PDF 매핑을 위한 데이터 추출
Altova의 수상 경력에 빛나는 데이터 매핑 도구인 MapForce는 데이터 통합 및 ETL 워크플로우에서 PDF 입력을 지원합니다. MapForce PDF 추출기는 PDF 데이터를 구조화된 형식으로 추출하기 위한 규칙을 쉽게 정의할 수 있도록 지원하며, 이를 통해 추출된 데이터를 Excel, XML, JSON, 데이터베이스 등 다양한 형식으로 매핑하여 활용할 수 있습니다.
자, 이제 작동 방식을 살펴보겠습니다.

PDF 파일에서 데이터 추출하는 방법
PDF 파일 형식은 현재 다양한 분야에서 활용되며, 어떤 플랫폼이나 기기에서도 일관된 화면을 제공할 수 있다는 장점 덕분에 널리 사용되고 있습니다. PDF 파일은 텍스트, 이미지, 차트, 표 등 다양한 형식의 데이터를 결합하여 인간이 읽기 쉽도록 구성되며, 다양한 서식 옵션을 제공합니다.
하지만 PDF 파일은 데이터를 사용자 친화적인 방식으로 제시하는 데 유용하지만, 다른 비즈니스 시스템과의 통합을 위해 데이터를 효율적으로 추출하는 데 필요한 기본적인 구조가 부족합니다. 이는 흔히 요구되는 기능입니다. 기존의 데이터 추출 도구는 종종 PDF 파일에서 정확하게 정보를 추출하지 못하며, 특히 복잡한 레이아웃이나 다양한 서식 스타일을 사용할 때 문제가 발생합니다. 이로 인해 오류가 발생하고, 비효율성이 초래되며, 추출된 데이터를 수정하기 위해 수동 작업이 필요할 수 있습니다.
이러한 PDF 데이터 통합의 어려움을 해결하기 위해, Altova는 MapForce PDF 익스 트랙터(Extractor)라는 시각적인 도구를 개발했습니다. 이 도구를 사용하면 PDF 파일에서 구조화된 데이터를 추출하기 위한 규칙을 쉽게 정의할 수 있습니다.
이 튜토리얼 영상을 통해 MapForce PDF 추출기가 어떻게 작동하는지 알아보세요
MapForce PDF 추출기를 사용하는 가장 좋은 방법은 추출하고자 하는 데이터 형식을 가진 샘플 문서를 불러오는 것입니다. 이 문서는 송장, 데이터 입력 양식, 보고서, 고객 기록 등 다양한 형태일 수 있습니다. 만약 PDF 파일이 다른 문서의 스캔본이라면, 다음과 같이 할 수 있습니다 OCR 기능으로 시작하세요 데이터를 추출할 수 있도록 데이터를 해제하고 준비하는 과정입니다.
PDF 추출기는 사용자가 샘플 문서를 확인하고, 데이터를 체계적으로 추출하기 위한 템플릿과 규칙을 정의할 수 있도록 지원합니다. MapForce PDF 추출기의 간편한 디자인 덕분에 사용자는 마우스 클릭 및 드래그 앤 드롭 기능을 활용하여 PDF 문서의 구조를 시각적으로 쉽게 지정할 수 있습니다.
PDF 미리보기 창 옆에는 스키마 창이 표시되며, 이 창은 PDF 파일이 어떻게 분석되고 데이터가 추출될지를 나타내는 트리 구조를 보여줍니다.
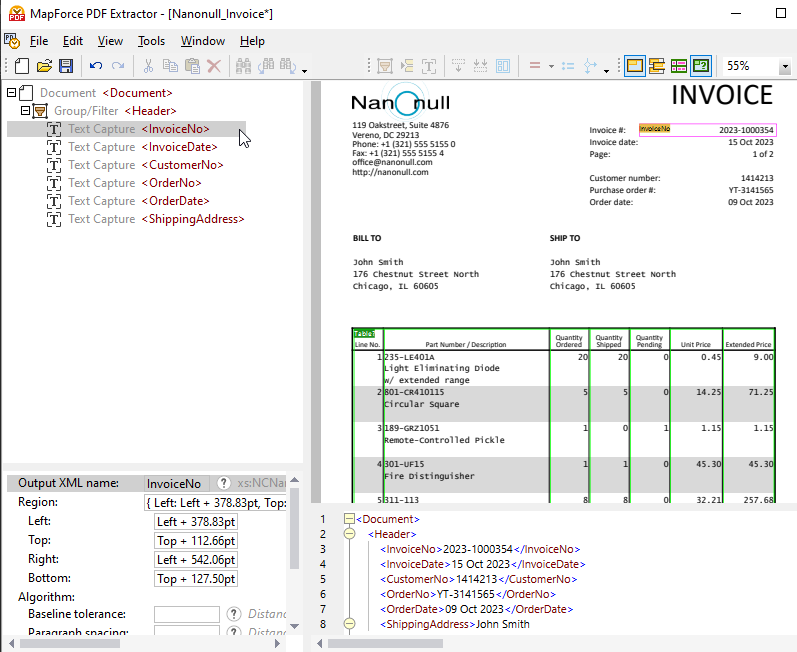
속성 창을 사용하면 필요에 따라 속성을 정의하고 수식을 계산할 수 있습니다. PDF 문서 보기 창 하단에는 결과 미리보기를 확인할 수 있는 출력 창(위 그림 참조)이 있습니다 PDF 데이터 추출 사용자가 정의한 속성 및 추출 규칙에 따라 결과가 생성됩니다. 결과는 XML 문서 형태로 표시되며, 이 문서에는 추출 대상 파일의 구조를 나타내는 XML 태그와 함께 실제 파일 내용이 포함됩니다.
문서의 특정 부분을 선택하여 스키마 트리에 추가하려면, 원하는 영역을 선택한 후 마우스 오른쪽 버튼을 클릭하여 텍스트 추출 기능을 사용하면 됩니다.
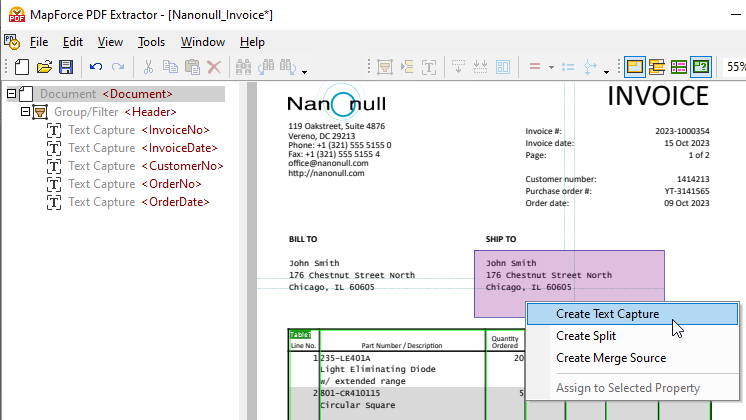
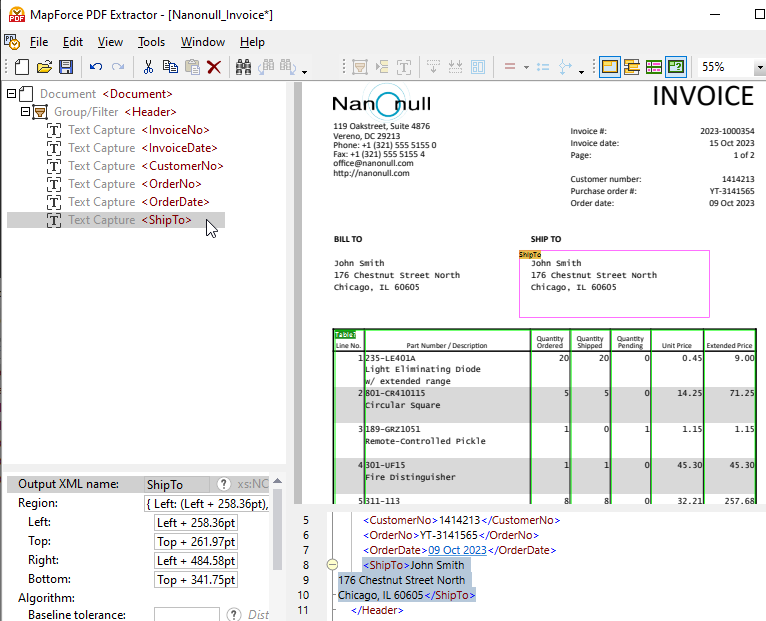
새로 생성된 요소를 원하는 위치로 드래그하여 이동시키고, 설명적인 이름을 지정해 주세요.
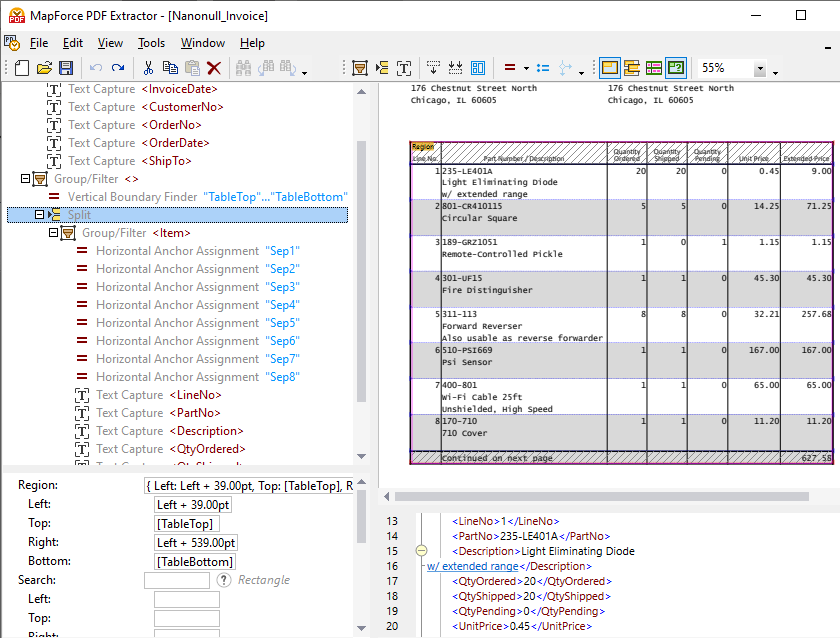
MapForce PDF 추출기는 데이터 추출 규칙을 수동으로 정의하는 기능 외에도 강력한 제안 엔진을 포함하고 있습니다. 이 엔진은 문서의 일반적인 요소들을 자동으로 식별하고, 해당 요소들의 구조를 파악하려고 시도합니다. 예를 들어, 제안 엔진은 문서 내에 존재하는 표를 식별하며, 사용자는 이 표를 자동으로 추출하고 필요에 따라 수정할 수 있습니다. 스키마 창에 있는 분할 기능은 표를 개별 행으로 정확하게 분할하는 방법을 정의하는 데 도움을 줍니다. 제안 엔진은 표의 경계선이나 선을 찾아 분할하거나, 고정된 거리로 분할하거나, 배경색의 변화를 감지하여 분할을 수행할 수 있습니다. 사용자는 PDF 미리보기 창에서 이러한 분할 결과를 미리 확인할 수 있습니다. 동시에, 제안 엔진은 열과 헤더 텍스트를 추출하며, 사용자는 위 영상에서 볼 수 있듯이 필요에 따라 이러한 추출 결과를 세밀하게 조정할 수 있습니다.
스키마 트리에서 어떤 객체를 클릭하면, 해당 객체와 관련된 구조 및 데이터 추출 규칙이 PDF 문서 보기에서 어떻게 적용되는지 강조 표시됩니다.
지도를 PDF 파일에서 다른 형식으로 변환하기
MapForce PDF 추출기에서 템플릿을 완성하면, 해당 템플릿을 MapForce 데이터 매핑 프로젝트에 추가하여 PDF 데이터를 다른 지원되는 형식으로 효율적으로 변환할 수 있습니다. 소스 노드와 대상 노드를 연결하려면 간단히 드래그 앤 드롭하면 되고, 내장된 데이터 처리 함수 라이브러리를 활용하여 PDF 데이터를 변환할 수 있습니다. 일반적인 활용 분야는 다음과 같습니다
PDF 파일을 엑셀 파일로 변환합니다
PDF 파일을 XML 형식으로 변환합니다
PDF 파일을 JSON 형식으로 변환합니다
PDF 파일을 SQL 또는 NoSQL 데이터베이스 시스템으로 변환
PDF 파일을 EDI 메시지로 변환
PDF 파일을 CSV 또는 텍스트 형식으로 변환합니다
이러한 시나리오 외에도, MapForce는 데이터 매핑 프로세스를 체인 방식으로 연결하는 기능과 다양한 소스 및 대상 데이터 구조를 지원합니다.
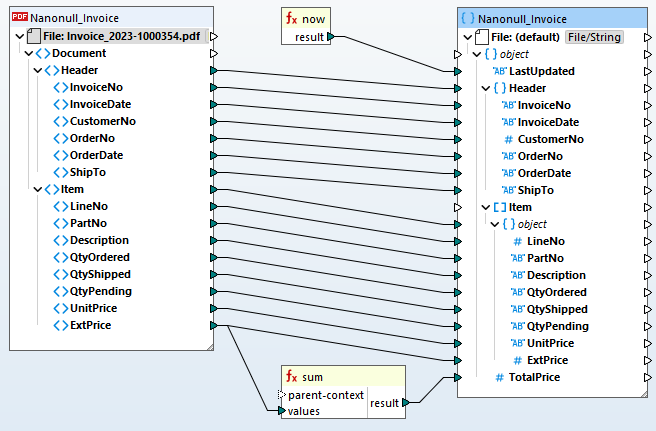
MapForce는 사용자가 정의한 데이터 매핑 규칙에 따라 데이터를 즉시 변환합니다. 또한, MapForce Server Advanced Edition을 사용하면 PDF 파일 변환 및 ETL(추출, 변환, 로드) 파이프라인을 반복적으로 실행할 수 있습니다. 이를 통해 기업은 데이터 통합을 자동화하고, 기존 시스템, 데이터베이스 및 워크플로우에 PDF 데이터를 원활하게 통합하여 프로세스를 효율화할 수 있습니다.
MapForce PDF 추출기를 사용하려면, Altova 웹사이트에서 무료 평가판을 다운로드하여 시작하십시오.