PDFマッピングのためのデータ抽出
MapForceは、Altovaが開発した受賞歴のあるデータマッピングツールであり、データ統合およびETLワークフローにおいて、PDF形式の入力に対応しています。MapForce PDFエクストラクターを使用すると、PDFデータから構造化された形式で情報を抽出するためのルールを簡単に定義でき、抽出したデータをExcel、XML、JSON、データベースなど、他の一般的な形式にマッピングして利用することができます。
それでは、その仕組みについて見ていきましょう。

PDFファイルからデータを抽出する方法
PDFファイル形式は、現在、様々な分野でのコミュニケーションにおいて、ほぼ普遍的に利用されています。その理由は、どのプラットフォームやデバイスでも一貫した表示を提供できるからです。PDFファイルは、テキスト、画像、グラフ、表など、人間が読みやすいように構成された複数の要素を組み合わせ、多様な書式設定オプションを提供します。
しかし、PDF形式はデータをユーザーフレンドリーな方法で提示するのに適していますが、他のビジネスシステムとの連携に必要な、データを効率的に抽出するための組み込み構造がありません。これは、多くの場合、一般的な要件となります。従来のデータ抽出ツールは、PDFファイルから正確に情報を抽出することが難しく、特に複雑なレイアウトや多様な書式設定が用いられている場合に問題が発生しがちです。その結果、エラーや非効率が生じ、抽出されたデータを修正するために手作業での介入が必要になることがあります。
これらのPDFデータ統合の課題に対処するため、AltovaはMapForce PDF Extractorという、視覚的なツールを開発しました。このツールを使用すると、PDFファイルから構造化されたデータを抽出するためのルールを簡単に定義できます。
このハウツー動画で、MapForce PDFエクストラクターの仕組みを学びましょう
MapForce PDF抽出機能の使い始めとして、抽出したいデータの形式に合わせたサンプル文書を読み込むのが最適です。これは、請求書、データ入力フォーム、レポート、顧客情報など、さまざまな種類の文書が考えられます。もしPDFが別の文書のスキャンデータである場合は、以下の手順で対応できます まず、光学文字認識(OCR)から始めます そのデータを解析できるよう抽出し、抽出ツールで利用できるように準備します。
PDF抽出ツールでは、サンプル文書が表示されるため、構造化された方法でデータを抽出するためのテンプレートとルールを定義することができます。MapForce PDF抽出ツールのシンプルな設計により、クリックやドラッグ&ドロップ機能を使って、PDF文書の構造を視覚的に簡単に指定できます。
PDFの表示領域の隣には、スキーマ表示領域があり、ここでPDFファイルがどのように解析され、データが抽出されるかを示すツリー構造が表示されます。
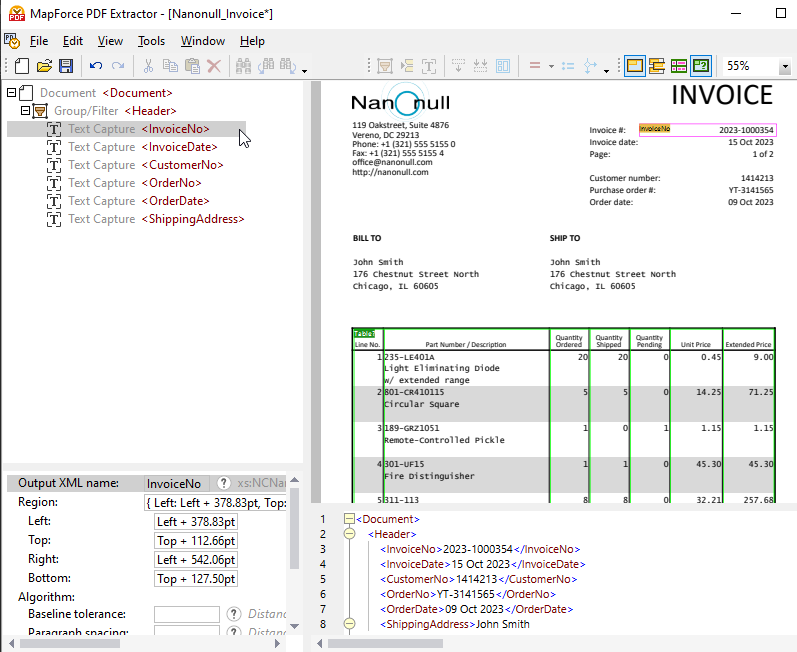
プロパティパネルを使用すると、必要に応じてプロパティを定義したり、数式を計算したりすることができます。PDFドキュメントの表示画面の下部には、出力パネル(上記参照)があり、ここで計算結果のプレビューを確認できます PDFデータ抽出 定義された特性と抽出ルールに基づいて、処理が行われます。その結果は、XMLドキュメントとして出力され、XMLタグによって構造が示されるとともに、抽出対象のファイルの内容が実際に表示されます。
ドキュメントの一部をスキーマツリーに追加するには、対象の領域をハイライトし、右クリックしてテキストの切り取りを行います。
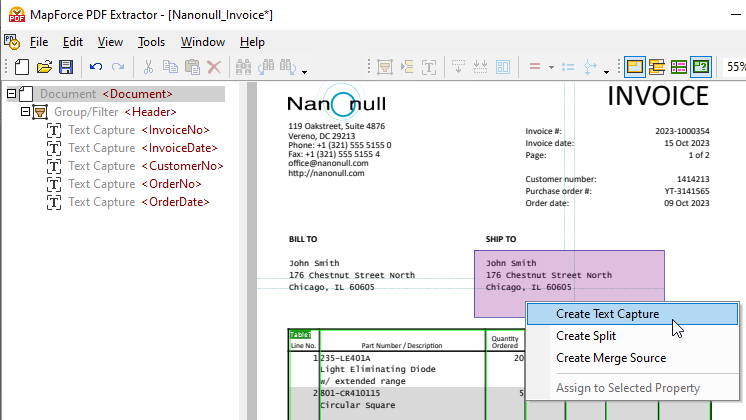
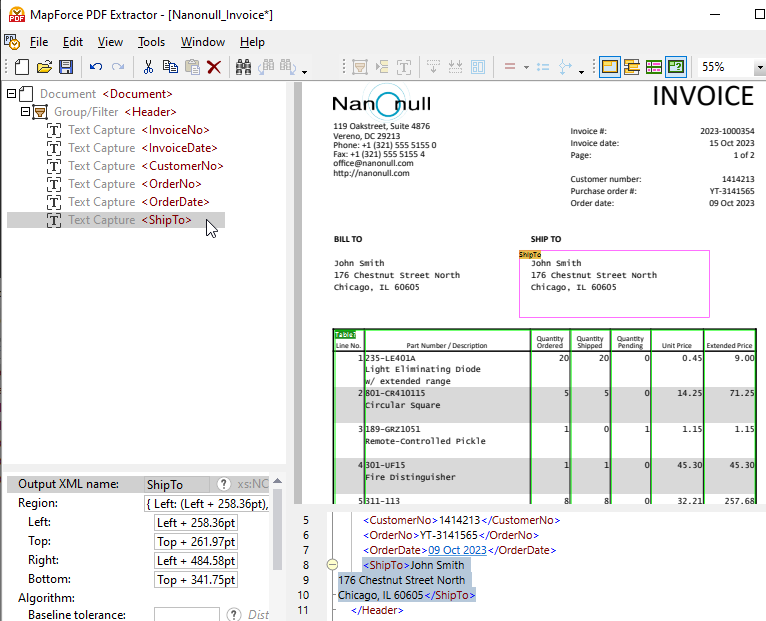
作成された新しい要素を、ツリー構造内の目的の場所にドラッグし、分かりやすい名前を付けてください。
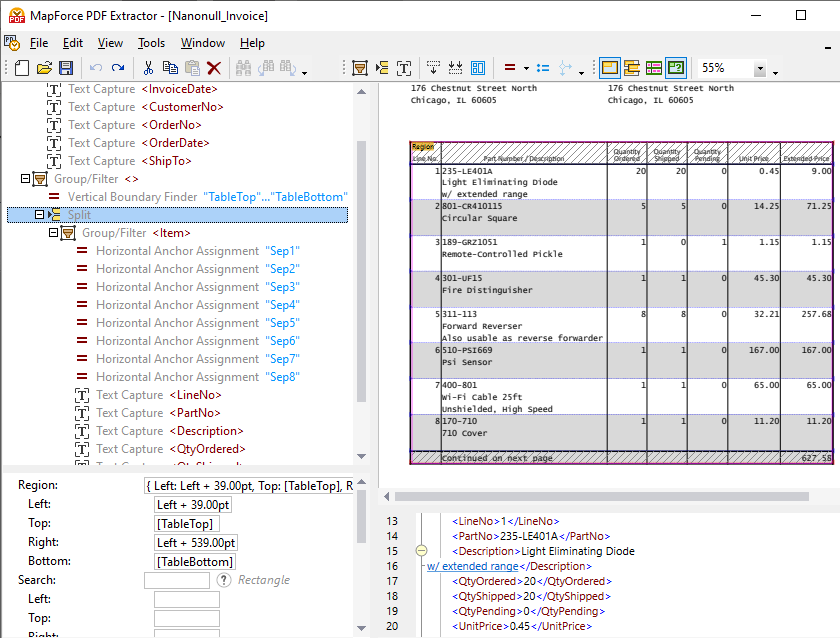
MapForce PDF Extractorには、手動でデータ抽出ルールを定義する機能に加えて、強力な提案機能が搭載されています。この機能は、ドキュメント内の一般的な要素を自動的に識別し、その構造を検出しようとします。例えば、この提案機能は、ドキュメント内に存在する表を識別し、必要に応じて自動的に抽出することができます。スキーマペインにある分割演算子を使用することで、表を適切に個別の行に分割する方法を定義できます。提案機能は、分割のための境界線や線を検出したり、一定の距離に基づいて分割したり、背景色の変化を検知したりすることができます。これらの設定は、PDF表示ペインでプレビューすることができます。同時に、提案機能は、列やヘッダーテキストも識別し、必要に応じて調整することができます。上記動画でその様子を確認できます。
スキーマツリー内の任意のオブジェクトをクリックすると、PDFドキュメントの表示において、そのオブジェクトに対応する構造とデータ抽出ルールが強調表示されます。
地図のPDFファイルを他の形式に変換する
MapForce PDF抽出機能におけるテンプレートが完成したら、それをMapForceのデータマッピングプロジェクトに追加し、PDFデータを効率的に他の対応形式に変換できます。ソースノードとターゲットノードをドラッグ&ドロップで関連付け、組み込みのデータ処理関数ライブラリを活用して、PDFデータを変換します。一般的な用途としては、以下のようなものがあります
PDFファイルをExcel形式に変換する
PDFファイルをXML形式に変換する
PDFファイルをJSON形式に変換する
PDFファイルをSQLデータベースまたはNoSQLデータベースシステムに変換する
PDFファイルをEDIメッセージに変換する
PDFファイルをCSV形式またはテキスト形式に変換します
上記に加えて、MapForceは、データのマッピング処理を連鎖的に行う機能や、複数のソースおよびターゲットデータ構造に対応しています。
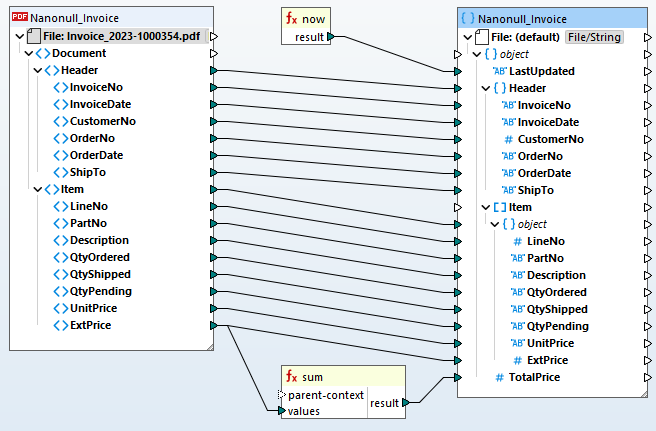
MapForceは、お客様が定義されたデータマッピングに基づいて、データを瞬時に変換します。また、MapForce Server Advanced Editionをご利用いただくことで、PDFファイルの繰り返し変換やETLパイプラインの構築が可能です。これにより、企業はデータの統合を自動化し、既存のシステム、データベース、およびワークフローにPDFデータをシームレスに組み込むことで、業務プロセスを効率化することができます。
MapForce PDFエクストラクターの利用を開始するには、Altovaのウェブサイトから無料トライアル版をダウンロードしてください。