Le tecnologie per i Big Data, i database e gli strumenti XBRL ottengono un notevole impulso
È arrivato il momento di presentare l'ultima versione di MissionKit e dei prodotti software server di Altova, e questa versione offre un notevole miglioramento delle funzionalità per lavorare con grandi quantità di dati, database, XBRL e molto altro.
Con il supporto per Apache Avro in diversi prodotti, l'aggiunta di nuovi database e driver per l'intera gamma di prodotti, e due nuove specifiche XBRL per i prodotti per sviluppatori e server, oltre a un nuovo modo per creare e gestire i moduli PDF, la versione 2017 mette in connessione tutti i dati.
Quale sarà la nuova funzionalità che vi piacerà di più? Scopriamolo insieme.

Funzionalità di ricerca e sostituzione potenziata
Probabilmente, il miglioramento più immediato in termini di produttività offerto in questa nuova versione si riscontra in XMLSpy, nello specifico per il lavoro in modalità visualizzazione del testo. Abbiamo completamente ridisegnato e modernizzato la finestra di dialogo "Trova" e abbiamo aggiunto nuove funzionalità potenti.
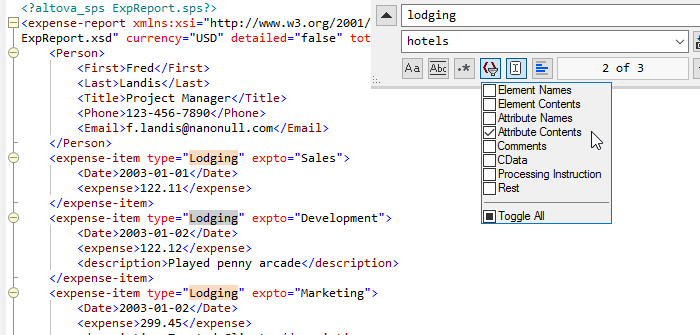
La nuova finestra di dialogo, che non richiede di essere chiusa per poter continuare a lavorare, rimane aperta mentre si lavora, evidenziando immediatamente tutte le occorrenze di un termine di ricerca non appena viene digitato, consentendo di individuare e accedere a ciascuna occorrenza molto più rapidamente rispetto a prima. Ora è possibile effettuare ricerche all'interno di una selezione di testo o selezionare una stringa di testo per evidenziare istantaneamente tutte le occorrenze all'interno del documento, con indicazioni di tutte le corrispondenze sia nella visualizzazione del testo che sulla barra di scorrimento.
Tutte le potenti e avanzate funzionalità della finestra di dialogo "Trova" sono, naturalmente, ancora disponibili, tra cui la possibilità di filtrare i risultati in base a criteri dettagliati (nomi di elementi/attributi, contenuto, ecc.) e la ricerca tramite espressioni regolari.
Strumenti Apache Avro
Visualizzazione, validazione, modifica e Avro
Apache Avro™ è ampiamente utilizzato come formato di serializzazione binaria compatto e veloce per i Big Data, in particolare all'interno del framework Hadoop. Nonostante questa popolarità, tuttavia, da tempo esiste una necessità insoddisfatta di poter lavorare con i dati Avro in formato binario in modo intuitivo. Ed è qui che entra in gioco XMLSpy 2017.
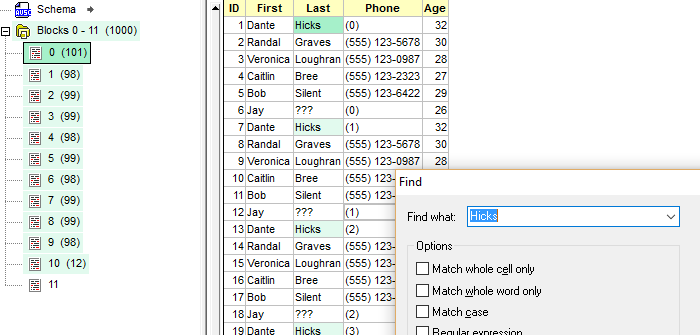
Con il nuovo strumento Avro View, è possibile visualizzare immediatamente le strutture di dati binarie in un formato tabellare facile da leggere.
Poiché i file Avro sono estremamente grandi, una sezione chiamata "Blocchi" organizza i dati in gruppi, che è possibile visualizzare con un semplice clic. Inoltre, Avro View consente di effettuare ricerche in questi enormi file di dati a una velocità elevatissima.
È inoltre possibile estrarre e, facoltativamente, modificare lo schema Avro. Poiché si tratta di un file JSON, lo schema Avro può essere modificato nella visualizzazione a griglia di XMLSpy per una rappresentazione visiva, oppure nella visualizzazione testuale. Entrambe le opzioni offrono suggerimenti per la modifica e strumenti di assistenza intelligenti per l'inserimento dei dati.
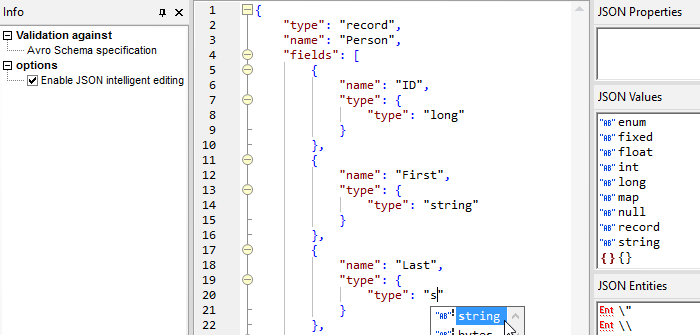
Durante la fase di editing, viene effettuata una verifica di validazione rispetto alle specifiche dello schema Avro.
Elaborazione ad alte prestazioni
Per validazione ultra-rapida dei dati Avro, Il server RaptorXML offre prestazioni elevate. Ottimizzato per l'elaborazione di grandi quantità di dati, il server RaptorXML supporta numerosi comandi di elaborazione Avro, tra cui l'estrazione dello schema da un file di dati Avro, la validazione degli schemi Avro e la verifica delle istanze Avro rispetto al loro schema associato.
Nuove funzionalità del database
Supporto esteso per database
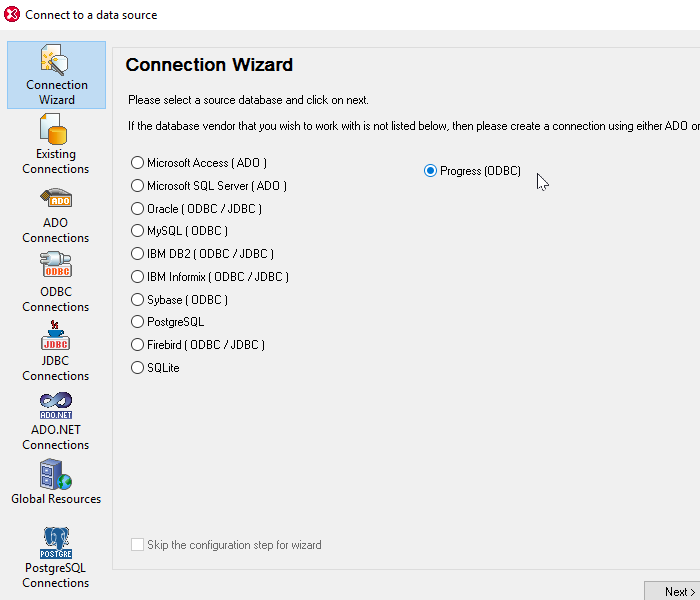
L'integrazione con database avanzati è presente in tutto il set di strumenti per sviluppatori desktop Altova MissionKit, e stiamo continuamente aggiungendo nuove funzionalità in base agli sviluppi del settore e ai feedback dei clienti.
È ora disponibile un nuovo supporto per l'intera gamma di prodotti, che riguarda:
- Supporto per i driver di database ADO.NET – aggiunge un'ulteriore opzione ai driver ADO, ODBC e JDBC esistenti
- Supporto nativo per PostgreSQL - Il supporto nativo elimina la necessità di driver intermedi, quindi lavorare con i database PostgreSQL è più veloce, più semplice e richiede meno memoria
- Supporto per i database OpenEdge - abbiamo ricevuto numerose richieste per includere questo database tra quelli supportati
- Supporto per SQL Server 2016 – estende il supporto alle versioni precedenti
Strumenti di mappatura dei database
Inoltre, supporto per database in MapForce È stata migliorata la funzionalità che consente di eseguire operazioni su tabelle di database come istruzioni SQL di tipo "merge". Per determinate mappature che aggiornano e inseriscono dati in una tabella di database, e che di solito richiedono le operazioni "aggiorna se" e "inserisci il resto", MapForce può ora generare istruzioni SQL di tipo "merge" da eseguire sul database. Questo migliora la velocità di esecuzione, riducendo il numero di chiamate al server del database, poiché combina le istruzioni INSERT e UPDATE in un'unica istruzione.
I nostri test indicano che l'esecuzione massiva di istruzioni SQL Merge tramite MapForce Server può essere fino a 15 volte più efficiente rispetto alle tecniche precedenti*.
*Nota: si prega di verificare la fonte originale per i dettagli specifici relativi a questa affermazione.
Supporto per specifiche XBRL aggiuntive
Gli strumenti per lo sviluppo e l'elaborazione completa di XBRL sono disponibili in tutta la gamma di prodotti Altova, e questa ultima versione aggiunge funzionalità per lavorare con due specifiche più recenti: i pacchetti di tassonomia XBRL e l'XBRL inline.
Pacchetti di tassonomia XBRL
Le tassonomie XBRL sono generalmente composte da numerosi documenti correlati, per questo motivo vengono spesso raggruppate in un unico file ZIP.
La specifica XBRL Taxonomy Packages rende questo approccio più pratico definendo un formato standard e una posizione per un file all'interno di quell'archivio ZIP, che contiene informazioni importanti, tra cui una descrizione del pacchetto e il punto di accesso. Il pacchetto di tassonomia contiene un file XML di catalogo che rimappa gli URI alle posizioni dei file della tassonomia offline, rendendo la tassonomia disponibile offline per le applicazioni.
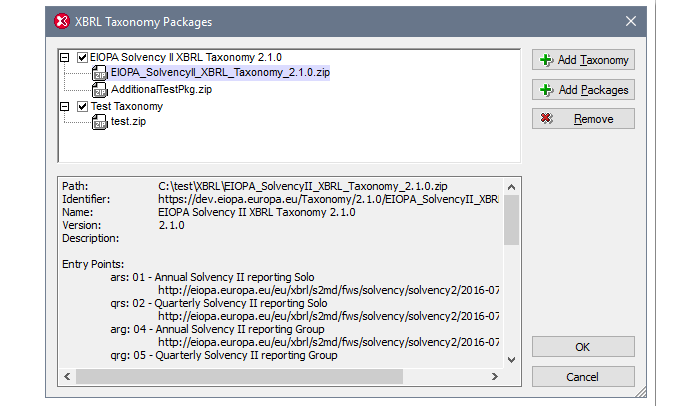
Abbiamo ora aggiunto il supporto per l'accesso alle risorse offline all'interno di un pacchetto di tassonomia XBRL, sia in XMLSpy per lo sviluppo, sia in RaptorXML+XBRL Server per la validazione ad alta velocità lato server.
XBRL integrato
La specifica Inline XBRL (iXBRL) estende XBRL consentendo alle aziende di integrare direttamente i propri dati XBRL all'interno di un documento HTML, combinando così i vantaggi dei dati etichettati con un rapporto facilmente comprensibile.
Poiché i dati XBRL contenuti in un documento iXBRL devono comunque essere estratti in un documento istanza XBRL per ulteriori elaborazioni, XMLSpy ora offre questa funzionalità con il comando "Trasforma iXBRL inline". È inoltre possibile validare i file iXBRL sul server RaptorXML+XBRL.
Nuovo componente aggiuntivo per Excel che genera file XBRL
Siamo lieti di annunciare il lancio di un nuovo prodotto per la generazione diretta di documenti XBRL all'interno di Excel. L'estensione European Banking Authority (EBA) XBRL per Excel è rivolta alle istituzioni che presentano comunicazioni all'EBA in formato XBRL. Consente agli utenti di inserire i dati direttamente in Excel, dove sono già abituati a lavorare. In background, l'estensione salva i dati in un documento XBRL valido, basato sulla tassonomia XBRL dell'EBA, pronto per la presentazione.
Moduli PDF compilabili
StyleVision, nota per la creazione di report accattivanti e multicanale in formato PDF e altri formati, ha appena introdotto importanti nuove funzionalità per i progettisti che creano moduli PDF compilabili. Tutti gli strumenti di progettazione intuitivi di StyleVision sono ora disponibili per i moduli PDF, semplificando la creazione di questi strumenti funzionali per la raccolta dei dati degli utenti.
Che siate alle prime armi o che vogliate basare il vostro progetto su un modello esistente importato in StyleVision, avrete accesso a tutte le funzionalità avanzate di StyleVision, agli strumenti di supporto per la compilazione e alle guide per la progettazione di componenti grafici statici e dinamici, da utilizzare nei moduli.
Una volta che gli utenti inseriscono i propri dati, le organizzazioni possono estrarre tali dati in formato XML o FDF utilizzando il software StyleVision Server, elaborarli ulteriormente per generare report e così via.
Questa potente funzionalità aggiunge immediatamente maggiore valore al flusso di lavoro dei moduli PDF.
Versioni in lingua francese
Come ultima nota, tutti i prodotti MissionKit e i software server sono ora disponibili anche in versione francese, in aggiunta a quelle già disponibili in inglese, tedesco, spagnolo e giapponese.
Aggiorna ora
Potete aggiornare il sistema o ottenere maggiori informazioni su queste nuove funzionalità – e le numerose altre funzionalità introdotte nella versione più recente – su Altova Pagina delle novità.
- I risultati delle prestazioni si basano su test interni di Altova e potrebbero variare.