Extrair dados para mapeamento em PDF
O MapForce, a ferramenta de mapeamento de dados premiada da Altova, inclui suporte para entrada de ficheiros PDF nos fluxos de trabalho de integração de dados e ETL. O extrator de PDF do MapForce facilita a definição de regras para extrair dados de ficheiros PDF num formato estruturado, tornando-os disponíveis para serem mapeados para outros formatos populares, como Excel, XML, JSON, bases de dados e muito mais.
Vamos analisar como funciona.

Como extrair dados de um ficheiro PDF
O formato de ficheiro PDF é hoje amplamente utilizado em diversas áreas de comunicação, graças à sua capacidade de garantir uma apresentação consistente em qualquer plataforma ou dispositivo. Os ficheiros PDF combinam geralmente várias formas de apresentação de dados em elementos que são fáceis de ler para os utilizadores, incluindo texto, imagens, gráficos e tabelas, tudo com uma variedade de opções de formatação.
No entanto, embora os PDFs sejam excelentes para apresentar dados de forma intuitiva, eles não possuem uma estrutura interna que permita extrair esses dados de forma eficaz para integração com outros sistemas empresariais, o que, naturalmente, é uma necessidade comum. As ferramentas tradicionais de extração de dados muitas vezes não conseguem capturar informações com precisão a partir de PDFs, especialmente quando se trata de layouts complexos e estilos de formatação variáveis. Isso pode resultar em erros, ineficiências e a necessidade de intervenção manual para corrigir os dados extraídos.
Para resolver estes desafios de integração de dados PDF, a Altova criou o MapForce PDF Extractor, uma ferramenta visual que facilita a definição de regras para extrair dados estruturados de documentos PDF.
Veja neste vídeo explicativo como funciona o MapForce PDF Extractor:
A melhor forma de começar a usar o MapForce PDF Extractor é carregar um documento de exemplo com o formato dos dados que pretende extrair. Este poderá ser uma fatura, um formulário de introdução de dados, um relatório, um registo de cliente, etc. Se o PDF for uma versão digitalizada de outro documento, pode começar por utilizar a tecnologia OCR para desbloquear os dados e prepará-lo para o extrator.
O extrator de PDF exibe o seu documento de exemplo, permitindo que comece a definir um modelo e regras para extrair os dados de forma estruturada. O design simples do MapForce PDF Extractor facilita a especificação da estrutura do documento PDF de forma visual, utilizando funcionalidades de seleção e arrastar e soltar.
Ao lado da área de visualização do PDF, existe uma área que exibe uma estrutura em árvore, representando a forma como o PDF será analisado e como os dados serão extraídos.
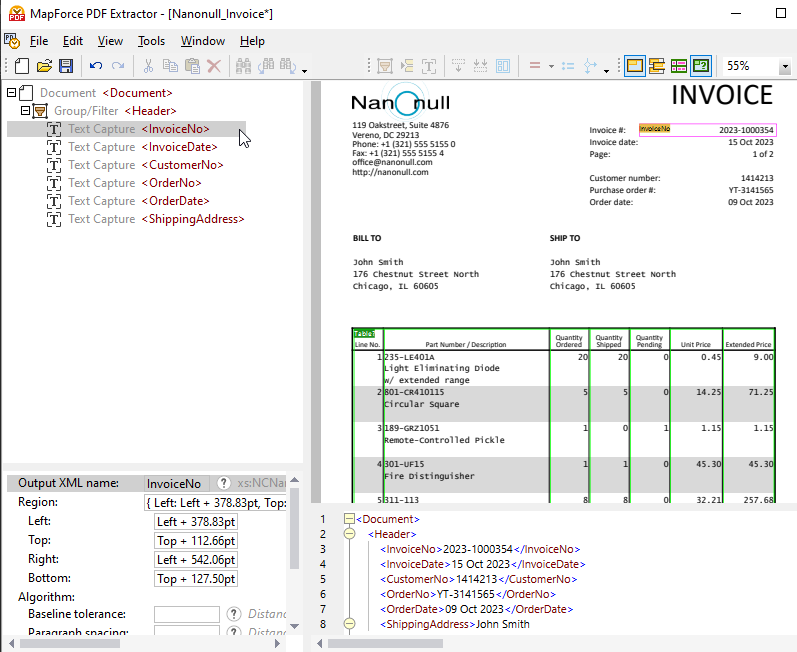
O painel de propriedades permite definir propriedades e calcular expressões, conforme necessário. Na parte inferior da visualização do documento PDF, encontra-se o painel de resultados (mostrado acima), que permite visualizar uma pré-visualização do resultado da extração de dados do PDF, com base nas propriedades e regras de extração que você definir. O resultado é representado por um documento XML que mostra as etiquetas XML para a estrutura, bem como o conteúdo real do ficheiro de exemplo que está a ser extraído.
Para capturar partes do documento e adicioná-las à árvore de esquema, basta selecionar a área desejada e clicar com o botão direito para criar uma captura de texto.
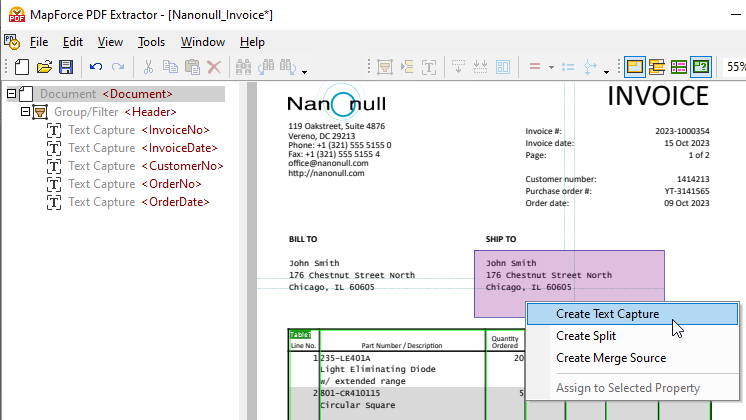
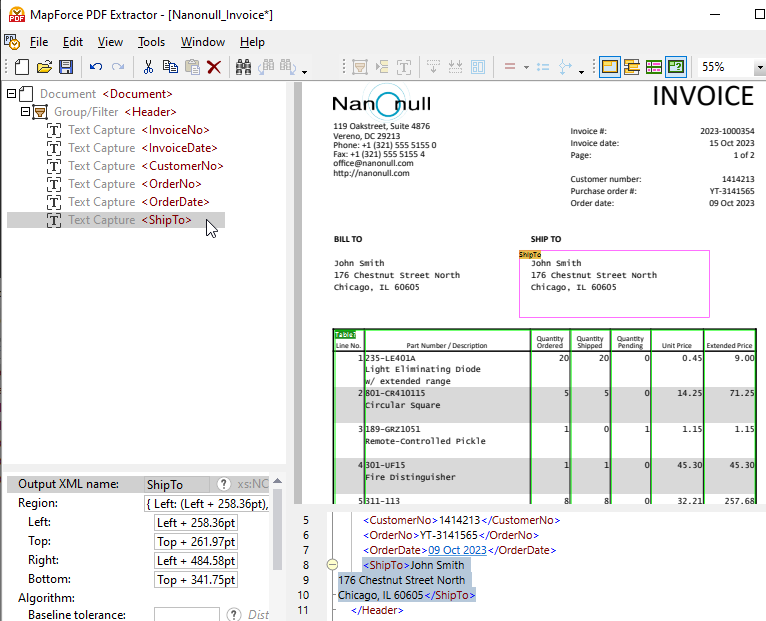
Arraste o elemento recém-criado para o local desejado na estrutura e atribua-lhe um nome descritivo.
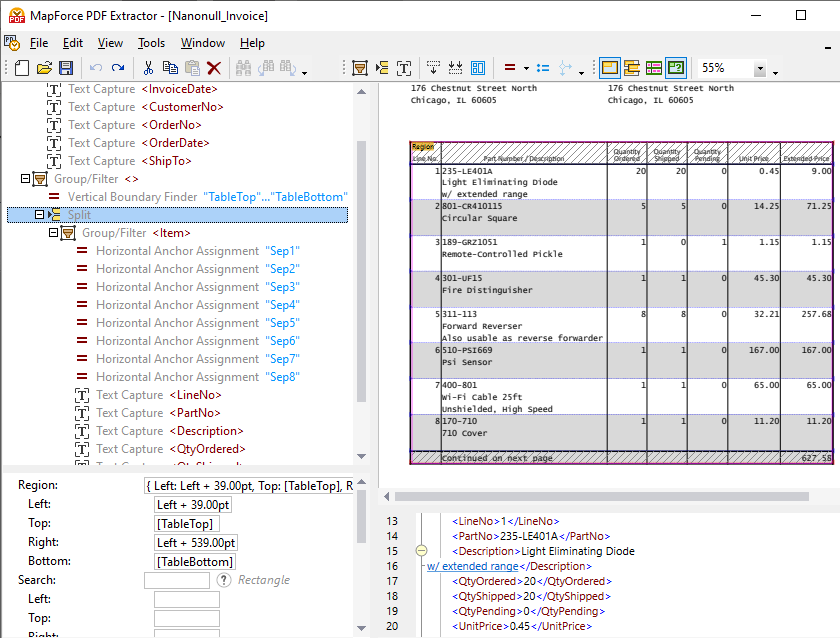
Além de permitir a definição manual de regras de extração de dados, o MapForce PDF Extractor inclui um motor de sugestões poderoso que identifica automaticamente elementos comuns em documentos e tenta detetar a sua estrutura. Por exemplo, o motor de sugestões identifica tabelas que existem no documento, e pode optar por extraí-las automaticamente e, em seguida, refiná-las conforme necessário. O operador de divisão no painel de esquema ajuda a definir como dividir corretamente a tabela em linhas separadas. O motor de sugestões pode procurar bordas ou linhas para criar a divisão, dividir com base numa distância fixa, ou detetar alterações na cor de fundo, o que pode visualizar no painel de visualização PDF. Ao mesmo tempo, o motor de sugestões identifica colunas e texto de cabeçalho, que pode ajustar conforme necessário, como se pode ver no vídeo acima.
Ao clicar em qualquer objeto na árvore de esquema, a estrutura correspondente e as regras de captura de dados são destacadas, tal como se aplicam na visualização do documento PDF.
Converter mapas em formato PDF para outros formatos
Assim que o seu modelo no MapForce PDF Extractor estiver completo, poderá adicioná-lo a um projeto de mapeamento de dados do MapForce para mapear eficientemente os dados PDF para outros formatos suportados. Basta arrastar e soltar para associar os nós de origem e destino e aproveitar a biblioteca integrada de funções de processamento de dados para transformar os dados PDF. As aplicações comuns incluem:
Converter PDF para Excel
Conversão de PDF para XML
Conversão de PDF para JSON
Conversão de ficheiros PDF para sistemas de bases de dados SQL ou NoSQL
Conversão de documentos PDF para mensagens EDI
Converter PDF para CSV ou texto
Além destes cenários, o MapForce suporta processos de mapeamento de dados encadeados, bem como múltiplas estruturas de dados de origem e destino.
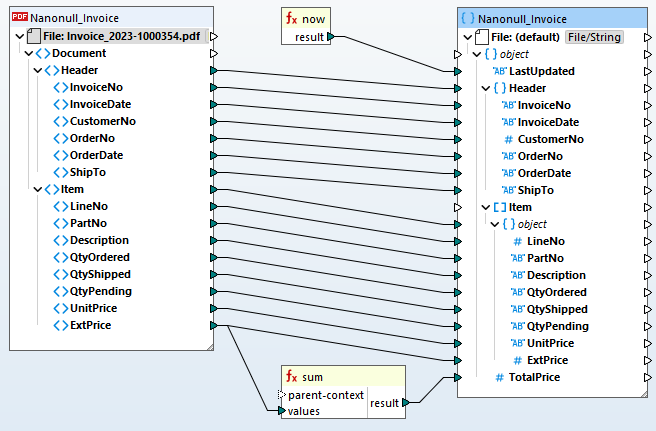
Com base na definição de mapeamento de dados que fornecer, o MapForce transforma os dados instantaneamente. Ou, pode utilizar o MapForce Server Advanced Edition para transformações PDF recorrentes e pipelines ETL. Isto permite que as organizações automatizem a integração de dados e otimizem os processos, incorporando de forma integrada os dados PDF nos seus sistemas, bases de dados e fluxos de trabalho existentes.
Comece a utilizar o MapForce PDF Extractor ao descarregar uma versão de avaliação gratuita no site da Altova.