Create New Template and Load PDF File
This topic explains how to create a PDF extraction template, open an existing template, and load a PDF file. The topic also gives an overview of the PDF document from which data will be extracted.
Create a new template
You can create a new PDF extraction template in two ways: (i) directly in the PDF Extractor or (ii) via MapForce. For details, see the subsections below.
Create a template in the PDF Extractor
When you launch the PDF Extractor from the MapForce installation folder, a new template is created automatically. If you want to create another template, click the ![]() toolbar command or go to the File menu and click New. This opens a new template window.
toolbar command or go to the File menu and click New. This opens a new template window.
Create a template via MapForce
When you work in MapForce and want to create a PDF template via the MapForce interface, follow the steps below:
1.Click the ![]() toolbar command or select the menu command Insert | PDF Document in MapForce.
toolbar command or select the menu command Insert | PDF Document in MapForce.
2.In the dialog that pops up, select the Create new PDF extraction template file command (screenshot below).

3.Then you will be prompted to supply a sample PDF file. You can choose to browse for a PDF file right away (the Browse button) or add a PDF file at a later stage (Skip).
4.Next, you need to give your new template a name and select a location where the new template will be saved. Then click Save.
5.In the next step, a new PDF component is created in the mapping area, and the PDF Extractor opens in a separate window. You can now start defining PDF extraction rules for your new template. If you clicked Skip in Step 4, see the instructions on how to insert a PDF file in the Load a PDF Document subsection below. As soon as you have finished creating your template, click Save in the PDF Extractor. After this, MapForce will detect the changes to the template and suggest reloading the PDF component in the mapping area. After reloading the PDF component, you will see the new structure that corresponds to the structure of the template defined in the PDF Extractor.
Open an existing template
To open an already existing template, you can use any of the following methods:
•You can drag a template into the PDF Extractor.
•You can click the ![]() toolbar command and select a template in the Open dialog.
toolbar command and select a template in the Open dialog.
•You can click the Open command in the File menu and then select a template in the Open dialog.
Load a PDF document
You can import a PDF document into the PDF Extractor in any of the following ways:
•You can drag your PDF document into the PDF View pane.
•You can click the Open button in the PDF View pane and select a PDF file.
•You can click the ![]() button in the Properties Pane and select a PDF file.
button in the Properties Pane and select a PDF file.
PDF document
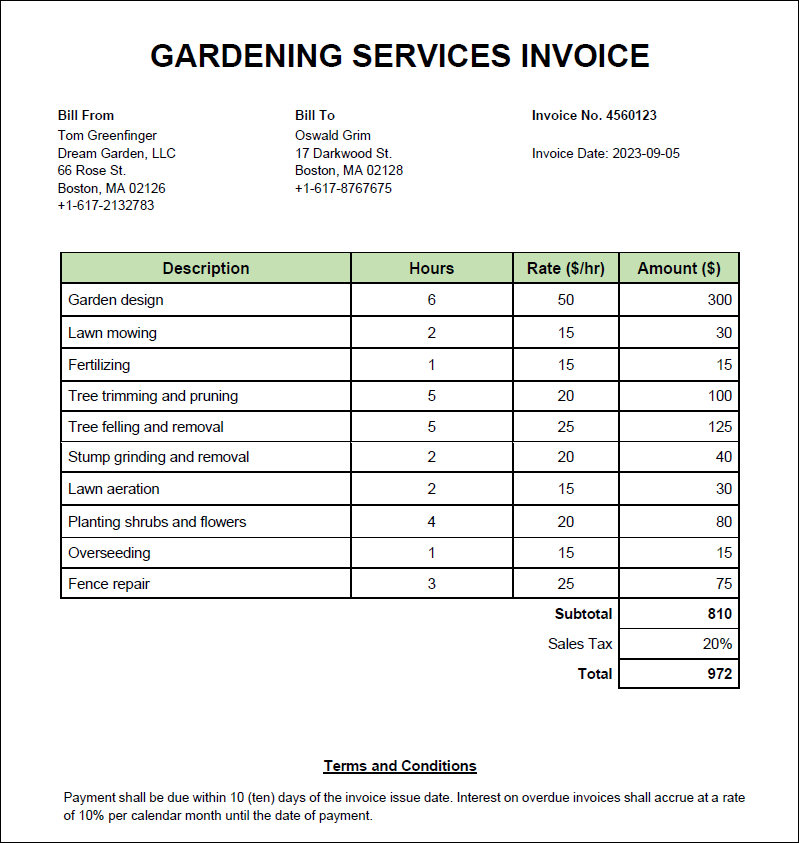
The PDF document (screenshot below) from which we want to extract data is a simple invoice that contains a header, information about the company, client, and invoice, a table with the description of gardening services provided, and terms. The invoice is an electronically created document that contains only one page.
Information in the Properties Pane
When your PDF document is loaded, the Properties Pane will display information about the file location (screenshot below). The Properties Pane also has the Output XML name property that is automatically set to Document. This value refers to the default name of the root. The name of the root is also visible in the model tree of the Schema pane and in the Output pane. To change the root name, type a new name in the text box next to the Output XML name property. In our example, the root is called Invoice.
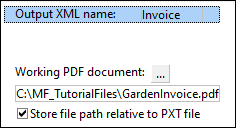
By default, the Store file path relative to PXT file check box is selected. This means that the path of a PDF document will be saved relative to the location of the template file (.pxt).
In the next step, our goal is to define the structure of the template and extract PDF data.