提取PDF文件中的数据,用于地图绘制
MapForce,Altova 获奖的数据映射工具,在数据集成和 ETL 工作流程中支持 PDF 输入。MapForce PDF 提取工具可以轻松定义规则,将 PDF 数据以结构化格式提取出来,以便将其映射到其他常用格式,例如 Excel、XML、JSON、数据库等。
我们来了解一下它的工作原理。

如何从PDF文件中提取数据
如今,PDF文件格式在各行各业的沟通中几乎无处不在,这得益于其能够在任何平台或设备上提供一致的呈现效果。PDF文件通常将多种数据呈现方式整合在一起,采用适合人类阅读的元素,包括文本、图像、图表和表格,并且提供多种格式选项。
虽然PDF格式非常适合以用户友好的方式呈现数据,但它缺乏任何内置的结构,这使得有效提取数据并将其与其他业务系统集成变得困难,而这通常是企业的一项常见需求。传统的提取工具往往无法准确地从PDF文件中提取信息,尤其是在处理复杂布局和不同格式样式时。这可能导致错误、效率低下,以及需要人工干预来修正提取的数据。
为了应对这些PDF数据集成方面的挑战,Altova开发了MapForce PDF提取器,这是一个可视化工具,可以轻松定义规则,从而从PDF文件中提取结构化数据。
观看本视频,了解如何使用 MapForce PDF 提取器:
开始使用 MapForce PDF 提取工具的最佳方法是加载一个包含您需要提取的数据格式的示例文档。这可能是一份发票、数据录入表、报告、客户记录等。如果 PDF 文件是另一份文档的扫描版本,您可以 首先,使用光学字符识别(OCR)技术 以释放其数据,并使其准备好进行提取。
PDF提取器会显示您的样本文档,以便您可以开始定义模板和规则,以结构化地提取数据。 MapForce PDF提取器的简洁设计使其易于通过直观的方式指定PDF文档的结构,您可以通过点击和拖拽等操作来完成。
在PDF预览区域的旁边,还有一个模式(schema)区域,它会显示一个树状结构,用于表示PDF文件将如何被解析以及数据将如何被提取。
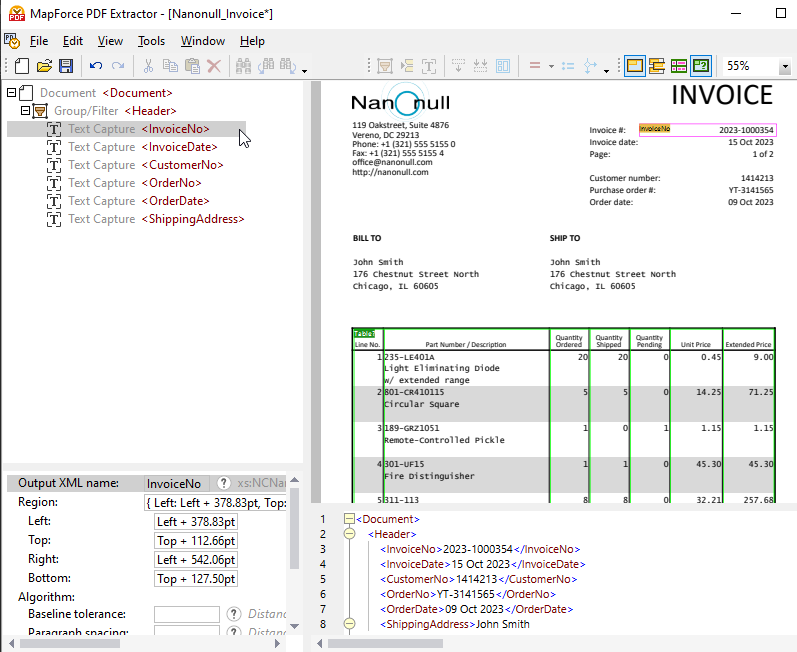
属性面板允许您定义属性并计算表达式,根据需要进行操作。在PDF文档视图的底部是输出面板(如上图所示),它允许您查看基于您定义的属性和提取规则的PDF数据提取结果的预览。输出结果以XML文档的形式呈现,其中包含用于描述结构关系的XML标签,以及正在提取的样本文件中实际的内容。
要提取文档的某些部分并添加到模式树中,只需选中需要提取的区域,然后右键单击以创建文本片段。
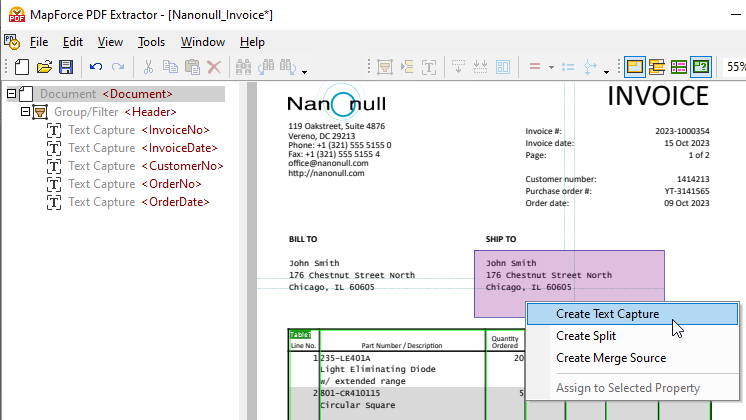
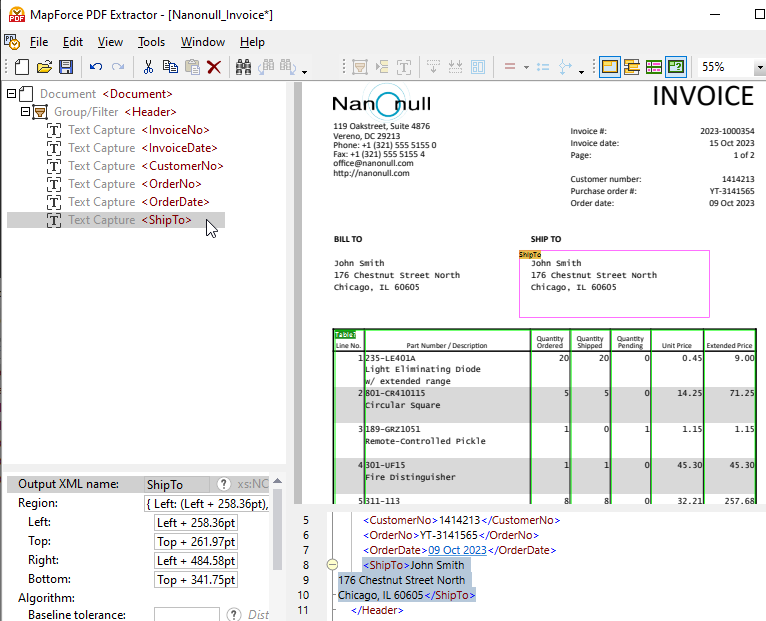
将新创建的元素拖动到树形结构中的所需位置,并为其指定一个具有描述性的名称。
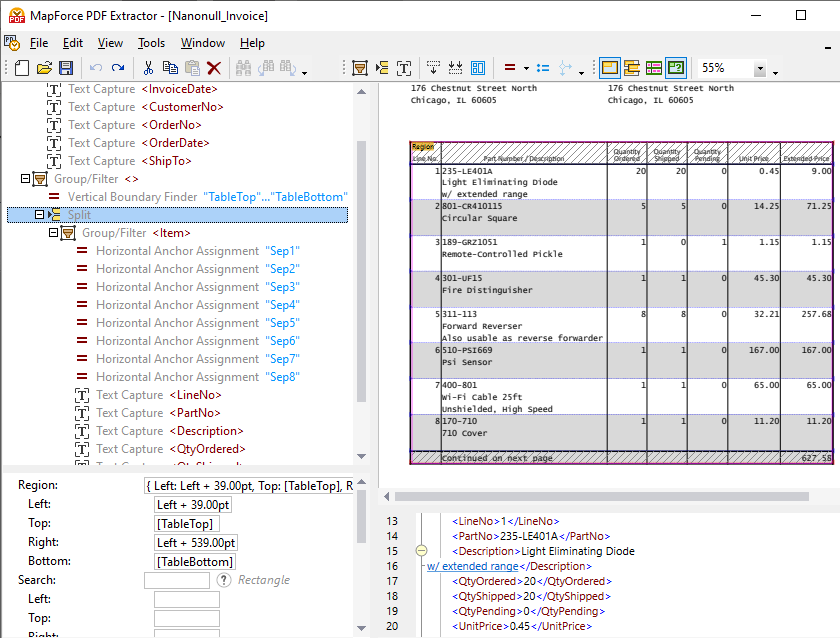
除了支持手动定义数据提取规则外,MapForce PDF 提取器还包含一个强大的建议引擎,该引擎能够自动识别常见文档元素并尝试检测其结构。例如,该建议引擎会识别文档中存在的表格,您可以选择自动提取这些表格,然后再根据需要进行调整。在模式面板中的“分割”操作符可以帮助您定义如何正确地将表格分割成独立的行。该建议引擎可以寻找边缘或线条来创建分割,也可以根据固定的距离进行分割,或者检测背景颜色的变化。您可以在 PDF 预览面板中查看分割效果。同时,该建议引擎还会提取列和标题文本,您可以根据需要进行精细调整,如上文视频所示。
点击模式树中的任何对象,都会高亮显示与之对应的结构和数据捕获规则,这些规则将应用于PDF文档的视图中。
将地图 PDF 文件转换为其他格式
一旦您在 MapForce PDF 提取器中完成了模板,您可以将其添加到 MapForce 数据映射项目中,从而高效地将 PDF 数据映射到其他支持的格式。只需拖放操作即可关联源节点和目标节点,并利用内置的数据处理函数库来转换 PDF 数据。常见的应用场景包括:
将PDF文件转换为Excel文件
将PDF文件转换为XML格式
将PDF文件转换为JSON格式
将PDF文件转换为SQL或NoSQL数据库系统
将PDF文件转换为EDI消息
将PDF文件转换为CSV或文本格式
除了以上这些情况,MapForce还支持链式数据映射流程,以及多种来源和目标数据结构。
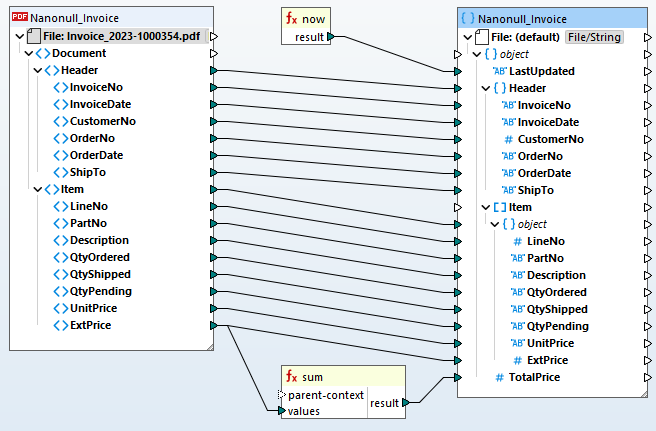
根据您定义的映射规则,MapForce 可以立即转换数据。或者,您可以使用 MapForce Server 高级版,实现重复的 PDF 转换以及 ETL (数据抽取、转换、加载) 流程。这使得组织能够自动化数据集成,并通过无缝地将 PDF 数据整合到现有的系统、数据库和工作流程中,从而简化流程。
使用 MapForce PDF 提取器,您可以: 下载免费试用版 来自 Altova 网站。