Jak uzyskać wydajność przetwarzania serwera wewnątrz środowiska programistycznego (IDE)
Nic tak nie przerywa procesu tworzenia oprogramowania, jak oczekiwanie na przetworzenie zbioru plików – jednak ten etap jest nieunikniony podczas pisania, testowania i debugowania kodu XSLT i XQuery.
Oprócz oferowania narzędzia XSL Speed Optimizer, przez wiele lat ciężko pracowaliśmy, aby procesor w programie XMLSpy był jak najszybszy. Mimo że jest on już bardzo szybki, jego działanie wciąż ogranicza się do wykorzystania jednego rdzenia procesora w komputerze programisty – ale już nie dłużej.

Teraz możesz wykorzystać serwer RaptorXML w swojej sieci, aby przyspieszyć procesy transformacji XSLT i wykonywania zapytań XQuery – bezpośrednio w programie XMLSpy. Ponieważ silnik RaptorXML został zaprojektowany z myślą o przetwarzaniu równoległym, pozwala on wykorzystać zwiększoną przepustowość i efektywne wykorzystanie pamięci, jakie oferują komputery wieloprocesorowe i wielordzeniowe.
Łatwo połączyć XMLSpy z jednym lub więcej serwerów RaptorXML w Twojej sieci. W programie XMLSpy otwórz menu Narzędzia i wybierz: Zarządzanie serwerami Raptor aby dodać i skonfigurować szczegóły dotyczące Twojego serwera.
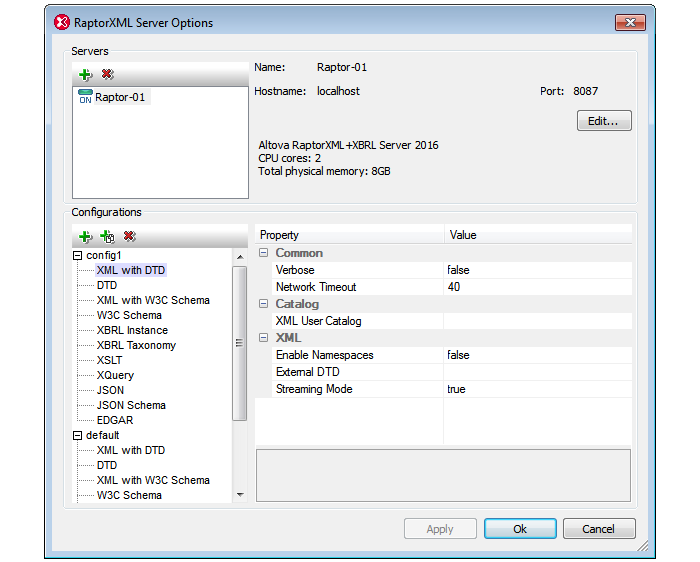
Po skonfigurowaniu tego, można rozpocząć Wydajna transformacja danych przy użyciu języków XQuery lub XSLT klikając prawym przyciskiem myszy na wybraną w oknie projektu XMLSpy, a następnie wybierając Transformacja XSL po stronie serwera lub Wykonanie zapytań i aktualizacji XQuery na serwerze.
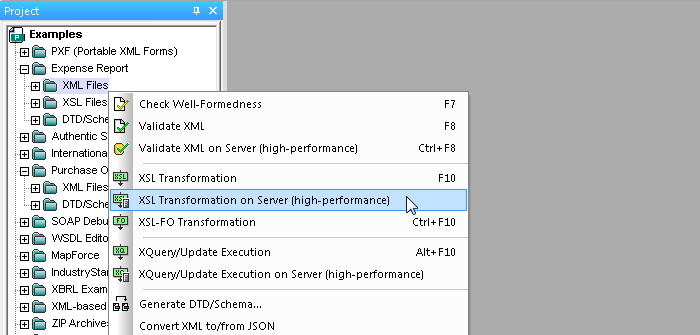
Wyniki, oczywiście, zależą od specyfiki danego projektu, a także od liczby rdzeni przydzielonych do serwera RaptorXML – im więcej rdzeni, tym lepsza wydajność.
Wyniki uzyskiwane są 9 do 14 razy szybciej
Porównaliśmy wydajność na typowym komputerze programisty z wydajnością uzyskaną przy użyciu standardowej konfiguracji serwera RaptorXML zintegrowanego z programem XMLSpy, w sieci o przepustowości 1 GB. Dzięki integracji z RaptorXML, wykonywanie zapytań XQuery było nawet 9 razy szybsze, a transformacje XSLT działały nawet 14 razy szybciej!
Do tych testów użyto komputera dewelopera z systemem Windows 7 (32-bit), procesorem Core2 Duo E8600 o taktowaniu 3,3 GHz (2 rdzenie) oraz 4 GB pamięci RAM. Serwer RaptorXML działał na systemie Linux (64-bit) z procesorem Xeon E5-2630 o taktowaniu 2,3 GHz (12 rdzeni) i 128 GB pamięci RAM. Wyniki mogą się różnić.
Mamy nadzieję, że ta integracja sprawi, że serwer RaptorXML będzie jeszcze bardziej przydatny dla Państwa zespołu programistycznego, ponieważ teraz mogą Państwo korzystać z jednego, współdzielonego serwera RaptorXML do ultraszybkiego przetwarzania plików w programie XMLSpy.
W tym artykule skupiliśmy się na XSLT i XQuery, ale szybka walidacja plików XML, XBRL oraz JSON w programie XMLSpy jest również obsługiwana dzięki integracji z RaptorXML.
Jeśli jeszcze nie posiadacie serwera RaptorXML w swojej sieci, możecie go pobrać na systemy Windows, Linux lub Mac i wypróbować go bezpłatnie przez 30 dni.