Extraire les données pour la cartographie PDF
MapForce, l'outil de cartographie de données primé d'Altova, prend en charge l'entrée de fichiers PDF dans les flux de travail d'intégration de données et d'ETL. L'outil d'extraction PDF de MapForce permet de définir facilement des règles pour extraire les données des fichiers PDF dans un format structuré, afin de les rendre disponibles pour être converties vers d'autres formats populaires tels qu'Excel, XML, JSON, des bases de données, et plus encore.
Voyons maintenant comment cela fonctionne.

Comment extraire des données à partir de fichiers PDF
Le format de fichier PDF est aujourd'hui largement utilisé dans tous les secteurs d'activité, grâce à sa capacité à offrir une présentation uniforme sur n'importe quelle plateforme ou appareil. Les fichiers PDF combinent généralement différentes manières de présenter les données, en utilisant des éléments adaptés à la lecture par les humains, tels que du texte, des images, des graphiques et des tableaux, le tout avec une variété d'options de mise en forme.
Cependant, bien que les fichiers PDF soient très utiles pour présenter des données de manière conviviale, ils ne possèdent aucune structure intégrée nécessaire pour extraire efficacement ces données et les intégrer à d'autres systèmes d'entreprise, ce qui est, bien sûr, une exigence courante. Les outils traditionnels d'extraction de données échouent souvent à capturer avec précision les informations contenues dans les fichiers PDF, en particulier lorsqu'il s'agit de mises en page complexes et de styles de formatage variés. Cela peut entraîner des erreurs, des inefficacités et la nécessité d'une intervention manuelle pour corriger les données extraites.
Pour répondre à ces difficultés d'intégration des données PDF, Altova a créé MapForce PDF Extractor, un outil visuel qui facilite la définition de règles pour extraire des données structurées à partir de fichiers PDF.
Apprenez comment fonctionne l'outil MapForce PDF Extractor grâce à cette vidéo explicative :
La meilleure façon de commencer à utiliser l'outil MapForce PDF Extractor est de charger un document d'exemple qui présente le format des données que vous souhaitez extraire. Il peut s'agir d'une facture, d'un formulaire de saisie de données, d'un rapport, d'un enregistrement client, etc. Si le document PDF est une version numérisée d'un autre document, vous pouvez commencer par utiliser la reconnaissance optique de caractères (OCR) pour déverrouiller ses données et le préparer pour l'outil d'extraction.
L'outil PDF Extractor affiche votre document de référence, ce qui vous permet de définir un modèle et des règles pour extraire les données de manière structurée. La conception simple de l'outil MapForce PDF Extractor facilite la spécification de la structure du document PDF de manière visuelle, grâce à des fonctionnalités de sélection et de glisser-déposer.
À côté de la zone d'affichage du fichier PDF, un volet de schéma affiche une structure arborescente qui représente la manière dont le fichier PDF sera analysé et les données seront extraites.
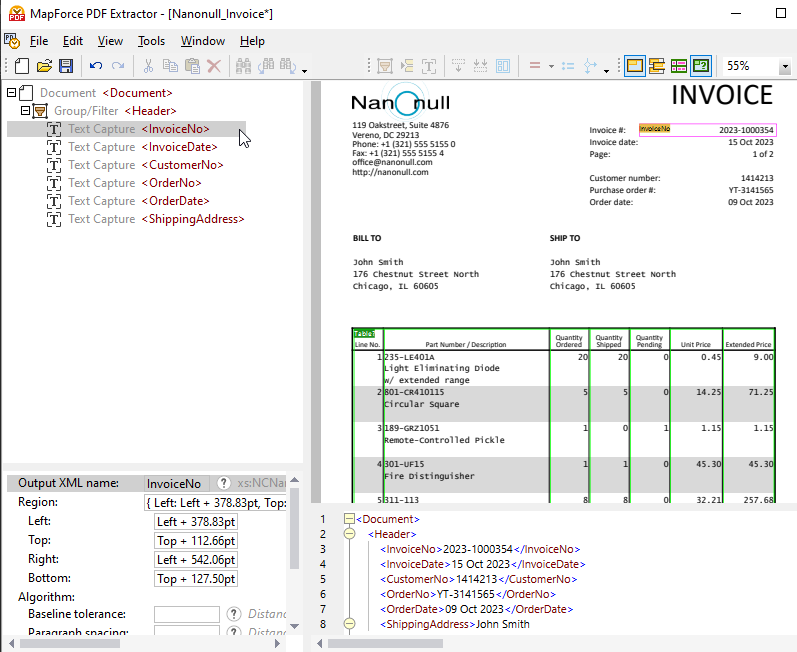
Le volet des propriétés vous permet de définir des propriétés et de calculer des expressions, selon vos besoins. En bas de la fenêtre de visualisation du document PDF, vous trouverez le volet de sortie (illustré ci-dessus), qui vous permet de visualiser un aperçu du résultat Extraction de données à partir de fichiers PDF basé sur les propriétés et les règles d'extraction que vous définissez. Le résultat est représenté par un document XML qui affiche les balises XML définissant la structure, ainsi que le contenu réel du fichier source à partir duquel l'extraction est effectuée.
Pour extraire des portions du document et les ajouter à l'arborescence du schéma, sélectionnez simplement la zone souhaitée, puis cliquez avec le bouton droit de la souris pour créer une capture de texte.
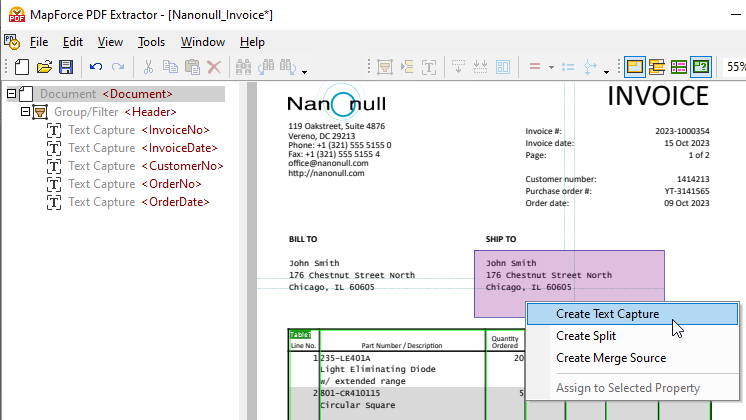
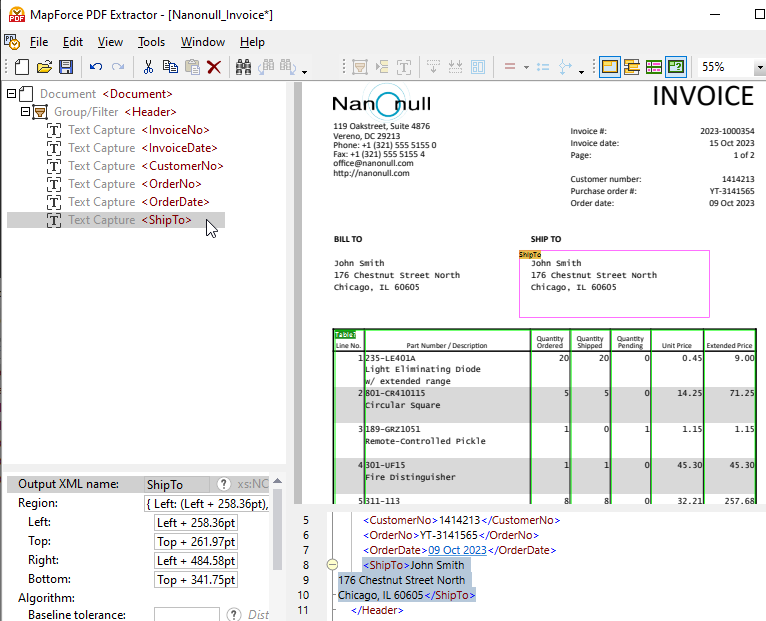
Faites glisser l'élément nouvellement créé vers l'emplacement souhaité dans l'arborescence, puis attribuez-lui un nom descriptif.
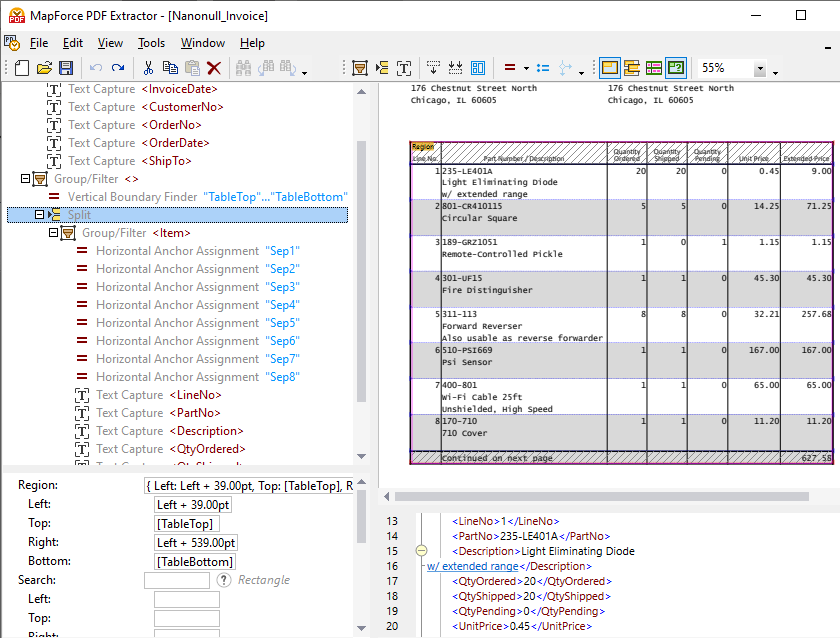
En plus de la possibilité de définir manuellement les règles d'extraction de données, l'outil MapForce PDF Extractor intègre un moteur de suggestions puissant qui identifie automatiquement les éléments courants des documents et tente de détecter leur structure. Par exemple, le moteur de suggestions identifiera les tableaux présents dans le document, que vous pouvez choisir d'extraire automatiquement, puis d'affiner si nécessaire. L'opérateur de division, présent dans le panneau de schéma, vous aide à définir comment diviser correctement le tableau en lignes distinctes. Le moteur de suggestions peut rechercher des bordures ou des lignes pour effectuer la division, diviser en fonction d'une distance fixe, ou détecter des changements dans la couleur de fond, ce que vous pouvez visualiser dans le panneau d'aperçu PDF. Parallèlement, le moteur de suggestions capture les colonnes et le texte des en-têtes, que vous pouvez affiner si nécessaire, comme vous pouvez le constater dans la vidéo ci-dessus.
En cliquant sur n'importe quel objet dans l'arborescence du schéma, la structure correspondante et les règles de capture de données sont mises en évidence, telles qu'elles s'appliquent dans la vue du document PDF.
Convertir des fichiers PDF de cartes vers d'autres formats
Une fois que votre modèle dans l'outil MapForce PDF Extractor est terminé, vous pouvez l'ajouter à un projet de mappage de données MapForce afin de convertir efficacement les données PDF vers d'autres formats pris en charge. Il suffit de glisser-déposer pour associer les nœuds source et cible, et de profiter de la bibliothèque intégrée de fonctions de traitement des données pour transformer les données PDF. Les applications courantes incluent :
PDF en Excel
PDF en XML
PDF en JSON
Conversion de fichiers PDF vers des systèmes de bases de données SQL ou NoSQL
PDF aux messages EDI
Conversion de fichiers PDF en fichiers CSV ou texte
En plus de ces scénarios, MapForce prend en charge les processus de transformation de données en chaîne, ainsi que de multiples structures de données sources et cibles.
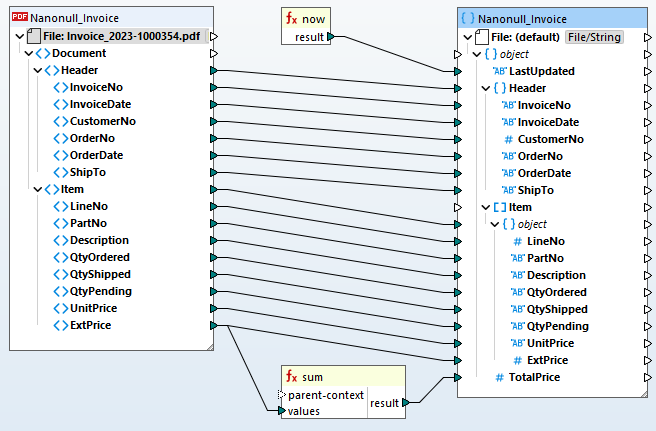
Grâce à la définition de la correspondance de données que vous avez établie, MapForce transforme les données instantanément. Vous pouvez également utiliser MapForce Server Advanced Edition pour les transformations PDF répétitives et les pipelines ETL. Cela permet aux organisations d'automatiser l'intégration des données et de rationaliser les processus en intégrant de manière transparente les données PDF dans leurs systèmes, bases de données et flux de travail existants.
Commencez à utiliser l'outil d'extraction PDF de MapForce en.. télécharger une version d'essai gratuite provenant du site web d'Altova.