSQLiteデータベースのテーブルを作成します MapForceヘルプに記載されている例を少し修正しました。製品名を入力する列を「製品」とし、資産の種類を「説明」列に入力します。「記録日」列には、各バイナリオブジェクトの作成日を記録します。
それでは、MapForceのヘルプに記載されているように、ID列を自動採番に設定し、ソースとターゲット間の簡単な関連付けを行います
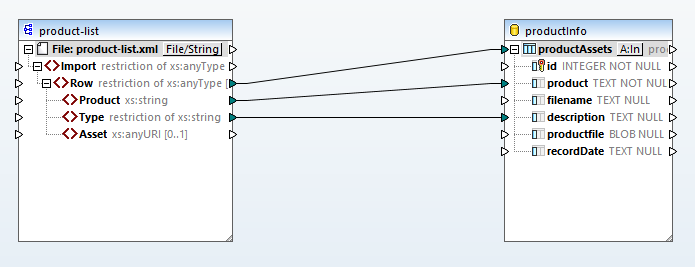
ソースマップから取得した「製品」と「タイプ」の情報は、データベースの特定の列に直接マッピングされます。また、「行」要素のマッピングは、入力データの各行に対して、新しいデータベースレコードを作成するように指示します。
それでは、データベース内のBLOB(バイナリラージオブジェクト)に、バイナリデータを格納する方法について説明します
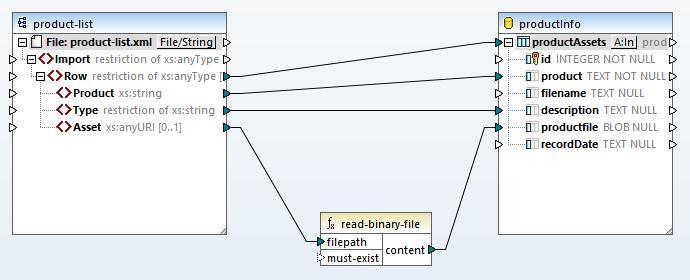
組み込みのMapForce関数「read-binary-file」は、ソースの「Asset」要素に指定されたファイル名を使用して、バイナリデータを読み込み、BLOB(Binary Large Object)を作成します。この関数は、ソースファイル名に関わらず、常にソースデータをbase64エンコードされたバイナリデータとして扱います。
マッピングを完了するためには、アセットからファイル名を抽出して、保存日を記録するための連携が必要です
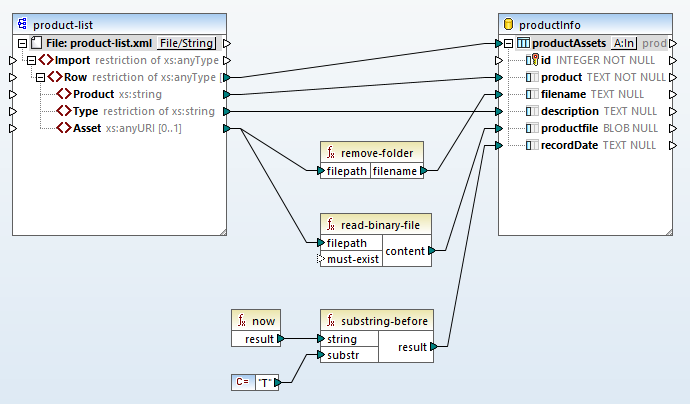
「フォルダを削除」機能は、ローカルファイル、ネットワークファイル、またはウェブ上のファイルに関わらず、パスから自動的にファイル名を抽出します。
now関数は、マッピングの実行日時を記録しますが、今回は日付のみが必要なので、substring-before関数を使って時刻部分を削除しました。
マッピング画面の下部にある「実行」ボタンをクリックすると、マッピング処理が実行され、SQLスクリプトが生成されます
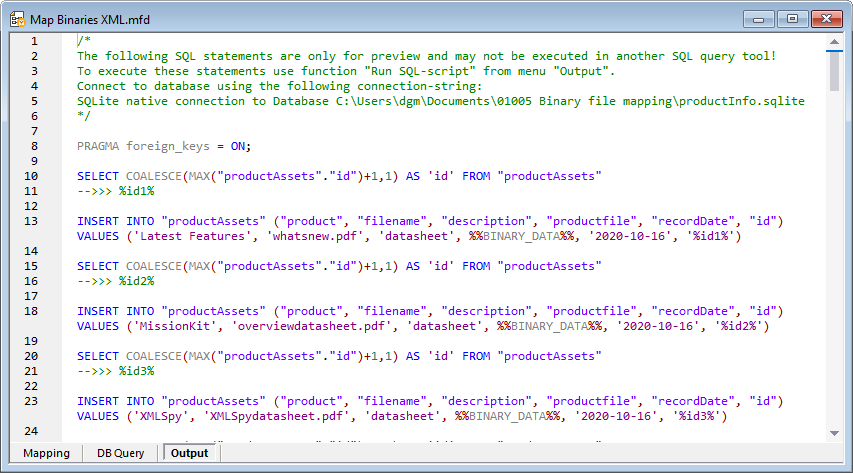
このスクリプトは、現時点での結果を確認するためのプレビュー版です。メインの出力メニューから選択することで、スクリプトを実行できます
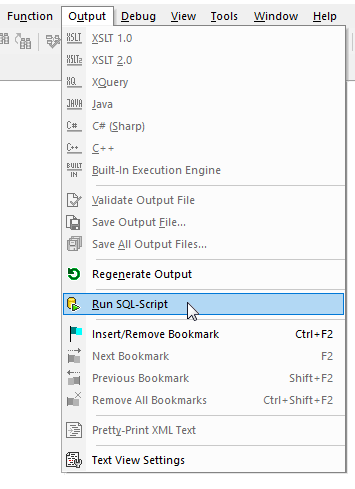
スクリプトの実行結果が表示されます
データベースに接続し、その結果をMapForce上でさらに検証するために、「DBクエリ」ボタンをクリックします
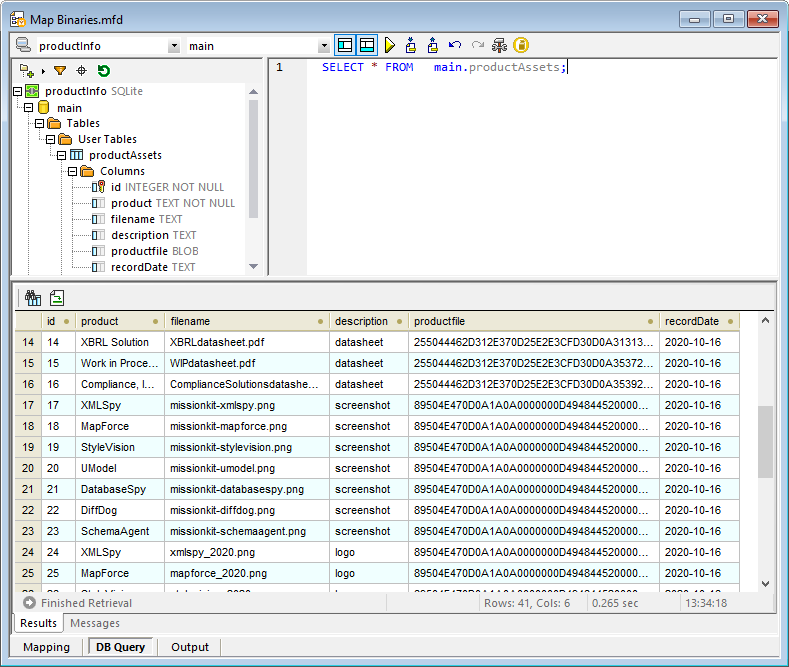
製品ファイル列に表示されるBLOBデータからは、あまり多くの情報を得られませんが、他の列には、各資産に関する有用なメタデータが記載されています。
ある [data-mapping-binary-objects-part-2|追記 データマッピングのデモンストレーションを行い、バイナリオブジェクトをどのように対応させるかを示します [データベースから資産情報を抽出する]] そして、それらを元の形式で保存します。もしどうしても待ちきれない場合は、 無料トライアル版をダウンロードする 独自のデータマッピング、変換、およびデータ加工プロジェクトを開始するために、チュートリアル、ヘルプ、そしてさらに多くのサンプルをご用意しています!