Example: Reading XML Documents (Java)
After you generate code from the example schema, a test Java project is created, along with several supporting Altova libraries.
About the generated Java libraries
The central class of the generated code is the Doc2 class, which represents the XML document. Such a class is generated for every schema and its name depends on the schema file name. Note that this class is called Doc2 to avoid a possible conflict with the namespace name. As shown in the diagram, this class provides methods for loading documents from files, binary streams, or strings (or saving documents to files, streams, strings). For a description of this class, see the com.[YourSchema].[Doc] class reference.
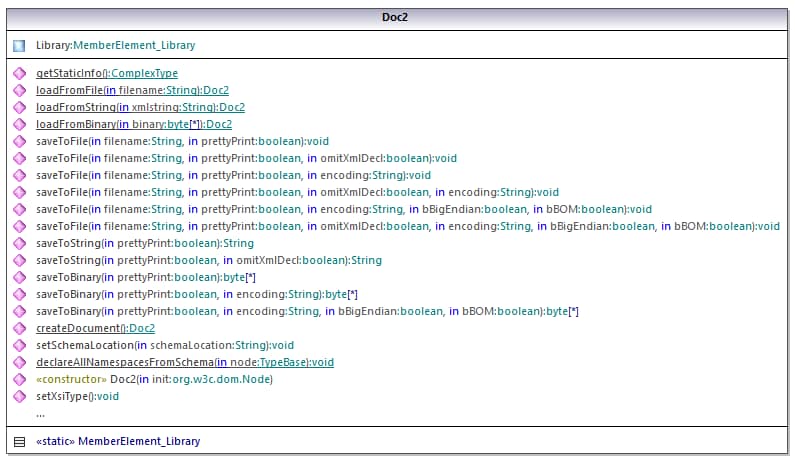
The Library member of the Doc2 class represents the actual root of the document.
According to the code generation rules mentioned in About Generated Java Code, member classes are generated for each attribute and for each element of a type. In the generated code, the name of such member classes is prefixed with MemberAttribute_ and MemberElement_, respectively. In the diagram below, examples of such classes are MemberAttribute_ID and MemberElement_Author, generated from the Author element and ID attribute of a book, respectively. Such classes enable you to manipulate programmatically the corresponding elements and attributes in the instance XML document (for example, append, remove, set value, etc). For more information, see the com.[YourSchema].[YourSchemaType].MemberAttribute and com.[YourSchema].[YourSchemaType].MemberElement class reference.
Since the DictionaryType is a complex type derived from BookType in the schema, this relationship is also reflected in the generated classes. As illustrated in the diagram below, the class DictionaryType inherits the BookType class.
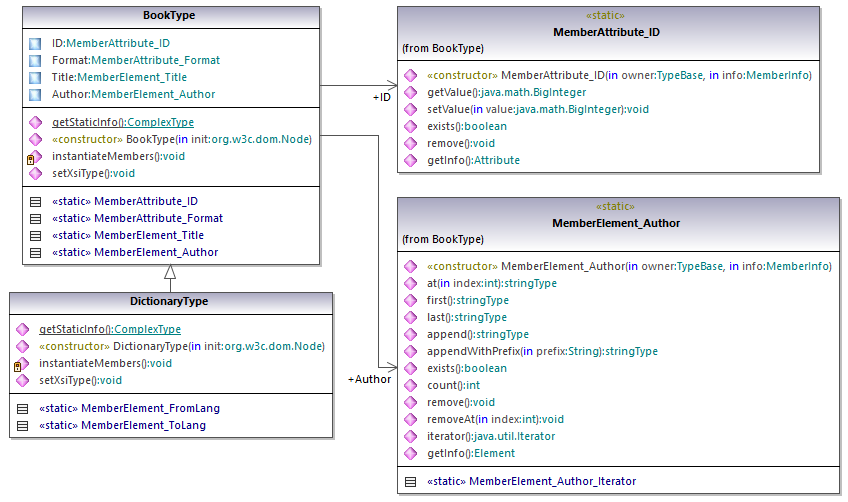
If your XML schema defines simple types as enumerations, the enumerated values become available as Enum values in the generated code. In the schema used in this example, a book format can be hardcover, paperback, e-book, and so on. Therefore, in the generated code, these values would be available through an Enum that is a member of the BookFormatType class.
Writing an XML document
1.On the File menu of Eclipse, click Import, select Existing Projects into Workspace, and click Next.
2.Next to Select root directory, click Browse, select the directory to which you generated the Java code, and then click Finish.
3.In the Eclipse Package Explorer, expand the com.LibraryTest package and open the LibraryTest.java file.
While prototyping an application from a frequently changing XML schema, you may need to frequently generate code to the same directory, so that the schema changes are immediately reflected in the code. Note that the generated test application and the Altova libraries are overwritten every time when you generate code into the same target directory. Therefore, do not add code to the generated test application. Instead, integrate the Altova libraries into your project (see Integrating Schema Wrapper Libraries). |
4.Edit the Example() method as shown below.
protected static void example() throws Exception { |
5.Build the Java project and run it. If the code is executed successfully, a Library1.xml file is created in the project directory.
Reading an XML document
1.On the File menu of Eclipse, click Import, select Existing Projects into Workspace, and click Next.
2.Next to Select root directory, click Browse, select the directory to which you generated the Java code, and then click Finish.
3.Save the code below as Library1.xml to a local directory (you will need to refer to the path of the Library1.xml file from the sample code below).
<?xml version="1.0" encoding="utf-8"?> |
4.In the Eclipse Package Explorer, expand the com.LibraryTest package and open the LibraryTest.java file.
5.Edit the Example() method as shown below.
protected static void example() throws Exception { |
6.Build the Java project and run it. If the code is executed successfully, Library1.xml will be read by the program code, and its contents displayed in the Console view.
Reading and writing elements and attributes
Values of attributes and elements can be accessed using the getValue() method of the generated member element or attribute class, for example:
// output values of ID attribute and (first and only) title element |
To get the value of the Title element in this particular example, we also used the first() method, since this is the first (and only) Title element of a book. For cases when you need to pick a specific element from a list by index, use the at() method.
To iterate through multiple elements, use either index-based iteration or java.util.Iterator. For example, you can iterate through the books of a library as follows:
// index-based iteration |
To add a new element, use the append() method. For example, the following code appends an empty root Library element to the document:
// create the root element <Library> and add it to the document |
Once an element is appended, you can set the value of any of its elements or an attributes by using the setValue() method.
// set the value of the Title element |
Reading and writing enumeration values
If your XML schema defines simple types as enumerations, the enumerated values become available as Enum values in the generated code. In the schema used in this example, a book format can be hardcover, paperback, e-book, and so on. Therefore, in the generated code, these values would be available through an Enum (see the BookFormatType class diagram above). To assign enumeration values to an object, use code such as the one below:
// set an enumeration value |
You can read such enumeration values from XML instance documents as follows:
// read an enumeration value |
When an "if" condition is not enough, create a switch to determine each enumeration value and process it as required.
Working with xs:dateTime and xs:duration types
If the schema from which you generated code uses time and duration types such as xs:dateTime, or xs:duration, these are converted to Altova native classes in generated code. Therefore, to write a date or duration value to the XML document, do the following:
1.Construct a com.altova.types.DateTime or com.altova.types.Duration object.
2.Set the object as value of the required element or attribute, for example:
// set the value of an attribute of DateTime type |
To read a date or duration from an XML document:
1.Declare the element value (or attribute) as com.altova.types.DateTime or com.altova.types.Duration object.
2.Format the required element or attribute, for example:
// read a DateTime type |
For more information, see com.altova.types.DateTime and com.altova.types.Duration class reference.
Working with derived types
If your XML schema defines derived types, you can preserve type derivation in XML documents that you create or load programmatically. Taking the schema used in this example, the following code listing illustrates how to create a new book of derived type DictionaryType:
// create a dictionary (book of derived type) and populate its elements and attributes |
Note that it is important to set the xsi:type attribute of the newly created book. This ensures that the book type will be interpreted correctly by the schema when the XML document is validated.
When you load data from an XML document, the following code listing shows how to identify a book of derived type DictionaryType in the loaded XML instance. First, the code finds the value of the xsi:type attribute of the book node. If the namespace URI of this node is http://www.nanonull.com/LibrarySample, and if the URI lookup prefix and type matches the value of the xsi:type attribute, then this is a dictionary:
// find the derived type of this book |