MapForce 2009の主な変更点:
まるでXBRLやHL7について何ヶ月も書いていたかのようですね…。 今回は、その話題から少し離れて、MapForceのv2009リリースで追加された、その他の重要な新機能についてお話ししましょう。確かに、これらの機能の中には、多次元のXBRLデータとのマッピングを可能にするために必要不可欠なものもありますが、それらはインタラクティブな財務データレポートにとどまらず、MapForceにおけるXML、データベース、フラットファイル、EDI、Excel 2007、そしてWebサービスデータのマッピングといった、より広範な機能にも貢献しています。
データマッピングのためのカスタム関数
MapForceの機能は、マッピングにカスタムのデータ処理レイヤーを追加し、出力構造を再構成したり、さらに内容をリアルタイムで操作したりすることができます。バージョン2009では、すでに充実したMapForceの関数ライブラリに、グループ化、一意な値の抽出、および条件付きの位置指定機能を新たに追加しました。**グループ化機能**は、XSLT 2.0、Java、C#、およびC++でのコード生成に使用でき、共通の値に基づいてソースデータを効果的に再構成することができます
- group-by:出力ドキュメント内のデータを、指定された共通の値(グループ化キー)に基づいて再構成します
- group-adjacent:アイテムの交互に並んだシーケンスに対してグループ化を適用し、共通の値を持つアイテムを同じグループに割り当てます
- group-starts-with: 指定されたパターンに基づいて新しいグループを開始し、そのパターンに一致する別の項目が見つかるまで、以降のすべての項目を同じグループに分類します
- group-ends-with:指定されたパターンに基づいて新しいグループを終了し、その後のすべての項目を同じグループに分類します。別の項目がそのパターンに一致するまで、この処理が続きます
**distinct-values関数**は、データフィルタリングの機能で、簡単に言うと、マッピング結果を出力する際に、入力値の重複を自動的に無視します。
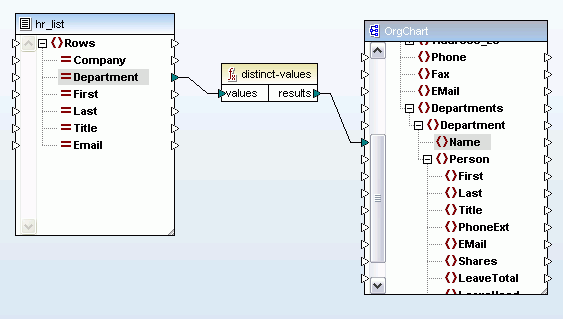
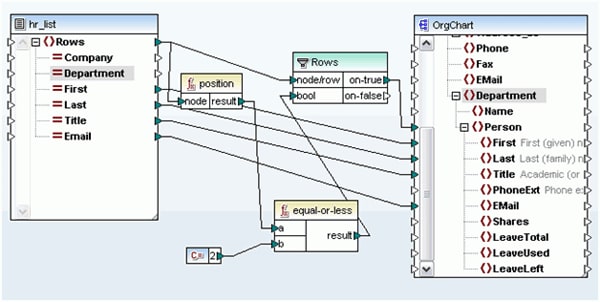
MapForceには、予測機能が新たに搭載されました 位置 入力ドキュメント内のデータが配置されている位置に基づいて、データをフィルタリングできる機能です。例えば、以下に示す設定では、ソースドキュメントに記載されている最初の2人に関するデータのみが返されます。
拡張データベースサポート機能
ユーザーの皆様へ データベースのマッピングを作成する MapForce 2009では、Microsoft SQL Server 2008、Oracle 11g、およびPostgreSQL 8といった追加のデータベースに対する、より高度な対応が可能になりました。また、SQL Server上のXMLフィールドのマッピングもサポートしています。ネイティブでサポートされているデータベースは以下の通りです
- Microsoft® SQL Server® 2000、2005、2008
- IBM DB2® バージョン8、9
- IBM DB2 for iSeries® バージョン5.4
- IBM DB2 for zSeries® バージョン8、9
- Oracle® 9i、10g、11g
- Sybase® 12
- MySQL® バージョン4、5
- PostgreSQL 8
- Microsoft Access™ 2003、2007版
- その他にも。 または、その他
データマッピングに関するドキュメント
データマッピングに関するドキュメントを自動生成する機能は、大規模なデータ統合プロジェクトにおける共同作業を大幅に容易にします。これらのプロジェクトには、多くの場合、さまざまな設計者、開発者、専門家、そして関係者が関わります。
ノードを特定するためのダイアログを見つける
さて、個人的におすすめの機能をご紹介します。それは、新しい検索機能です。これは、一見すると非常にシンプルで、取るに足らない機能に思えるかもしれません。しかし、XBRLやEDIといった、大規模で複雑な多層構造のデータを取り扱うようになったことがある方にとっては、その便利さが際立ちます(また、そういう話になってしまいましたね!)。
MapForce v2009に搭載された新機能の完全なリストをご覧ください。そして、いつものように、Altovaはユーザーからの要望に基づいて、MissionKitのすべてのツールに新しい機能を追加しています。ですので、ぜひご意見をお寄せください!