Mapowanie danych dla obiektów binarnych
Obiekty binarne są trudne do zarządzania w bazach danych. Są duże, ich zawartość nie jest czytelna dla człowieka, a mogą zawierać bajty danych, które łatwo można błędnie zinterpretować jako znaki sterujące. Nawet nazwa typu danych dla dużych obiektów binarnych – BLOB – odzwierciedla niechęć większości systemów zarządzania bazami danych wobec tych obiektów. Przed wprowadzeniem baz danych relacyjnych, definicja obiektu BLOB brzmiała: „coś nieokreślonego lub bezkształtnego”
Altova MapForce, wielokrotnie nagradzane narzędzie Narzędzie do wizualizacji danych, umożliwiające konwersję i integrację danych w dowolnym formacie, Zawiera funkcje umożliwiające łatwe mapowanie danych binarnych do lub z popularnych baz danych relacyjnych. Można mapować różne rodzaje danych, takie jak obrazy, pliki PDF, pliki wideo lub inne dane binarne. Przyjrzyjmy się przykładowi.

MapForce zawiera dwie wbudowane funkcje: "read-binary-file" (odczyt pliku binarnego) i "write-binary-file" (zapis pliku binarnego), które służą do mapowania między obiektami binarnymi a bazami danych. W tym artykule rozbudujemy przykład funkcji "read-binary-file" z dokumentacji online MapForce, aby stworzyć kompletne mapowanie, które umożliwi wstawianie różnych obiektów binarnych do bazy danych relacyjnej.
Oto przykład z sekcji pomocy, który ilustruje sposób wstawiania obrazu do bazy danych:
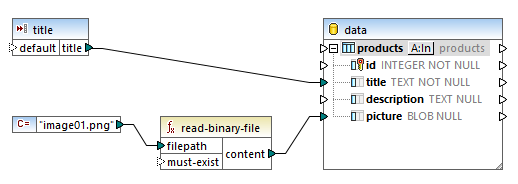
To odwzorowanie umieszcza lokalny plik o nazwie image01.png w tabeli bazy danych. Możemy zauważyć, że baza danych jest zorganizowana w taki sposób, że zawiera metadane dotyczące obrazu w oddzielnych kolumnach, co umożliwia wyszukiwanie i odzyskiwanie tego samego obrazu. Nie chcemy umieszczać dużych plików binarnych w bazie danych bez możliwości ich późniejszego odnalezienia!
W naszym przypadku stworzymy bazę danych SQLite, która będzie służyła do śledzenia różnych plików binarnych, stanowiących zasoby wspierające wiele produktów dla działu marketingu. Dane binarne mogą obejmować pliki graficzne z logo, pliki PDF zawierające specyfikacje produktów, zrzuty ekranu prezentujące produkt w działaniu, zdjęcia, pliki wideo itp.
Zacznijmy od prostego pliku tekstowego w formacie CSV, który będzie opisywał informacje, które chcemy wprowadzić:
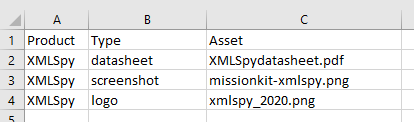
Kiedy ukończymy ten projekt, użytkownicy mogą mieć w bazie danych dziesiątki, a nawet setki zasobów. Kiedy będziemy chcieli pobrać jakiś zasób w przyszłości, nazwy typów zasobów będą kluczowymi metadanymi do wyszukiwania. Jednak jeśli któraś z nazw typów zasobów będzie błędna lub niespójna, duży obiekt binarny stanie się "sierotą" i nie będzie można go odzyskać.
Możemy zdefiniować listę typów zasobów, importując plik CSV do programu XMLSpy i generując schemat XML, w którym element "Type" jest wybierany z predefiniowanej listy. Następnie, nawet osoba bez doświadczenia, np. stażysta działu marketingu, może utworzyć listę zasobów Widok siatki w XMLSpy. Pole "Typ" jest obowiązkowe:
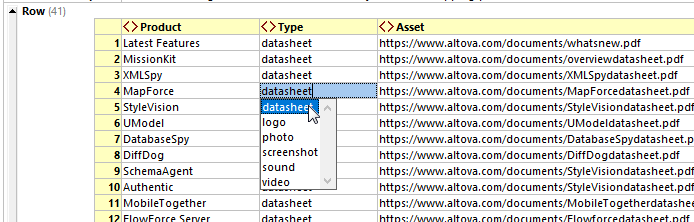
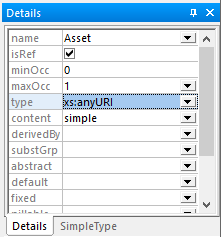
Możemy również dodać listę nazw produktów do schematu XML, lub przynajmniej wymagać obecności elementu "Produkt". Możemy nawet ustawić typ elementu "Zasób" na xs:anyURI, co wymusza odniesienie do pliku. Poniżej znajduje się okno pomocnicze "Szczegóły" w widoku schematu XMLSpy, pokazujące ustawienie typu danych dla elementu "Zasób":
Mapowanie obiektów binarnych w programie MapForce jest zasadniczo identyczne, niezależnie od tego, czy mapujemy dane z pliku CSV, czy z pliku XML.
Zaczniemy od otwarcia nowego projektu MapForce, w którym zdefiniujemy mapowanie danych, a następnie dodamy listę zasobów oraz tabelę bazy danych.
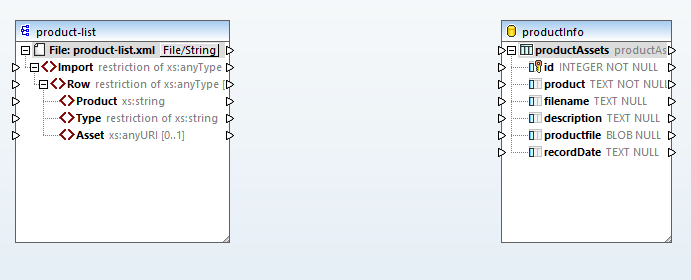
Użyliśmy programu DatabaseSpy, aby utworzyć nową tabelę w bazie danych SQLite, wprowadzając pewne ulepszenia w stosunku do przykładu zawartego w dokumentacji MapForce. Kolumna "product" będzie przechowywać nazwę produktu, a typ zasobu zostanie umieszczony w kolumnie "description". Kolumna "recordDate" będzie śledzić datę utworzenia każdego pliku binarnego.
Teraz ustawimy kolumnę "id" tak, aby automatycznie generowała numery, zgodnie z opisem w dokumentacji MapForce, a następnie narysujemy proste połączenia między źródłem a celem
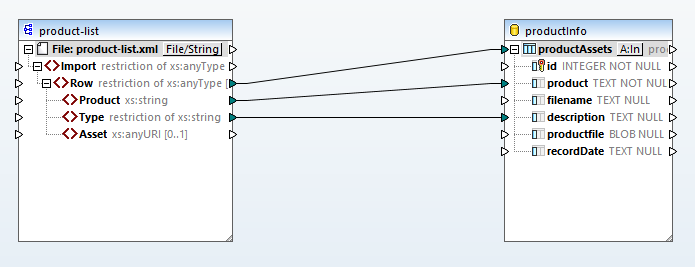
Produkty i typy z mapy źródłowej są bezpośrednio przypisywane do kolumn w bazie danych. Mapowanie elementu "wiersz" instruuje system, aby dla każdego wiersza danych wejściowych tworzył nowy rekord w bazie danych.
Teraz zmapujemy dane binarne na obiekty BLOB w bazie danych:
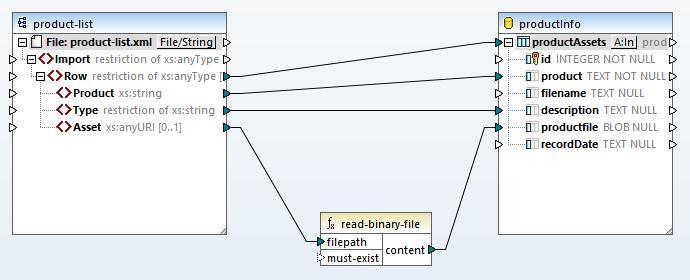
Wbudowana funkcja MapForce o nazwie "read-binary-file" wykorzystuje nazwę pliku podaną w elemencie "Asset" źródła, aby utworzyć obiekt BLOB. Funkcja "read-binary-file" zawsze traktuje dane źródłowe jako dane w formacie base64binary, niezależnie od jakichkolwiek konwencji opartych na nazwie pliku źródłowego.
Aby zakończyć proces mapowania, potrzebujemy połączeń, które pozwolą na wyodrębnienie nazwy pliku z zasobu oraz zapisanie daty przechowywania
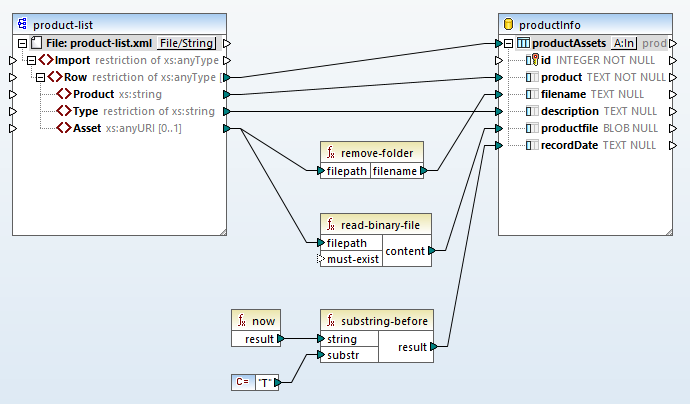
Funkcja "usuń folder" automatycznie wyodrębnia nazwę pliku z dowolnej ścieżki, niezależnie od tego, czy dotyczy ona plików lokalnych, plików sieciowych, czy plików dostępnych w Internecie.
Funkcja "now" rejestruje datę i godzinę wykonania operacji, ale my potrzebujemy tylko daty, dlatego użyliśmy funkcji "substring-before", aby usunąć informację o godzinie.
Przycisk "Wygeneruj" znajdujący się na dole panelu mapowania uruchamia proces mapowania i generuje skrypt SQL:
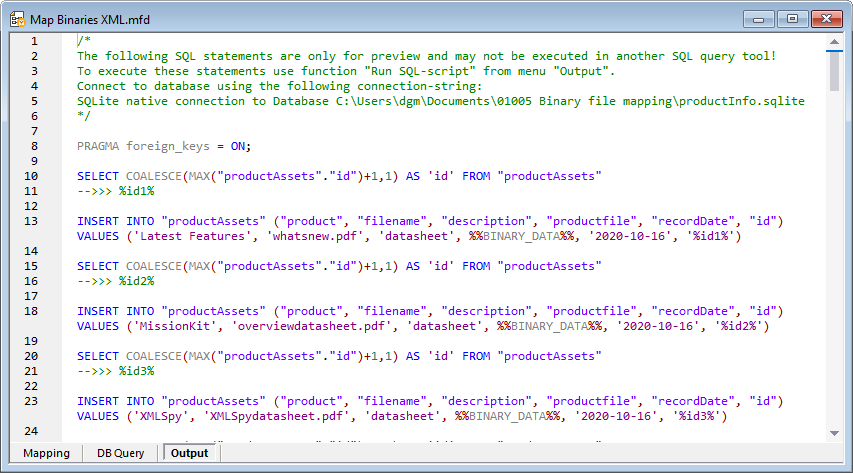
Ten skrypt służy jedynie do podglądu wyników uzyskanych do tej pory. Wybór odpowiedniej opcji w głównym menu "Wyjście" uruchamia skrypt
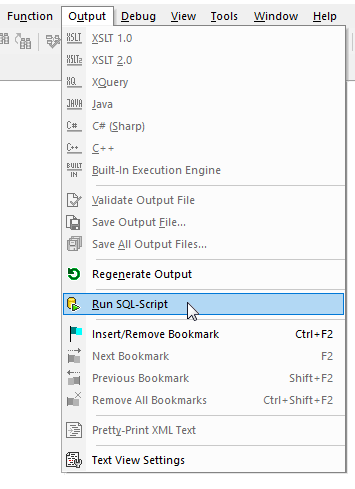
Wynik działania skryptu jest wyświetlany:
Klikniemy przycisk "Zapytanie do bazy danych", aby połączyć się z bazą danych i następnie zweryfikować wynik bezpośrednio w programie MapForce:
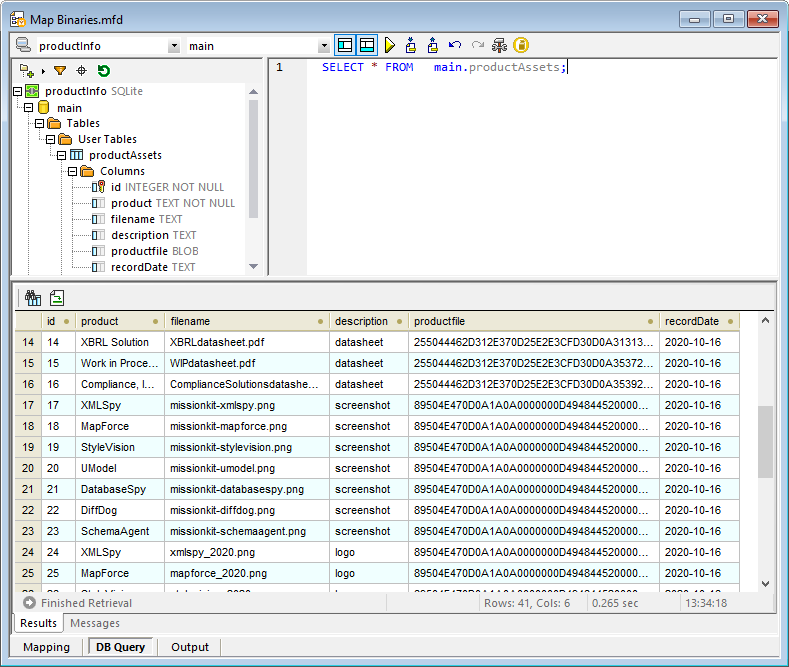
Nie można wiele wywnioskować, analizując dane w kolumnie "productfile" (która zawiera duże bloki danych), ale pozostałe kolumny zawierają przydatne metadane dotyczące każdego elementu.
W [data-mapping-binary-objects-part-2|dodatkowa wiadomość/komentarz (w odpowiedzi na wcześniejszą wypowiedź) Zaprezentujemy sposób mapowania danych, w tym obiektów binarnych [Wyodrębnij zasoby z bazy danych]] i zapisz je w ich oryginalnej formie. Jeśli nie możecie się powstrzymać, Pobierz bezpłatną wersję próbną w tym samouczki, pomoc i wiele przykładów, które pomogą rozpocząć własny projekt mapowania, konwersji i transformacji danych!