データベースのマッピングと、データベース関連のエラー処理
重要なビジネスプロセスは、信頼性の高いデータに依存しており、データベース管理者やその他のデータアナリストは、データベーステーブルに格納されている情報の正確性を確信する必要があります。自動化されたETL(抽出、変換、ロード)処理やその他のデータベースインポート作業中に、処理の成功を脅かす不正なデータが検出される可能性があります。Altova MapForceには、エラーが発生した場合に影響を受けたデータをロールバックするデータベースのエラー処理機能が搭載されており、オプションでデータベースのマッピング処理を継続することができます。
例えば、単一のレコードにエラーが発生した場合でも、マッピングの実行全体が停止する必要はありません。特定のデータベースの制約により、無効なデータが挿入または更新されるのを防ぐ場合などが該当します。

データベースの例外処理機能を有効にすると、データベースコンポーネントに対するすべての変更が、エラー発生時にロールバック可能なトランザクション内に格納されます。ユーザーは、エラー発生時に、残りのマッピング処理を続行するか、それ以上の処理を停止するかを選択できます。トランザクションは、データベースコンポーネントレベル、テーブルレベル、またはストアドプロシージャに対して有効にすることができます。
例外処理は、データベースの出力ログ(追跡機能)と組み合わせることで、自動処理中に発生するエラーを記録することができます。
さあ、どのように機能するか見てみましょう。
MapForceのサンプルフォルダには、トランザクション処理とロールバックの例を示すデータベースのマッピングとSQLiteデータベースが含まれています。もちろん、これらの機能は、主要なリレーショナルデータベースすべてでサポートされており、一般的なタスクとして、PostgreSQLからSQLiteへの変換、XMLをSQL Serverにマッピングする、JSONをAccessに変換するなど、さまざまな用途に利用できます。
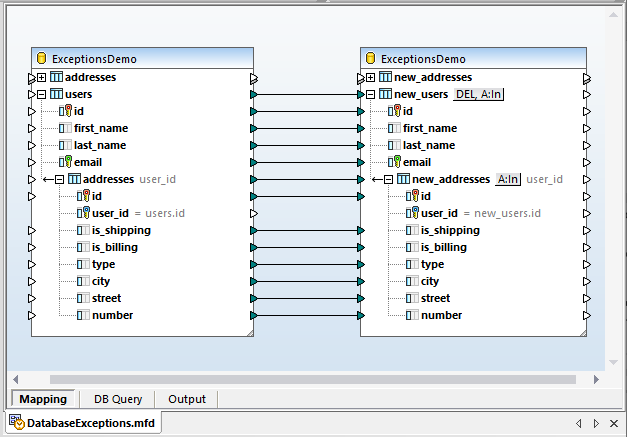
このデータ連携処理では、2つのデータベーステーブルからデータを抽出し、構造がほぼ同じ新しいテーブルに格納します。ただし、1つの重要な違いがあります。ターゲットデータベースの「new_addresses」テーブルでは、「is_shipping」と「is_billing」のフィールドにNULL値を設定することは許可されていません。一方、ソースデータベースの「addresses」テーブルでは、これらのフィールドにNULL値を設定することが許可されていました。つまり、データ連携処理の実行中に、これらのフィールドに値が欠落している場合、エラーが発生します。
ここでは、データベースの例外処理オプションを使用して、異なる方法でエラーを管理する3つの状況について解説します
最初のエラーが発生した場合、すべての変更を元に戻し、マッピング処理を停止します
エラーが発生したトランザクションのみをロールバックし、処理を続行します
上位のトランザクションをロールバックし、処理を続行します
すべての変更を元に戻す
最初の状況では、マッピング実行中にエラーが発生した場合でも、対象データベースを完全に変更しないように、データベースの例外処理を適用したいと考えています。このオプションを実装するには、対象データベースのコンポーネントのプロパティダイアログを開き、トランザクション処理を有効にします
![]()
マッピングを実行するには、マッピング画面の下部にある「出力」ボタンをクリックしてSQL実行スクリプトを生成し、その後、スクリプトウィンドウの上部にある「出力」メニューから「SQLスクリプトの実行」を選択します
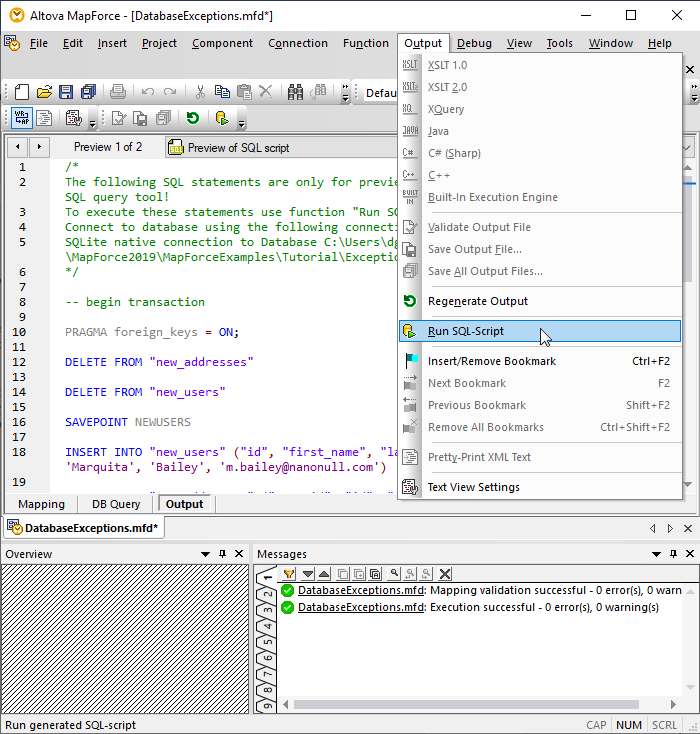
実行中に最初のエラーが発生した場合、ダイアログが表示され、そこで、先ほど選択したトランザクション設定を確認したり、変更したりすることができます
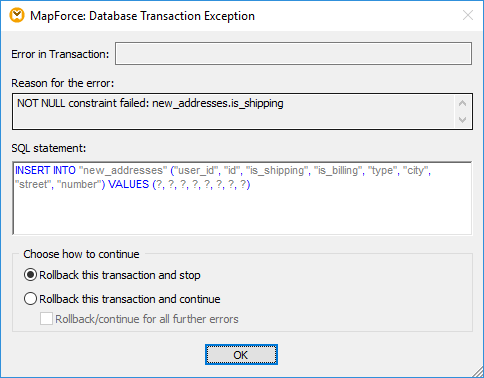
設定を元に戻すために、単に「OK」をクリックします。マッピングの実行が停止し、メッセージウィンドウにエラー内容が表示されます
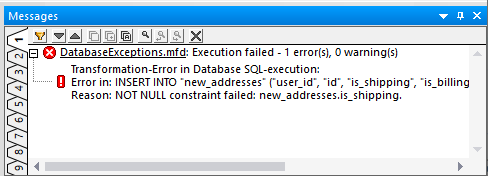
組み込みのMapForce DB Queryウィンドウを使用して、new_usersとnew_addressesのテーブルを選択し、内容を確認することができます。どちらのテーブルも空であると予想されます
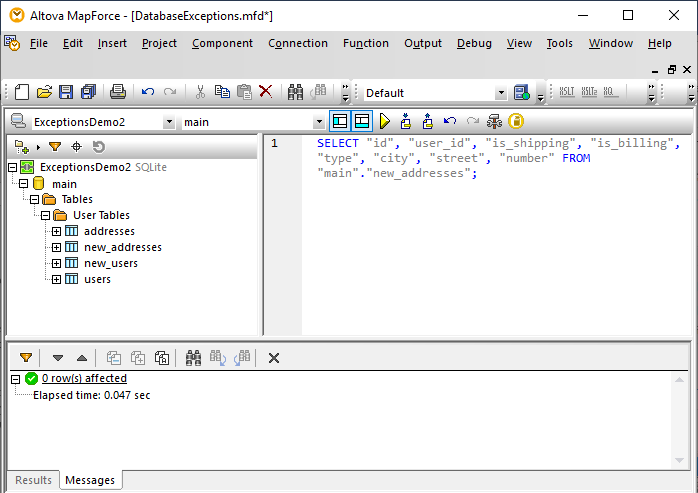
これにより、エラーが発生する前に挿入されたデータが、ロールバックによってデータベースから削除されたことが確認されます。言い換えれば、エラー前のデータはデータベースから取り除かれたことになります。
MapForce Serverによる自動実行中、コンポーネントのトランザクション設定は、中断することなく適用されます。
トランザクションを一つ戻し、処理を続行します
例えば、データベースに大量の外部データを取り込む必要がある場合を考えてみましょう。例えば、1万件以上のレコードを取り込む必要があるとします。外部ファイルの内容が正しいと期待していますが、もし数件のレコードに誤ったデータが含まれていた場合、正常なレコードはすべてインポートし、エラーの内容を記録したいと考えられます。これは、上記のリストにあるデータベースの例外処理のケース2であり、さらに、以前の投稿で説明したデータベースの追跡機能と組み合わせたものです。
新しいテーブル「new_addresses」に対して、このデータベース例外処理オプションを適用するには、テーブル操作ボタンをクリックし、以下の設定を選択します
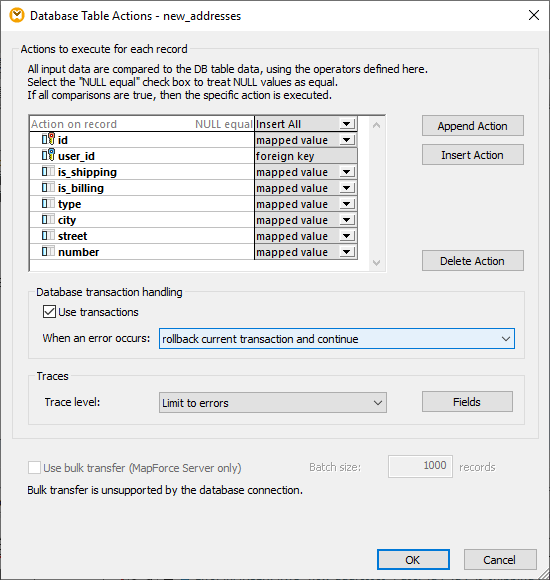
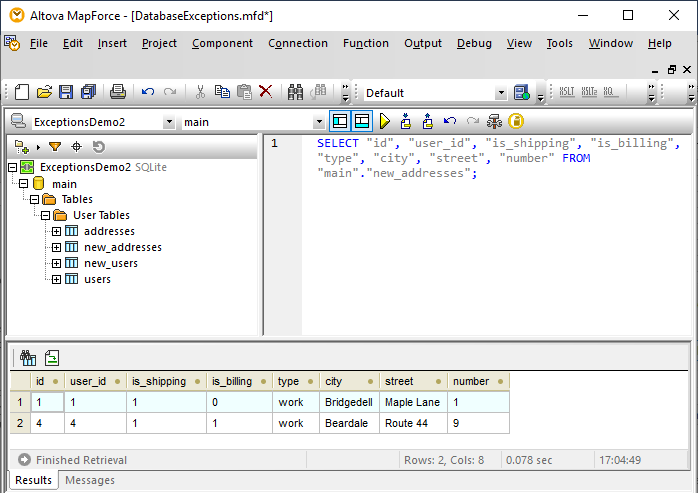
これで、新しいSQLスクリプトを生成し、上記で示した「SQLスクリプトの実行」コマンドを使って実行できます。メッセージウィンドウには、いくつかのエラーが記録されます。DBクエリウィンドウでSQLクエリを再度実行すると、正常にマッピングされたデータを確認できます
さらに、XML形式の追跡ファイルを作成しました。以下に示されている画像は、XMLSpyで表示されるその一部です XMLエディタ エラーが発生する可能性のある箇所が、54行目にハイライト表示されています
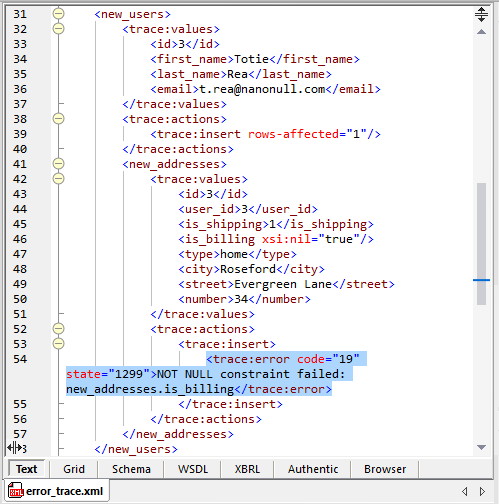
このようなトレースファイルがあれば、1万件のデータの中から、わずかながら問題のあるレコードを簡単に見つけて修正することができます。
上位のトランザクションをロールバックし、処理を続行します
データベースのエラー処理における状況3は、このビジネス要件を満たします。具体的には、住所の登録に失敗した場合、関連するユーザーレコードの登録も行わないようにしますが、それ以外のマッピング処理は継続されます。
この例については、MapForceに自動的にインストールされるオンラインヘルプや、ここに示されているすべてのデモファイルで詳細に説明されています。ぜひ、無料トライアル版をダウンロードして、そのシナリオを試してみてください。または、すぐにデータベースの例外処理を独自のデータベースマッピングに実装することも可能です。