Chociaż format PDF jest powszechnie stosowany w biznesie, dane zawarte w plikach PDF nie są łatwo dostępne do integracji z innymi systemami. Pliki PDF są zazwyczaj przeznaczone do prezentacji treści czytelnych dla człowieka, z różnorodnym formatowaniem i układem, co sprawia, że ekstrakcja ustrukturyzowanych danych jest niezwykle trudna. Mogą one zawierać tekst, obrazy, tabele i inne elementy, a dane nie są zorganizowane w formacie czytelnym dla maszyn. Typowe narzędzia do ekstrakcji danych z plików PDF mogą nie dostarczać dokładnych wyników, zwłaszcza w przypadku plików o złożonych układach. Właśnie dlatego powstał MapForce PDF Extractor.
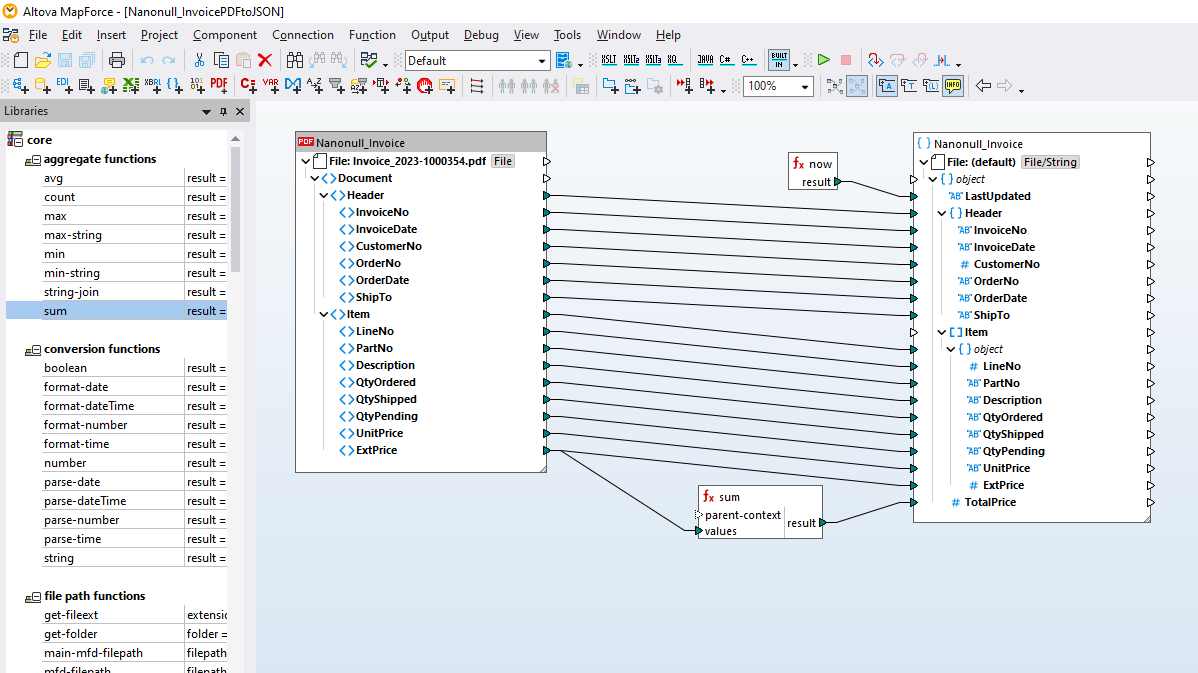
Program MapForce PDF Extractor to łatwe w użyciu narzędzie, które umożliwia szybkie zdefiniowanie struktury dokumentu PDF i wyodrębnienie z niego danych. Następnie, te dane z dokumentu PDF można wykorzystać do dalszej transformacji i konwersji do innych formatów, takich jak XML, JSON, bazy danych, Excel i inne, w programie MapForce. Jest to idealne narzędzie do integracji danych z dokumentów PDF oraz do realizacji projektów ETL (Extract, Transform, Load).
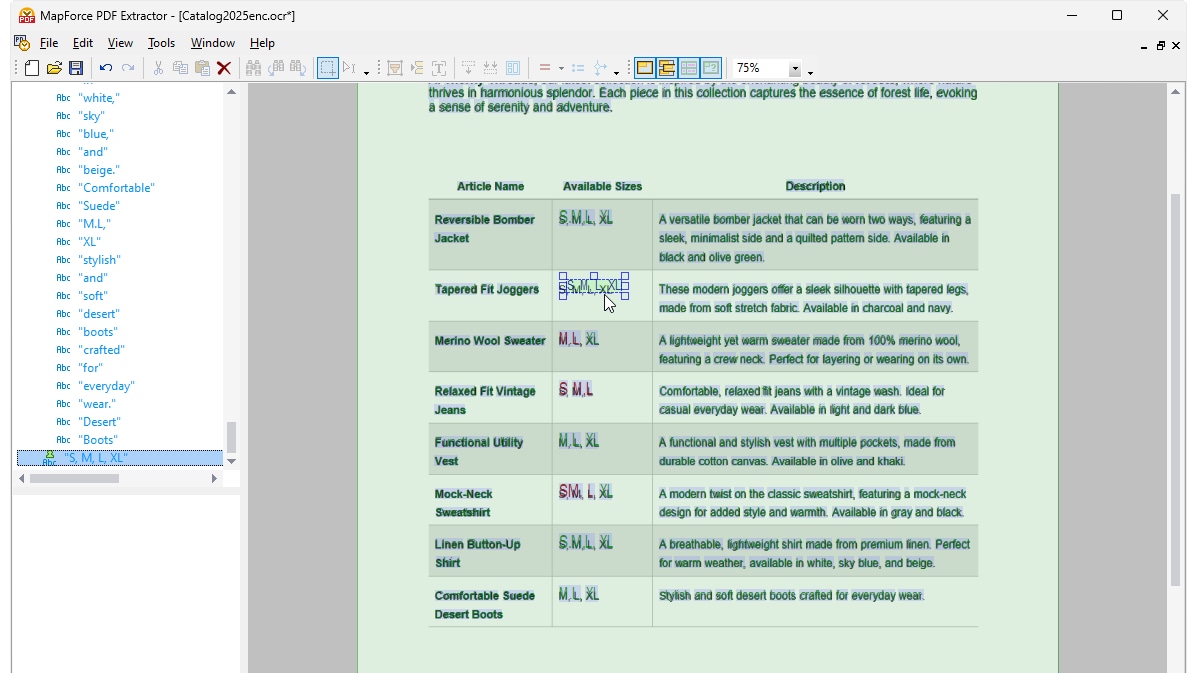
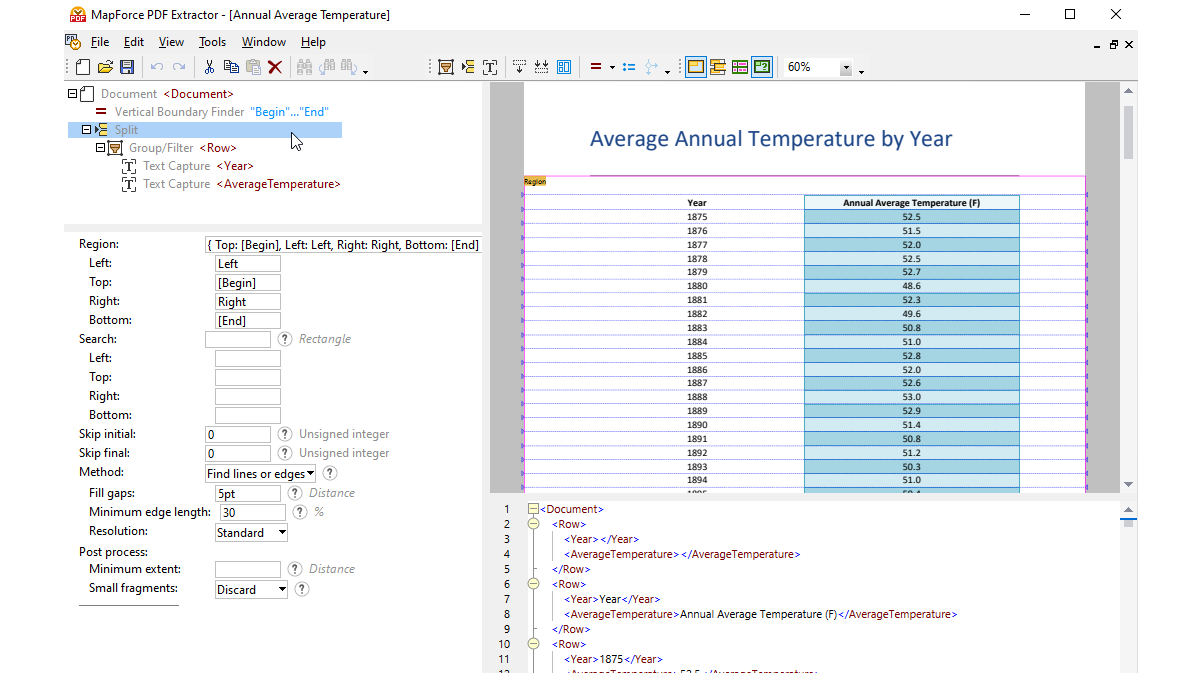
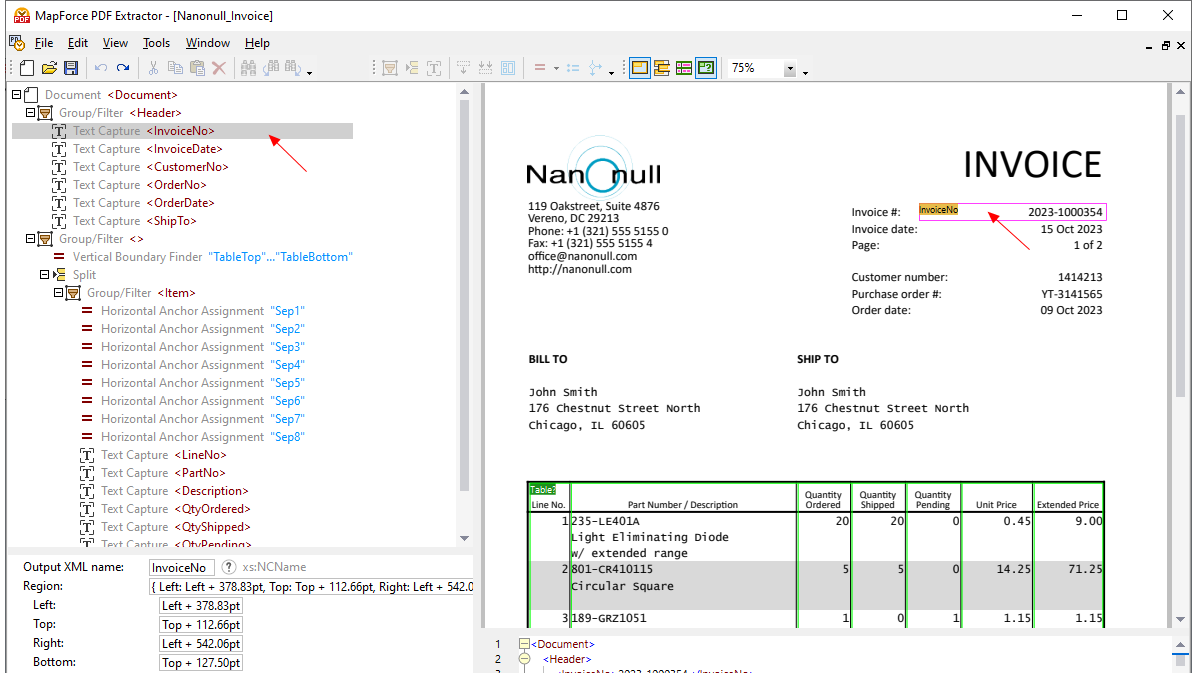
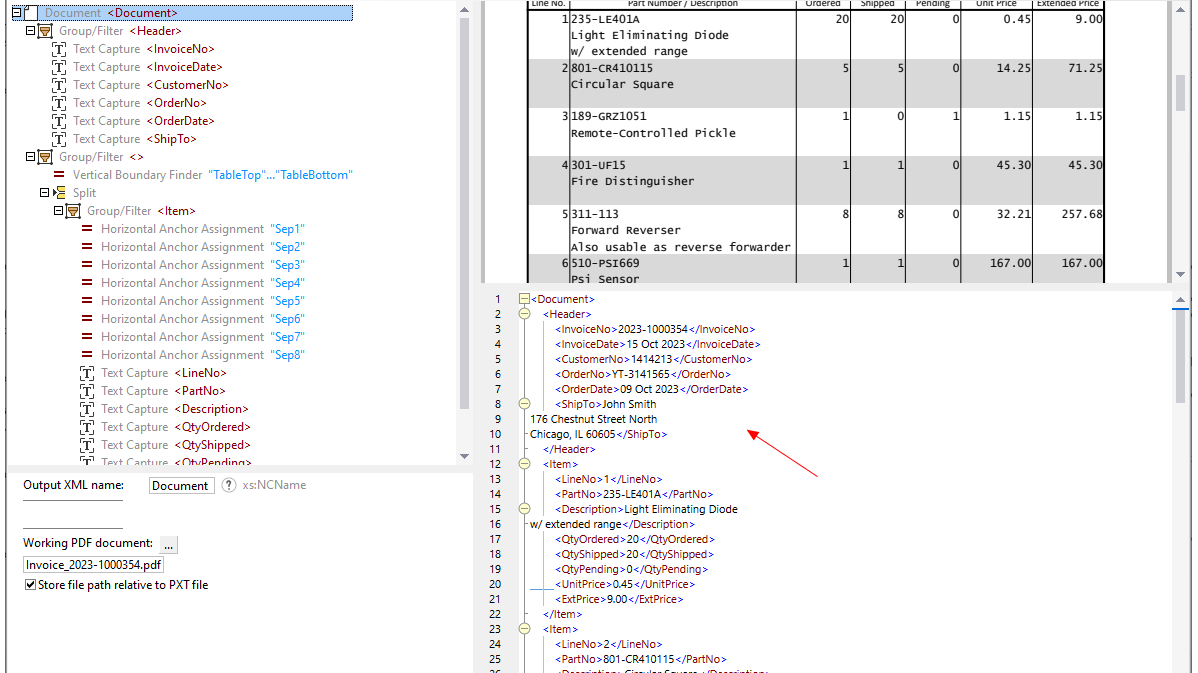
Dzięki wykorzystaniu narzędzi wizualnych w programie MapForce PDF Extractor, można zdefiniować strukturę dokumentu PDF i efektywnie wyodrębnić z niego dane. PDF Extractor to bardzo elastyczne narzędzie, które umożliwia wyodrębnianie tylko fragmentów tekstu, a nie całego dokumentu, łączenie fragmentów informacji z różnych stron tego samego pliku PDF, dzielenie tabel na wiersze oraz grupowanie danych.
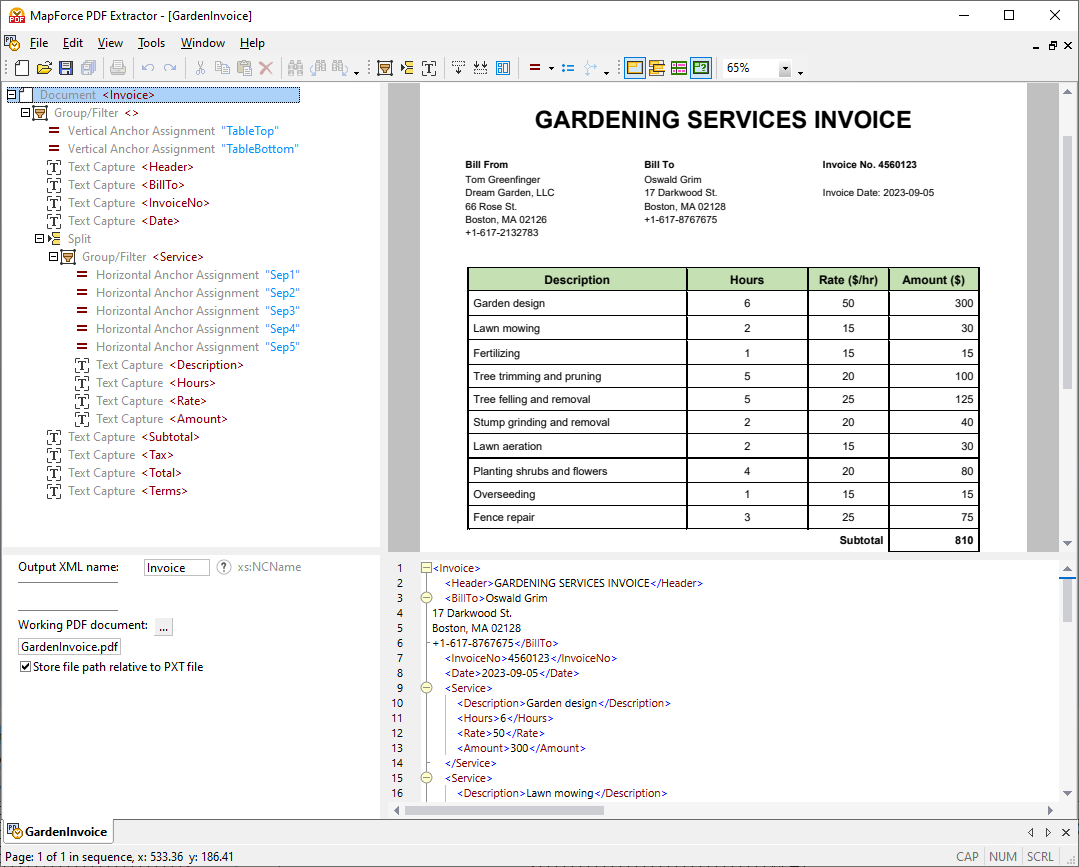
Intuicyjny i prosty w obsłudze program MapForce PDF Extractor umożliwia łatwe definiowanie struktury dokumentów PDF w sposób wizualny, wykorzystując funkcje klikania i przeciągania. Dzięki temu ogromne ilości danych, które wcześniej były zamknięte w plikach PDF, są teraz dostępne do konwersji do innych formatów.