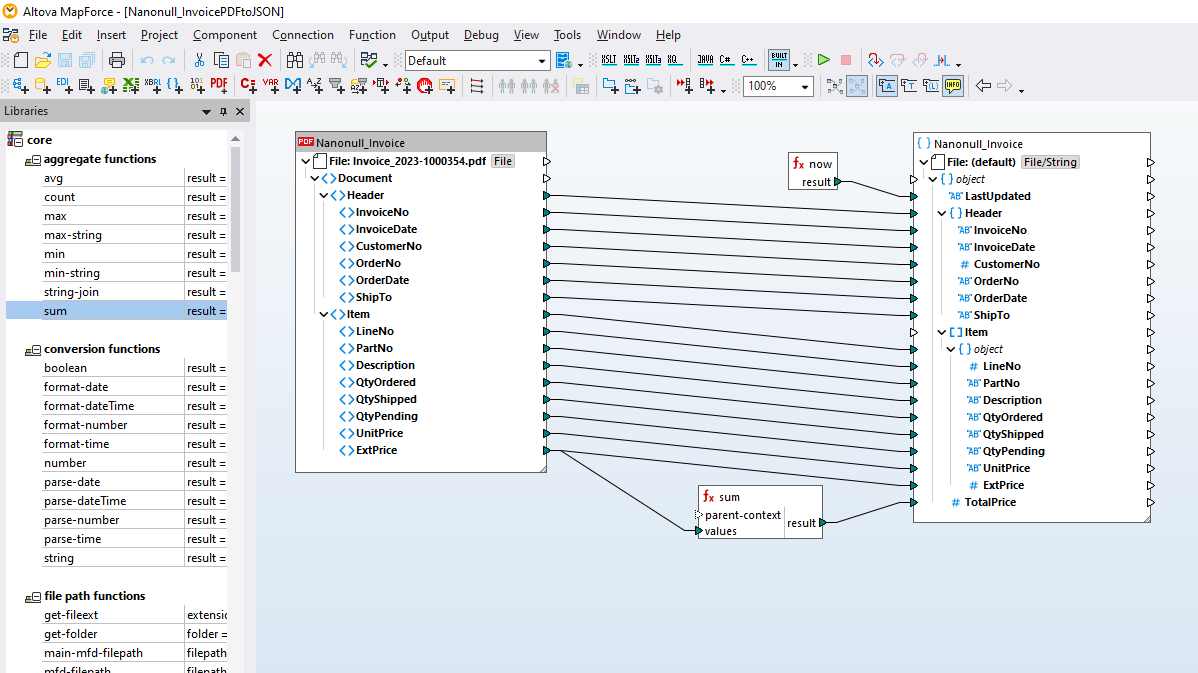
Sebbene il formato PDF sia oggi ampiamente utilizzato in ambito aziendale, i dati contenuti nei PDF non sono facilmente accessibili per essere integrati in altri sistemi. I PDF sono generalmente progettati per contenuti leggibili dagli esseri umani, con formattazioni e layout variabili, il che rende l'estrazione di dati strutturati estremamente complessa. Possono contenere testo, immagini, tabelle e altri elementi, e i dati non sono organizzati in un formato leggibile dalle macchine. Gli strumenti tipici di estrazione dati da PDF potrebbero non fornire risultati accurati, soprattutto per i PDF con layout complessi. Ed è qui che entra in gioco il MapForce PDF Extractor.
Il MapForce PDF Extractor è un'applicazione semplice da usare che consente di definire rapidamente la struttura di un documento PDF ed estrarne i dati. Successivamente, questi dati PDF possono essere utilizzati in MapForce per ulteriori trasformazioni e conversioni in altri formati, come XML, JSON, database, Excel, e così via. È lo strumento ideale per facilitare l'integrazione dei dati PDF e i progetti ETL.
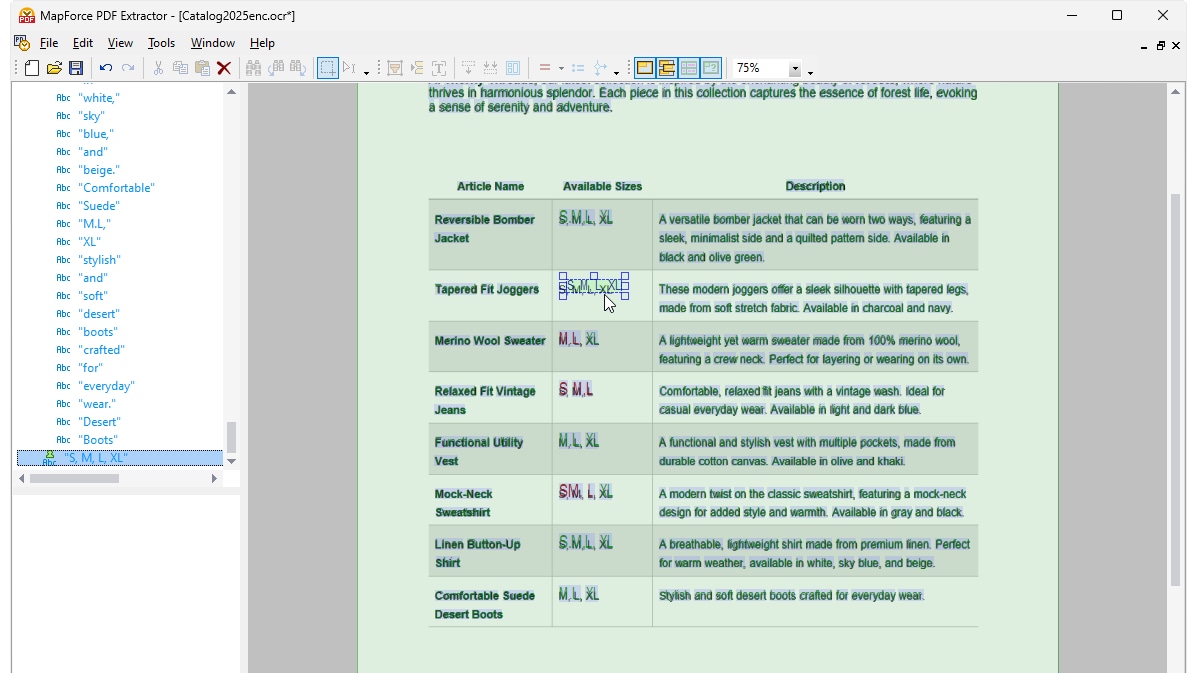
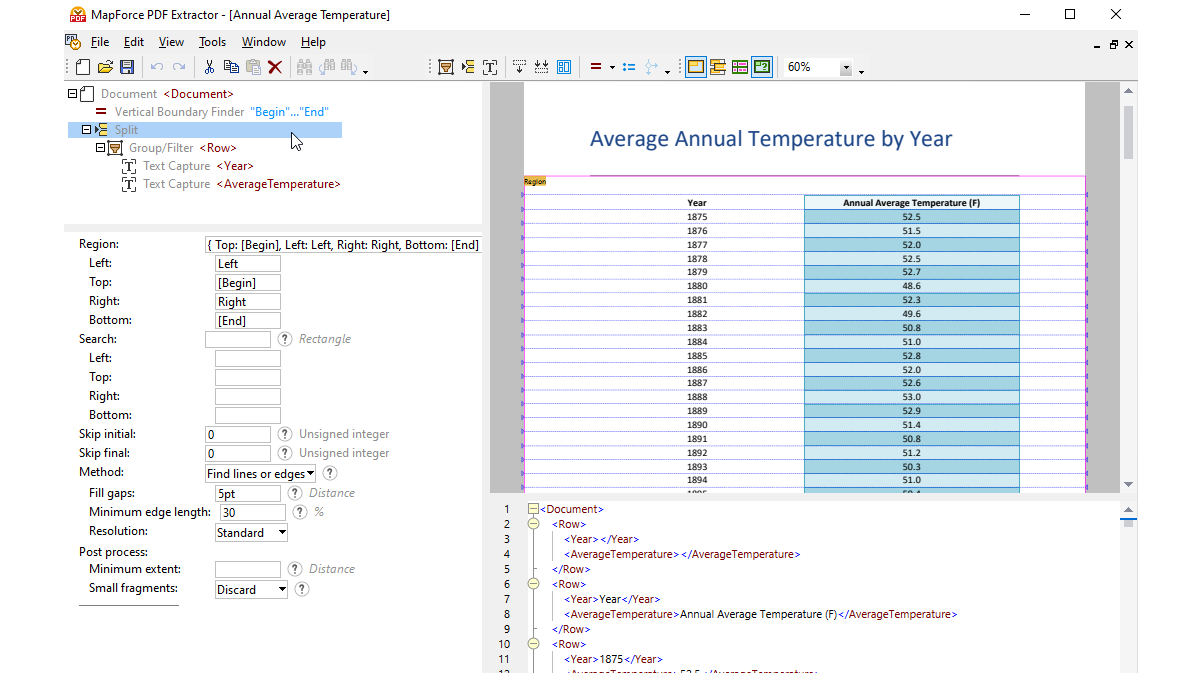
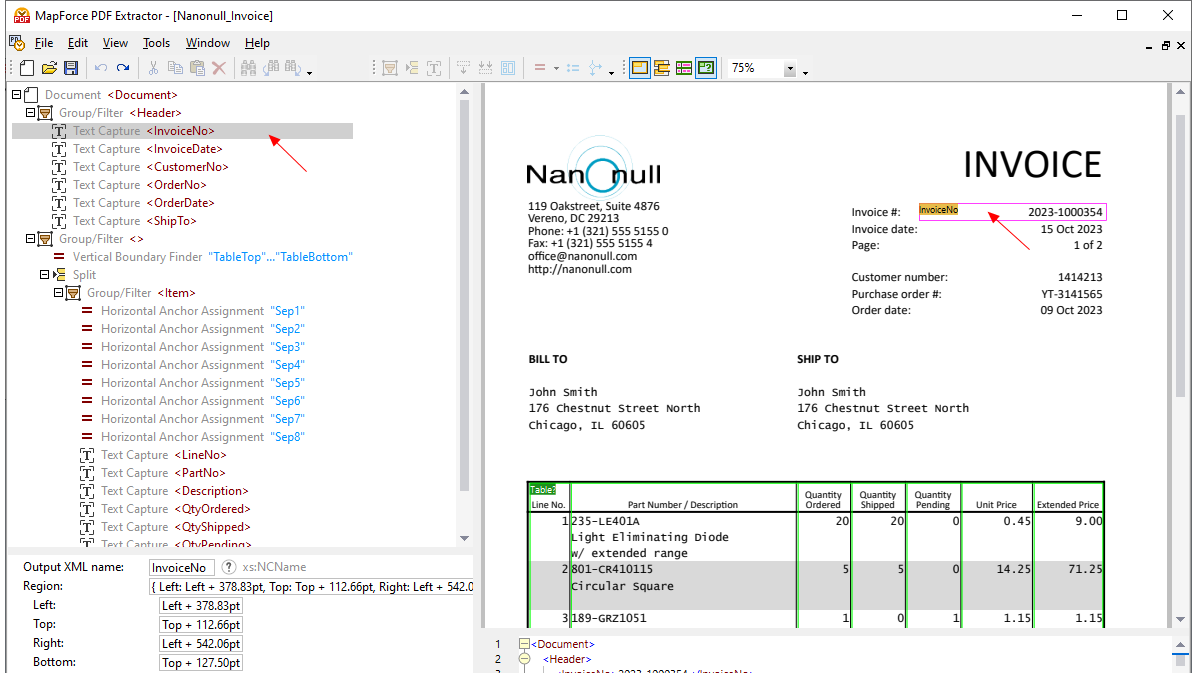
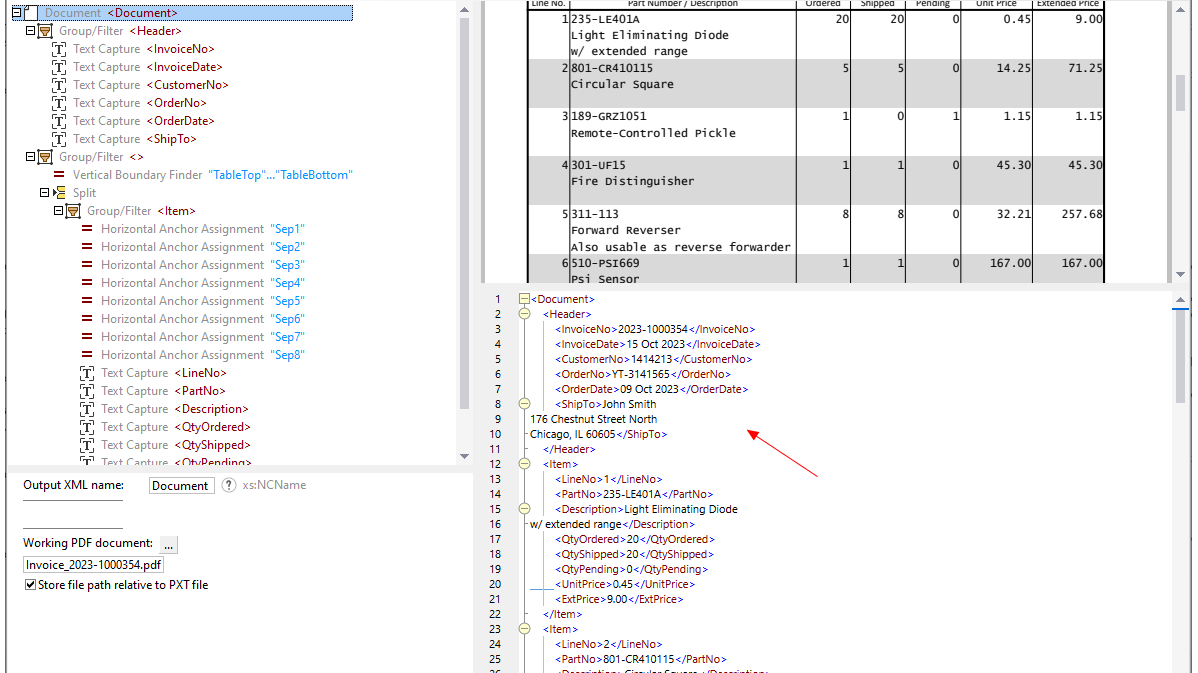
Utilizzando gli strumenti visivi integrati in MapForce PDF Extractor, è possibile definire la struttura di un documento PDF ed estrarne i dati in modo efficiente. PDF Extractor è uno strumento estremamente flessibile che consente di estrarre solo porzioni di testo, invece dell'intero documento, di combinare informazioni provenienti da diverse pagine dello stesso file PDF, di suddividere le tabelle in righe e di organizzare i dati in gruppi.
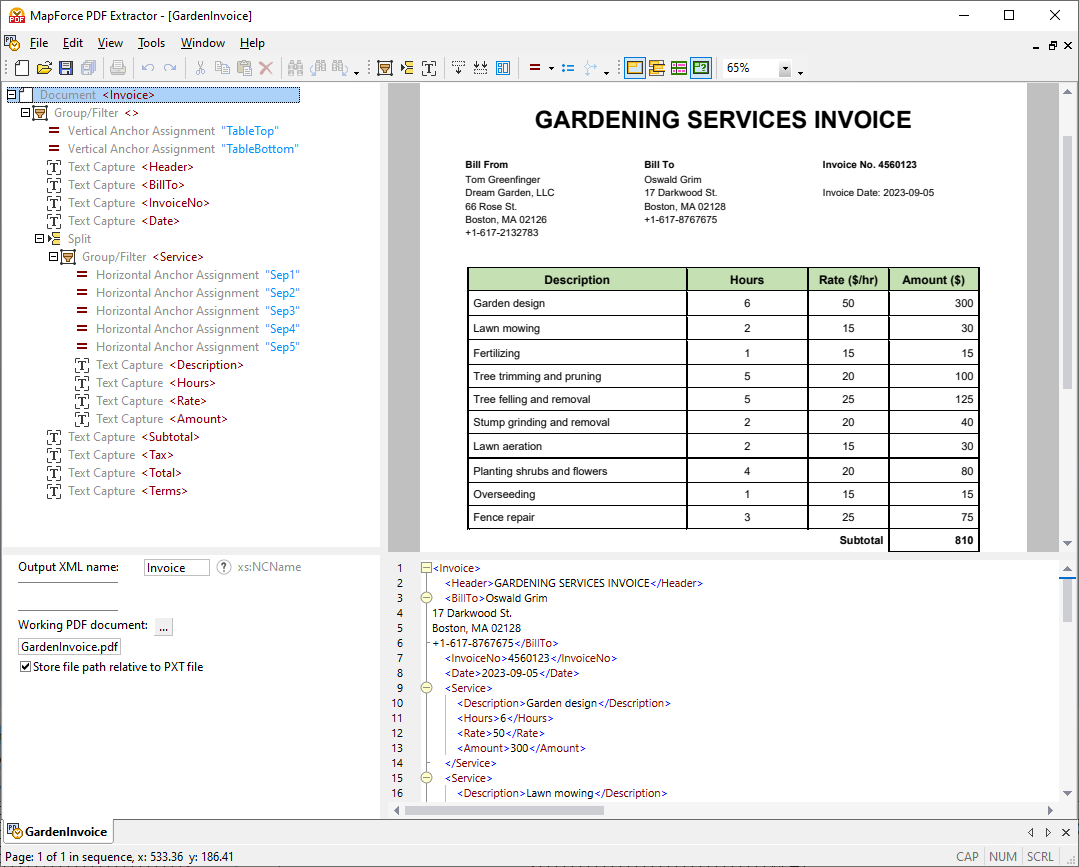
Il design intuitivo e semplice del MapForce PDF Extractor rende facile definire la struttura dei documenti PDF in modo visivo, utilizzando funzionalità di selezione con il mouse e di trascinamento. Finalmente, l'enorme quantità di dati precedentemente bloccati all'interno dei file PDF è disponibile per essere convertita in altri formati.