Extraer datos para la creación de mapas en formato PDF
MapForce, la herramienta de mapeo de datos galardonada de Altova, incluye soporte para la entrada de archivos PDF en flujos de trabajo de integración de datos y ETL. El extractor de PDF de MapForce facilita la definición de reglas para extraer datos de archivos PDF en un formato estructurado, lo que permite utilizarlos para mapearlos a otros formatos populares como Excel, XML, JSON, bases de datos, y más.
Veamos cómo funciona.

Cómo extraer datos de un archivo PDF
El formato de archivo PDF goza de una amplia aceptación en las comunicaciones actuales, gracias a su capacidad para ofrecer una presentación consistente en cualquier plataforma o dispositivo. Los archivos PDF suelen combinar diferentes formas de presentar datos en elementos que son fáciles de leer para los usuarios, incluyendo texto, imágenes, gráficos y tablas, todo ello con una variedad de opciones de formato.
Sin embargo, aunque los archivos PDF son excelentes para presentar datos de una manera fácil de usar, carecen de la estructura interna necesaria para extraer esos datos de manera efectiva y para integrarlos con otros sistemas empresariales, lo cual, por supuesto, es un requisito común. Las herramientas tradicionales de extracción de datos a menudo no logran capturar con precisión la información de los archivos PDF, especialmente cuando se trata de diseños complejos y estilos de formato variables. Esto puede provocar errores, ineficiencias y la necesidad de intervención manual para corregir los datos extraídos.
Para abordar estos desafíos en la integración de datos PDF, Altova creó MapForce PDF Extractor, una herramienta visual que facilita la definición de reglas para extraer datos estructurados de archivos PDF.
Aprenda cómo funciona MapForce PDF Extractor en este video tutorial:
La mejor manera de comenzar a utilizar el extractor de PDF de MapForce es cargar un documento de ejemplo que tenga el formato de los datos que necesita extraer. Este podría ser una factura, un formulario de entrada de datos, un informe, un registro de cliente, etc. Si el PDF es una versión escaneada de otro documento, puede comenzar con el reconocimiento óptico de caracteres (OCR) para desbloquear sus datos y prepararlo para el extractor.
El extractor de PDF muestra su documento de muestra para que pueda comenzar a definir una plantilla y reglas para extraer los datos de forma estructurada. El diseño sencillo del MapForce PDF Extractor facilita la especificación de la estructura del documento PDF de manera visual, utilizando funciones de selección con el ratón y arrastrar y soltar.
Junto al panel de visualización de PDF, se encuentra un panel de esquema que muestra una estructura en árbol que representa cómo se analizará el PDF y cómo se extraerán los datos.
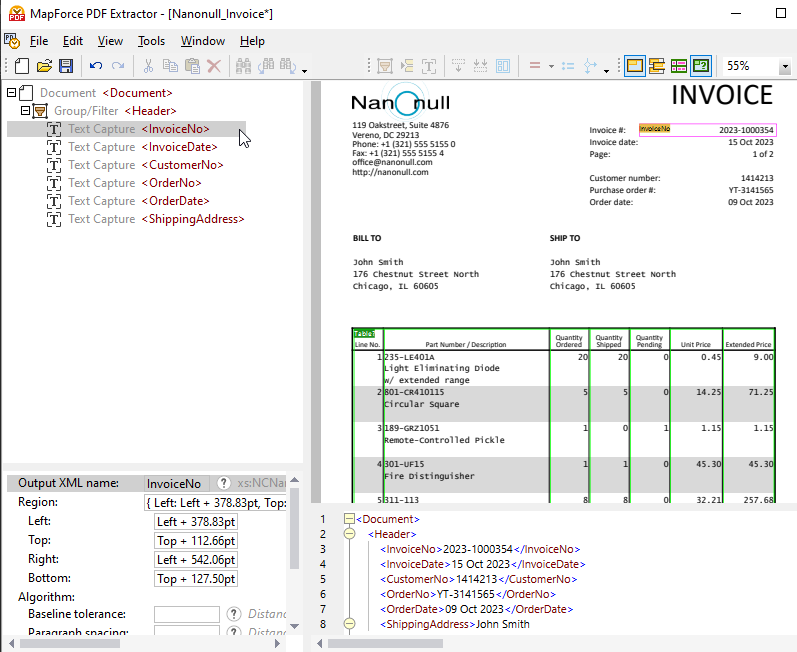
El panel de propiedades le permite definir propiedades y calcular expresiones, según sea necesario. En la parte inferior de la vista del documento PDF se encuentra el panel de resultados (que se muestra arriba), que le permite ver una vista previa del resultado de la extracción de datos del PDF en función de las propiedades y las reglas de extracción que defina. El resultado se representa mediante un documento XML que muestra las etiquetas XML que definen la estructura, así como el contenido real del archivo de muestra que se está extrayendo.
Para capturar partes del documento y añadirlas al árbol de esquema, simplemente seleccione el área deseada y haga clic derecho para crear una captura de texto.
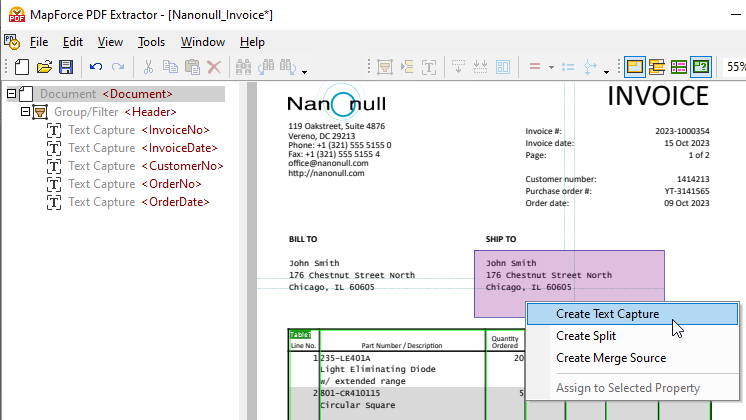
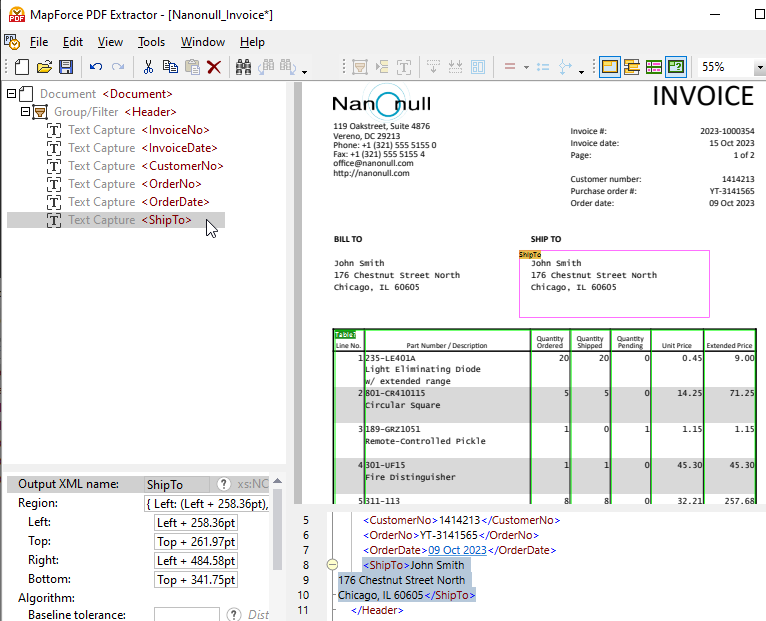
Arrastra el elemento recién creado a la ubicación deseada en el árbol y asígnale un nombre descriptivo.
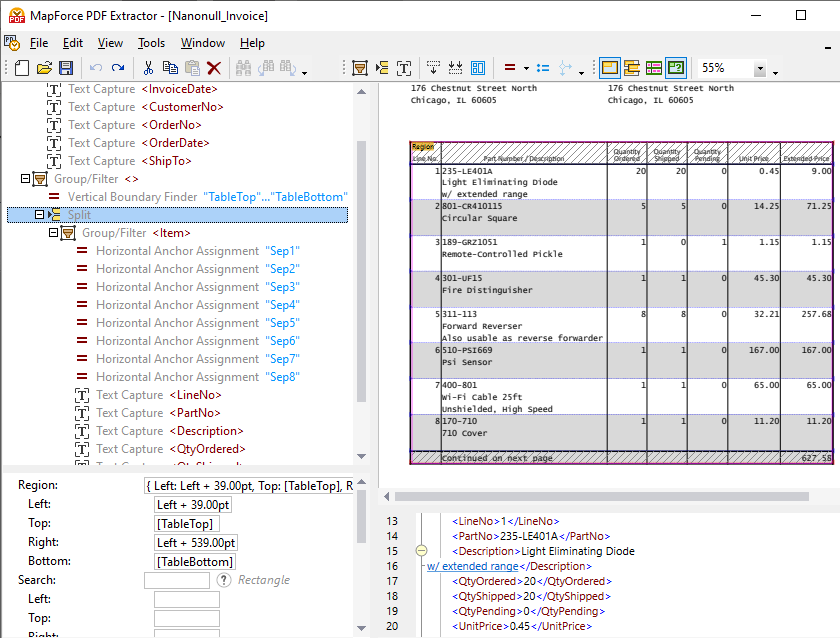
Además de permitir la definición manual de reglas de extracción de datos, el extractor de PDF de MapForce incluye un potente motor de sugerencias que identifica automáticamente elementos comunes en los documentos e intenta detectar su estructura. Por ejemplo, el motor de sugerencias identificará las tablas que existen en el documento, y usted puede optar por extraerlas automáticamente y luego ajustarlas según sea necesario. El operador de división en el panel de esquema le ayuda a definir cómo dividir correctamente la tabla en filas separadas. El motor de sugerencias puede buscar bordes o líneas para crear la división, dividir basándose en una distancia fija, o detectar cambios en el color de fondo, lo que puede previsualizar en el panel de vista de PDF. Al mismo tiempo, el motor de sugerencias captura las columnas y el texto de los encabezados, que puede ajustar según sea necesario, como se muestra en el video anterior.
Al hacer clic en cualquier objeto del árbol de esquema, se resaltará la estructura correspondiente y las reglas de captura de datos tal como se aplican en la vista del documento PDF.
Convertir archivos PDF de mapas a otros formatos
Una vez que haya completado su plantilla en el extractor de PDF de MapForce, puede agregarla a un proyecto de mapeo de datos de MapForce para transferir de manera eficiente los datos del PDF a otros formatos compatibles. Simplemente arrastre y suelte para asociar los nodos de origen y destino, y aproveche la biblioteca integrada de funciones de procesamiento de datos para transformar los datos del PDF. Algunas aplicaciones comunes incluyen:
PDF a Excel
PDF a XML
PDF a JSON
Conversión de archivos PDF a sistemas de bases de datos SQL o NoSQL
Conversión de mensajes PDF en EDI
Convertir PDF a CSV o a texto
Además de estos escenarios, MapForce admite procesos de mapeo de datos en cadena, así como múltiples estructuras de datos de origen y destino.
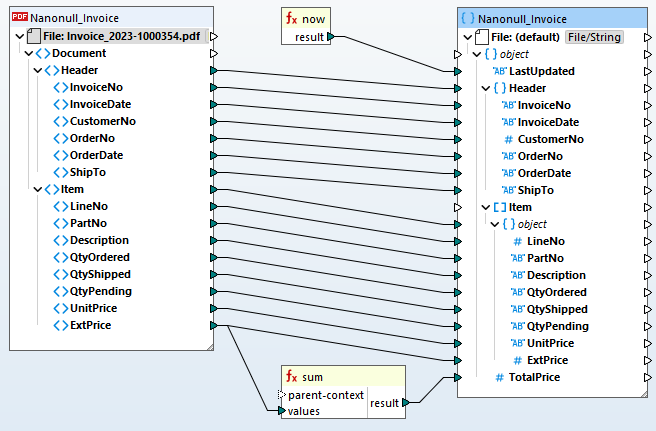
Basándose en la definición de mapeo de datos que proporcione, MapForce transforma los datos de forma instantánea. Alternativamente, puede utilizar MapForce Server Advanced Edition para realizar transformaciones de PDF recurrentes y crear flujos de trabajo ETL. Esto permite a las organizaciones automatizar la integración de datos y optimizar los procesos, incorporando de manera fluida los datos en formato PDF en sus sistemas, bases de datos y flujos de trabajo existentes.
Comience a utilizar el extractor de PDF de MapForce siguiendo estos pasos: descargar una versión de prueba gratuita del sitio web de Altova.