Merge Source and Target
The Merge Source and Merge Target objects belong together. The Merge Source object enables you to cut out a snippet of the current page. You can create multiple Merge Sources and then join them together into a single Merge Target that treats all the collected snippets from different pages as a single group of pages. The Merge Target processes the snippets in the order they were added.
The combination of Merge Sources and Merge Targets is beneficial when data is well organized and delimited on a page. However, in situations in which, for example, one row begins on one page and continues on the next page, it is recommended to use a Collage.
For information about how to add objects to the model tree, see Insert an Object.
Properties in the Properties Pane
The Merge Source object has two properties in the Properties Pane: Region and Merge Target. The Region property refers to the location of a Merge Source on the page. For details, see the Region property in the Split object. The Merge Target property refers to the name of the Merge Target object that will collect the relevant Merge Sources into one group.
Note that the values of the Merge Target parameter of all the Merge Sources you want to join into one Merge Target and the name of their corresponding Merge Target (the Name property) must be the same. Otherwise, the Merge Target will not be able to join these Merge Sources.
Example
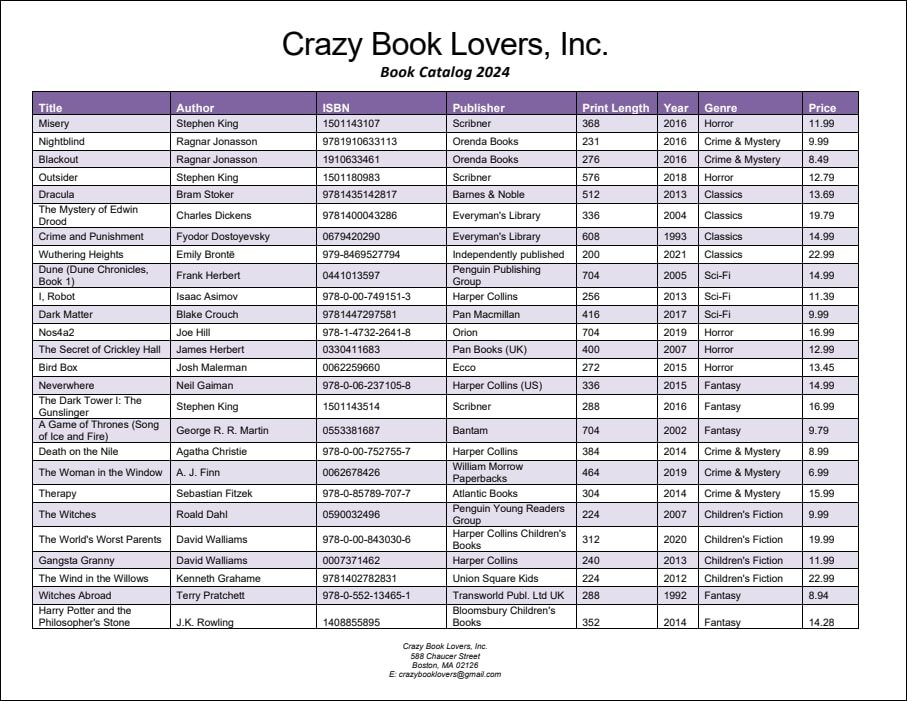
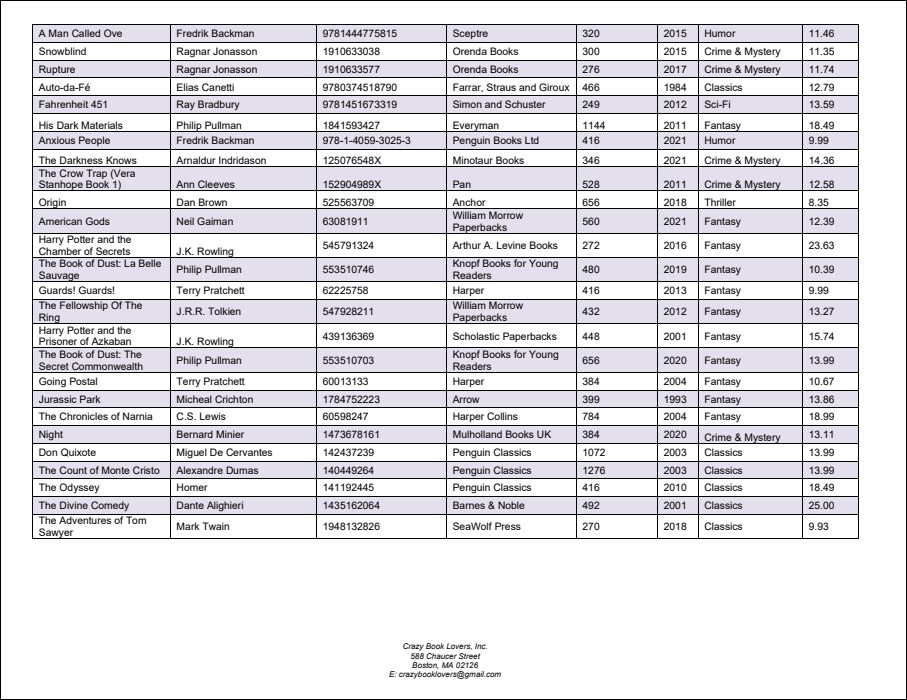
This example shows how to use the Merge Source and Merge Target objects. The PDF document from which we want to extract data is called BookCatalog.pdf. The document has two pages (screenshots below) that have slightly different layouts: Page 1 contains a header, a table, and a footer; the table continues on Page 2, and there is also a footer on Page 2. The extraction template discussed in this example is available in the following folder: MapForceExamples\BookCatalog.pxt.
Goals
The goals of this example are as follows:
•To extract the company name
•To extract all the data from the table from both pages
•To exclude the footer and the header row of the table from processing
Implementation
To achieve the goals listed above, we have created the following model tree:
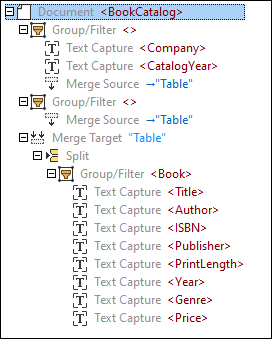
Under the root element called BookCatalog, there is a Group/Filter object that processes objects only on the first page (Select Groups set to 1) of the PDF document. The Group/Filter object includes two Text Captures as child nodes: Company, which refers to the name of the company at the top of the PDF document, and CatalogYear (screenshots below).


This Group/Filter object also contains a Merge Source as a child node that has a region comprising all the rows on the first page, except for the header row. We have defined the region manually (as opposed to using automatic table suggestions). An extract of the region of the first Merge Source is illustrated below.

The second Group/Filter object processes the second page (Select Groups set to 2) of the PDF document and also includes a Merge Source. The reason for creating two separate groups is that the layouts of the pages are not the same. Therefore, we cannot apply the same processing logic to these pages.
The Merge Target object collects the snippets from both Merge Sources into one group. For the Merge Target to correctly collect the relevant Merge Sources, the corresponding Merge Target and Sources must have the same names (in our example, Table). After all the snippets have been collected, they are grouped into rows (the Group/Filter object with Text Captures). Each row contains information about a book, its author, ISBN, publisher, print length, year, genre, and price. The Group/Filter object is wrapped into the Split object and displays the result of splitting the Merge Target into rows of data.
Output
The definition of extraction rules is complete. The Output pane displays the structure we have defined and the data we have chosen to extract from the PDF document. An extract of the output is displayed in the code listing below.
<BookCatalog>
<Company>Crazy Book Lovers, Inc.</Company>
<CatalogYear>2024</CatalogYear>
<Book>
<Title>Dune (Dune Chronicles, Book 1)</Title>
<Author>Frank Herbert</Author>
<ISBN>0441013597</ISBN>
<Publisher>Penguin Publishing Group</Publisher>
<PrintLength>704</PrintLength>
<Year>2005</Year>
<Genre>Sci-Fi</Genre>
<Price>14.99</Price>
</Book>
<Book>
<Title>Dark Matter</Title>
<Author>Blake Crouch</Author>
<ISBN>9781447297581</ISBN>
<Publisher>Pan Macmillan</Publisher>
<PrintLength>416</PrintLength>
<Year>2017</Year>
<Genre>Sci-Fi</Genre>
<Price>9.99</Price>
</Book>
<Book>
<Title>Nos4a2</Title>
<Author>Joe Hill</Author>
<ISBN>978-1-4732-2641-8</ISBN>
<Publisher>Orion</Publisher>
<PrintLength>704</PrintLength>
<Year>2019</Year>
<Genre>Horror</Genre>
<Price>16.99</Price>
</Book>
<...>
</BookCatalog>