Extraheer gegevens voor het maken van PDF-kaarten
MapForce, het bekroonde data-mappingtool van Altova, biedt ondersteuning voor PDF-invoer in data-integratie- en ETL-workflows. De MapForce PDF Extractor maakt het eenvoudig om regels te definiëren voor het extraheren van PDF-gegevens in een gestructureerd formaat, zodat deze beschikbaar zijn voor het omzetten naar andere populaire formaten, zoals Excel, XML, JSON, databases en meer.
Laten we eens kijken hoe het werkt.

Hoe gegevens uit een PDF-bestand halen
Het PDF-bestandsformaat wordt tegenwoordig in bijna alle communicatievormen gebruikt, dankzij het vermogen om een consistente weergave te bieden op elk platform of apparaat. PDF-bestanden combineren doorgaans verschillende manieren om data weer te geven in elementen die goed werken voor mensen, zoals tekst, afbeeldingen, grafieken en tabellen, allemaal met een verscheidenheid aan opmaakopties.
Hoewel PDF-bestanden uitstekend zijn voor het presenteren van data op een gebruiksvriendelijke manier, missen ze de ingebouwde structuur die nodig is om die data effectief te extraheren en te integreren met andere bedrijfssystemen. Dit is echter een veelvoorkomende vereiste. Traditionele tools voor data-extractie falen vaak om informatie correct uit PDF-bestanden te halen, vooral wanneer het gaat om complexe lay-outs en verschillende opmaakstijlen. Dit kan leiden tot fouten, inefficiëntie en de noodzaak van handmatige correcties van de geëxtraheerde data.
Om deze uitdagingen bij het integreren van PDF-gegevens aan te pakken, heeft Altova de MapForce PDF Extractor ontwikkeld, een visueel hulpmiddel waarmee het eenvoudig is om regels te definiëren voor het extraheren van gestructureerde gegevens uit PDF-bestanden.
Bekijk deze instructievideo om te leren hoe de MapForce PDF Extractor werkt:
De beste manier om te beginnen met de MapForce PDF Extractor is om een voorbeelddocument te laden met het formaat van de gegevens die u wilt extraheren. Dit kan bijvoorbeeld een factuur, een formulier voor gegevensinvoer, een rapport, een klantendossier, enzovoort zijn. Als het PDF-bestand een gescande versie is van een ander document, kunt u beginnen met OCR om de gegevens te ontsluiten en het bestand klaar te maken voor de extractor.
De PDF-extractor toont uw voorbeelddocument, zodat u een sjabloon en regels kunt definiëren voor het gestructureerd extraheren van de gegevens. Het eenvoudige ontwerp van de MapForce PDF-extractor maakt het gemakkelijk om de structuur van het PDF-document visueel te specificeren, met behulp van functies waarmee u kunt klikken en slepen.
Naast het venster waarin de PDF wordt weergegeven, toont een schema-venster een boomstructuur die weergeeft hoe de PDF zal worden verwerkt en hoe de gegevens zullen worden geëxtraheerd.
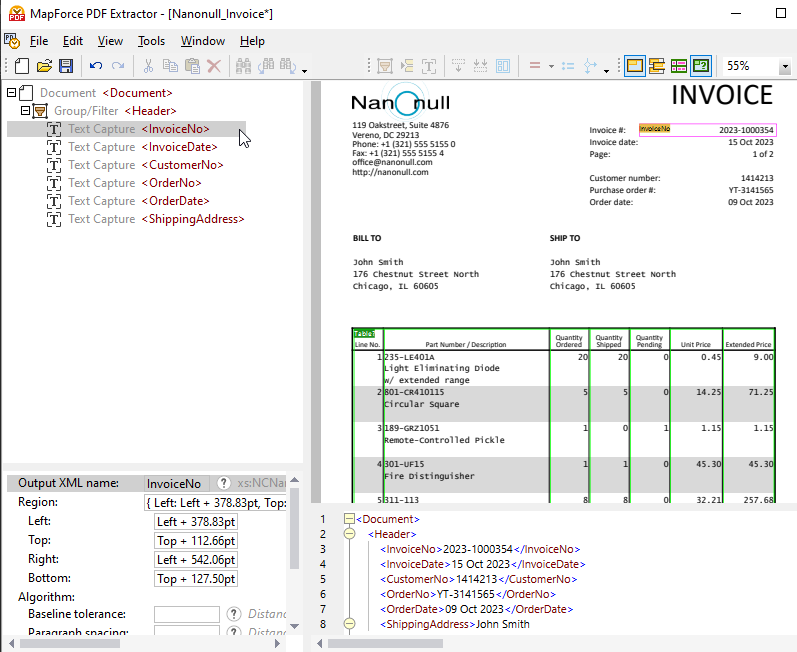
Het eigenschappenvenster stelt u in staat om eigenschappen te definiëren en berekeningen uit te voeren, indien nodig. Onderaan het PDF-documentvenster bevindt zich het uitvoervenster (zoals hierboven weergegeven), waarmee u een voorbeeld van het resultaat van de extractie van PDF-gegevens kunt bekijken, op basis van de eigenschappen en extractieregels die u definieert. De uitvoer wordt weergegeven als een XML-document, met XML-tags die de structuur weergeven, evenals de daadwerkelijke inhoud van het voorbeeldbestand dat wordt geëxtraheerd.
Om delen van het document te selecteren en toe te voegen aan de schema-boom, kunt u een gebied markeren en met de rechtermuisknop klikken om een tekstfragment te kopiëren.
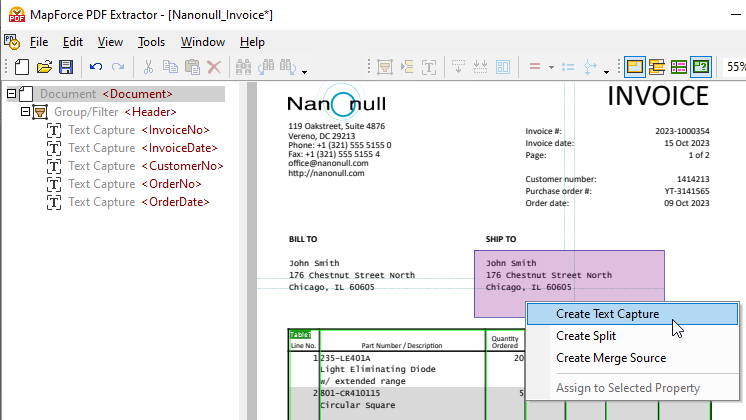
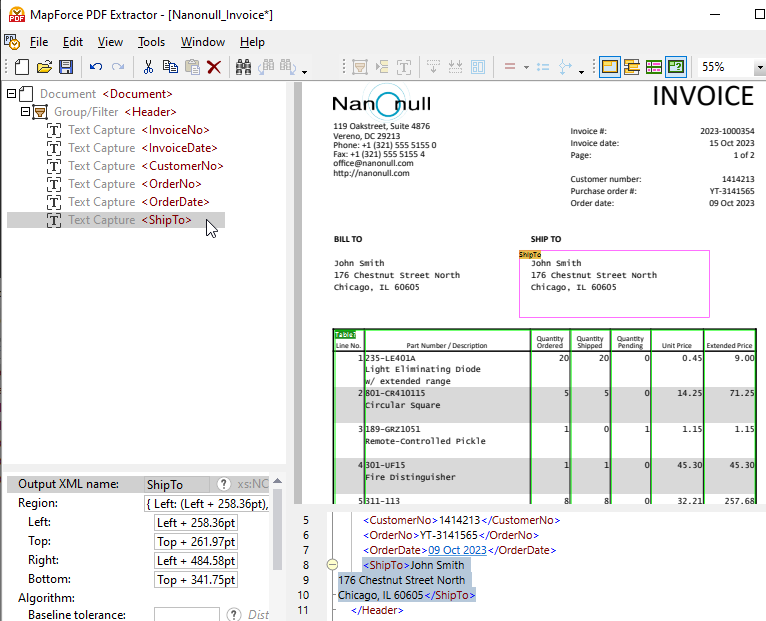
Sleep het zojuist aangemaakte element naar de gewenste positie in de boomstructuur en geef het een beschrijvende naam.
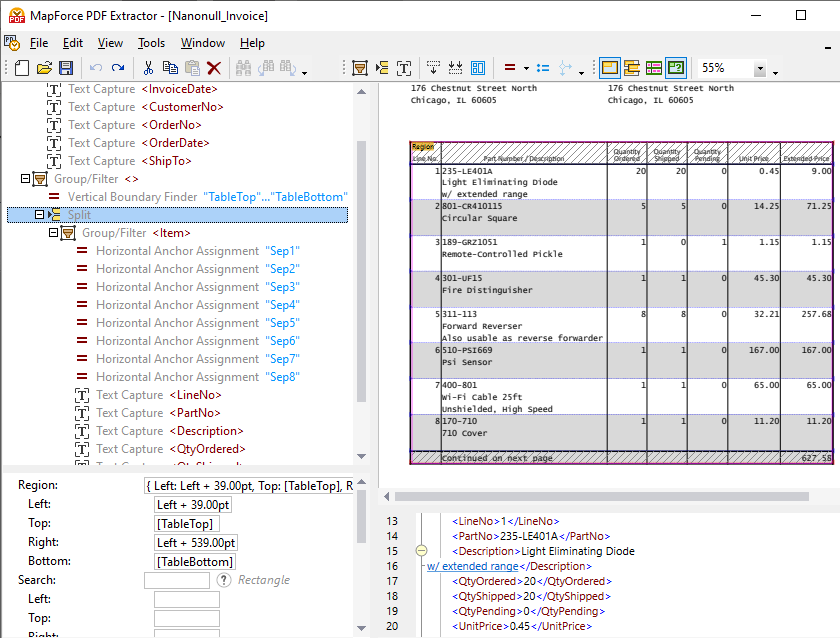
Naast de mogelijkheid om data-extractieregels handmatig te definiëren, bevat de MapForce PDF Extractor een krachtige suggestiemotor die automatisch veelvoorkomende elementen in documenten herkent en probeert hun structuur te detecteren. Zo identificeert de suggestiemotor bijvoorbeeld tabellen die in het document voorkomen, die u automatisch kunt extraheren en vervolgens indien nodig kunt verfijnen. De "split"-operator in het schema-venster helpt u bij het definiëren van de juiste manier om de tabel op te delen in afzonderlijke rijen. De suggestiemotor kan zoeken naar randen of lijnen om de scheiding te creëren, de scheiding baseren op een vaste afstand, of veranderingen in de achtergrondkleur detecteren. U kunt dit bekijken in het PDF-weergavevenster. Tegelijkertijd identificeert de suggestiemotor kolommen en koptekst, die u indien nodig kunt aanpassen, zoals te zien is in de video hierboven.
Door op een object in de schema-boom te klikken, wordt de bijbehorende structuur en de regels voor gegevensverzameling gemarkeerd, zoals deze van toepassing zijn in de weergave van het PDF-document.
Converteer PDF-bestanden naar andere formaten
Zodra uw sjabloon in de MapForce PDF Extractor voltooid is, kunt u dit toevoegen aan een MapForce-project voor data-mapping om de PDF-gegevens efficiënt om te zetten naar andere ondersteunde formaten. Sleep en plaats eenvoudig om bron- en doelpunten te koppelen en maak gebruik van de ingebouwde bibliotheek met databewerkingfuncties om de PDF-gegevens te transformeren. Veelvoorkomende toepassingen zijn:
PDF naar Excel
PDF naar XML
PDF naar JSON
PDF-bestanden omzetten naar SQL- of NoSQL-databasesystemen
PDF-bestanden omzetten naar EDI-berichten
PDF naar CSV of tekst
Naast deze scenario's ondersteunt MapForce ook keten van datatransformatieprocessen, evenals meerdere bron- en doelgegevensstructuren.
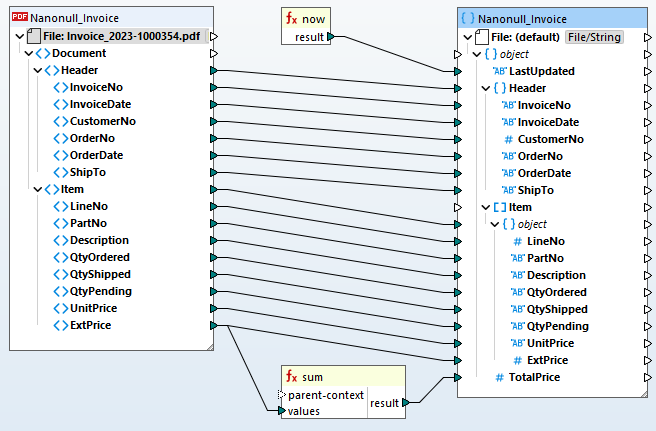
Op basis van uw datamappingspecificaties transformeert MapForce de gegevens direct. U kunt ook gebruikmaken van MapForce Server Advanced Edition voor herhaalde PDF-transformaties en ETL-pijplijnen. Dit stelt organisaties in staat om data-integratie te automatiseren en processen te optimaliseren door PDF-gegevens naadloos te integreren in hun bestaande systemen, databases en workflows.
U kunt direct aan de slag met de MapForce PDF Extractor door een gratis proefversie te downloaden van de Altova-website.