Scanned Documents (OCR)
The MapForce PDF Extractor can perform optical character recognition (OCR) on scanned PDF documents, enabling you to extract text from them. This topic provides an overview of the OCR document structure and describes the OCR objects.
The OCR functionality in the PDF Extractor is based on Tesseract OCR and is integrated as a pre-processing step.
Overview of the OCR document structure
The PDF Extractor treats a scanned PDF document as a structured object called a Document, which is divided into Pages. Each Page contains a ScanArea and DetectedWords and can also contain UserWords. The model tree below shows the hierarchy of OCR objects:
Document
Pages
Page
UserWord
ScanArea
DetectedWord
The main characteristics of each object are described below:
•Document: Contains a list of Pages.
•Page: Contains UserWords, ScanAreas, and DetectedWords. By default, there is one Page object for each page in a document.
•ScanArea: Defines the region scanned by OCR. By default, there is one ScanArea for each Page; the ScanArea covers the entire page and is set to the Sparse Text page segmentation mode (see details below).
•UserWord: Manually entered words.
•DetectedWord: Automatically detected by OCR. If you edit a DetectedWord, it becomes a UserWord. DetectedWords can be included, excluded, or replaced with a UserWord if needed.
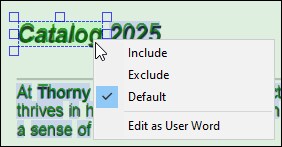
Context menu of DetectedWords
Each DetectedWord has a context menu (screenshot below), which enables you to:
•Explicitly include or exclude the DetectedWord. The OCR processor might correctly detect a word but assign only 20% confidence, in which case you might want to include the word manually. The processor might also incorrectly detect a word, which you might need to exclude.
•Select the default option, which lets the OCR processor decide what to include or exclude. DetectedWords are automatically included if the confidence is high enough (≥ 50%). DetectedWords are excluded if they are hidden behind another ScanArea.
•Edit DetectedWords as UserWords. To edit a DetectedWord, you can also double-click it in the scan area of the PDF document.
Properties of ScanArea
The ScanArea object has the following properties:
•Language
•Engine Mode
•Page Segmentation
•Parameters
Language
Specifies the language data file used by Tesseract. This ensures the OCR engine recognizes the correct alphabet and language rules (e.g., English). By default, the PDF Extractor supports the following options:
•deu
•eng
•fra
•jpn
•spa
Most languages that use the Latin script can be processed successfully with the eng option. In case the recognition of your language is not accurate, you may need to download an additional language data file:
1.Download the relevant language data file (e.g., grc.traineddata) from the following page:
https://github.com/tesseract-ocr/tessdata_fast
2.Copy the language data file into the following folder:
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
3.Set the language parameter in the Properties Pane to the new language (e.g., grc)
Engine mode
Defines which recognition engine Tesseract uses:
•Default: Lets Tesseract choose automatically.
•LSTM only (default): Uses the newer neural network–based engine. The PDF Extractor is installed with the LSTM-only package and supports five languages (see details above).
•Tesseract only: Uses the older legacy engine.
•LSTM and Tesseract combined: Runs both engines together for potentially more robust results.
If you want to use the Tesseract option, take the steps below:
1.Make a copy of the existing Tesseract files in case you need to restore them at a later stage. The files are located in the following folder:
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
2.Download the relevant training data for the Tesseract option:
https://github.com/tesseract-ocr/tessdata
3.Replace the old Tesseract files with the new ones.
Alternatively, put the downloaded files into a new folder and edit the default path of TesseractData in the following registry key in Registry Editor:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Altova\MapForce PDF Extractor\Settings
Page segmentation
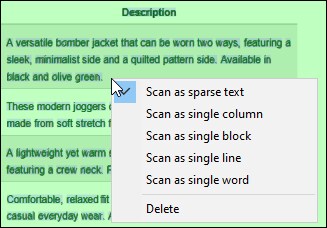
Determines how Tesseract interprets the layout of the text in the ScanArea. The available options are listed below.
•Default: Lets Tesseract decide automatically.
•Auto: Automatic page segmentation; no orientation or script (writing system such as Latin, Arabic, etc.) detection.
•Auto with OSD: Automatic segmentation with orientation and script detection.
•Single block: Treats the area as a single block (like a paragraph).
•Single block of vertical text: Treats the area as one vertical text block (rarely used outside special cases like certain tables).
•Single column: Assumes one column of text of variable sizes.
•Single line: Assumes the area is a single line of text.
•Single word: Assumes the area is one word.
•Sparse text (default): Detects text in arbitrary positions with no particular order; useful for full-page OCR.
•Sparse text with OSD: Same as above, but also detects orientation and script.
Choosing the right segmentation mode can improve recognition accuracy. For example, if an area contains only one line, using Single line often produces better results than Sparse text. For general documents, Sparse text is the best option.
The page segmentation modes are also available via the context menu that opens when you click a blank spot of the PDF document's scan area (screenshot below).
Parameters
Options you can pass directly to Tesseract. They allow you to fine-tune OCR behavior: For example, you can restrict recognition to certain characters (e.g., tessedit_char_whitelist=0123456789 for digits only). You can add multiple parameters, each as a key-value pair.
Tesseract supports many parameters, but not all of them may be useful for everyday PDF extraction. Some of the useful parameters include:
•tessedit_zero_rejection – Disables rejection of uncertain characters.
•tessedit_no_rejects – Prevents words from being rejected, even with low confidence.
•tessedit_char_blacklist – Excludes specific characters from recognition.
•tessedit_char_whitelist – Restricts recognition to a given set of characters.
•tessedit_char_unblacklist – Re-enables previously blacklisted characters.
•chs_leading_punct – Defines punctuation characters allowed at the start of a word.
•chs_trailing_punct1 – Defines punctuation characters allowed at the end of a word.
•chs_trailing_punct2 – Defines punctuation characters that may appear after chs_trailing_punct1.
•numeric_punctuation – Specifies punctuation symbols treated as part of numbers.
After you have modified a setting in the Properties Pane, click Apply to apply the changes.
Useful links
For more information about various Tesseract options, see the Tesseract Class Reference and All Tesseract OCR Options. For general information about Tesseract, please refer to the Tesseract User Manual.
New ScanArea
You can add a new ScanArea as follows:
1.Drag a rectangle over an area of interest.
2.Right-click the selection and choose the page segmentation mode (described above).
3.Configure the properties of the new ScanArea as needed.
OCR Workflow
For a general description of OCR procedures in the PDF Extractor, see OCR Workflow. For a step-by-step example, see Tutorial.