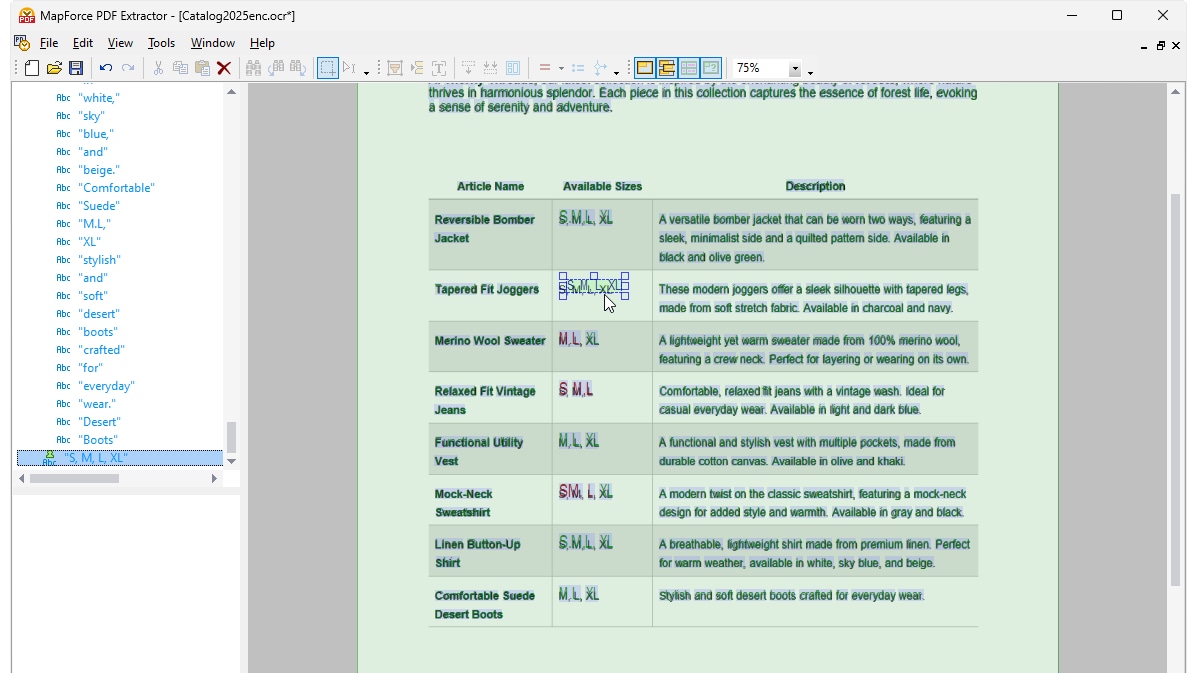
虽然 PDF 格式在当今商业领域应用广泛,但其中包含的数据通常难以直接用于与其他系统进行数据对接。PDF 文件通常设计用于呈现易于人类阅读的内容,并具有可变格式和布局,这使得结构化数据提取变得非常困难。它们可能包含文本、图像、表格和其他元素,但数据并非以机器可读的格式组织。常见的 PDF 数据提取工具可能无法提供准确的结果,尤其是在处理具有复杂布局的 PDF 文件时。而 MapForce PDF 提取器正是为了解决这个问题而设计的。
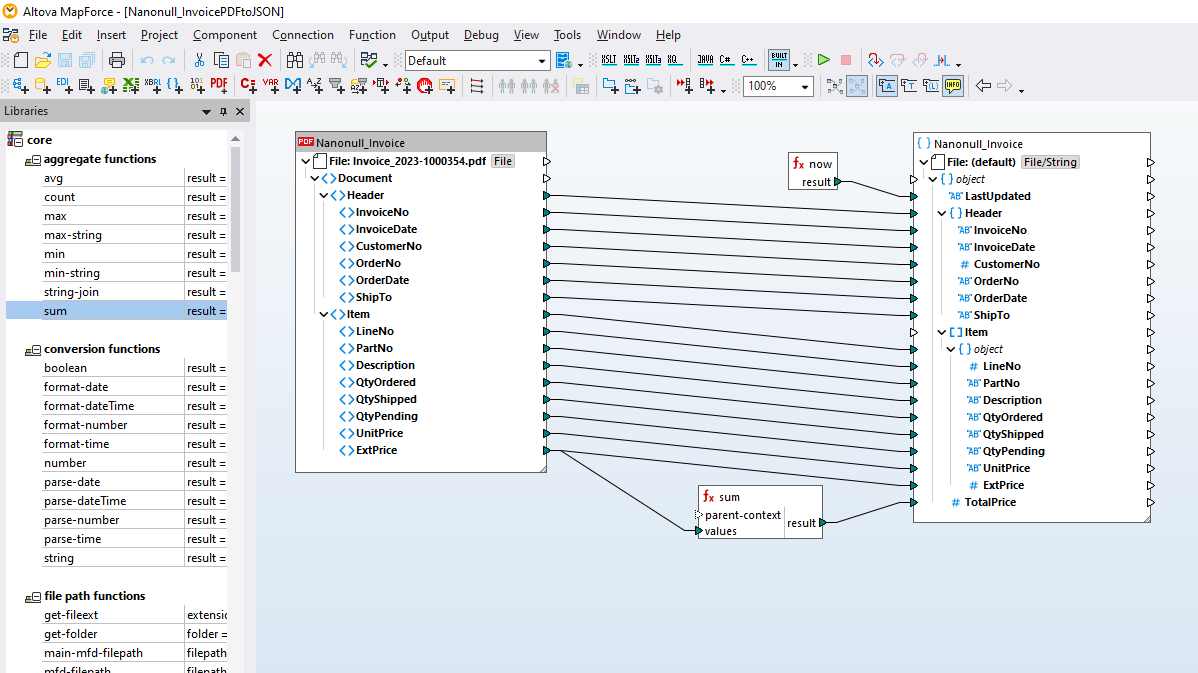
MapForce PDF 提取工具 是一款易于使用的实用工具,它允许您快速定义 PDF 文档的结构,并从中提取数据。 然后,您可以在 MapForce 中访问这些 PDF 数据,以便进行进一步的转换和转换为其他格式,例如 XML、JSON、数据库、Excel 等。 它是实现 PDF 数据集成和 ETL 项目的理想工具。
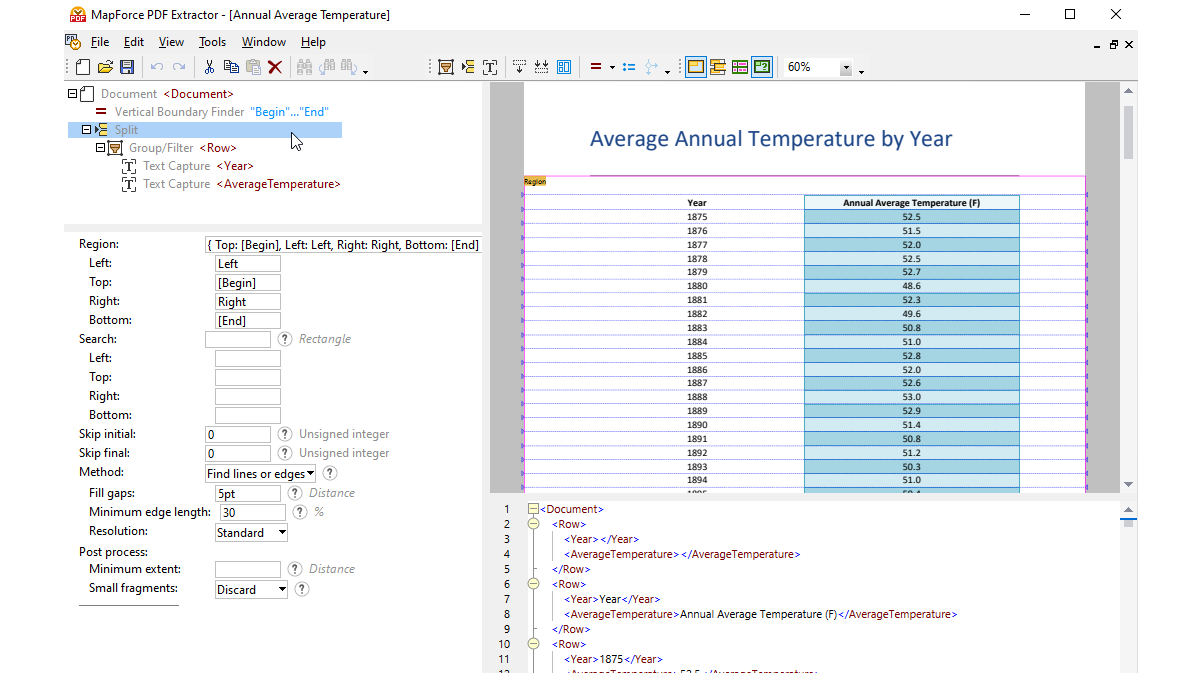
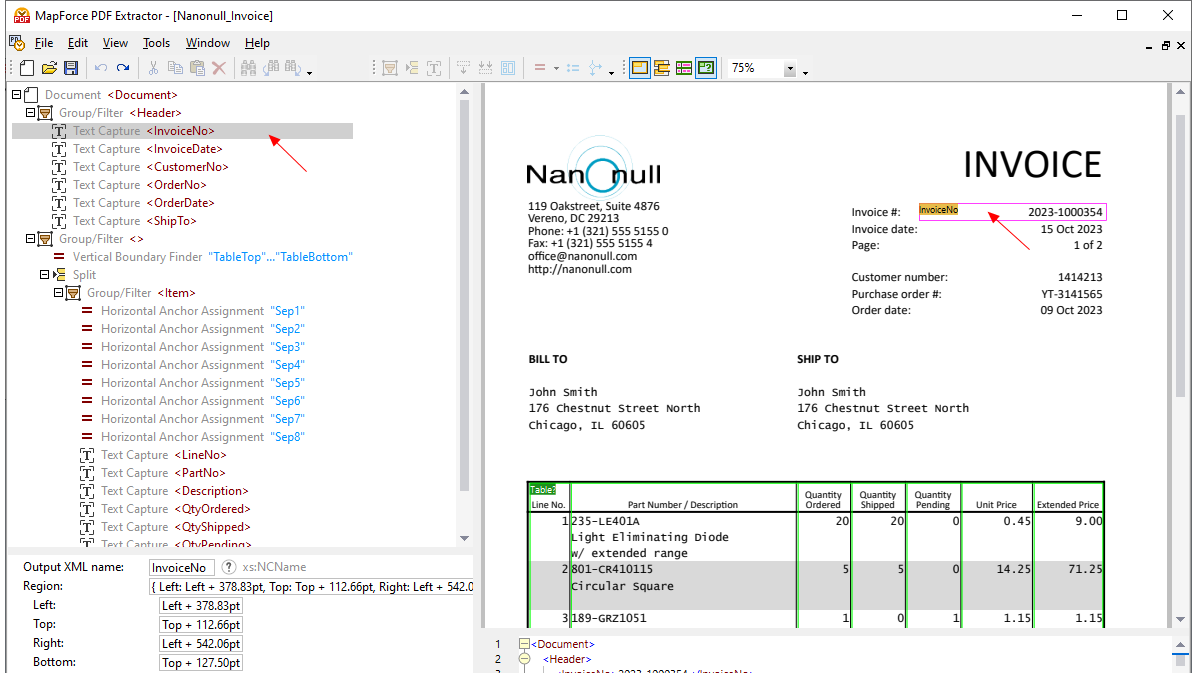
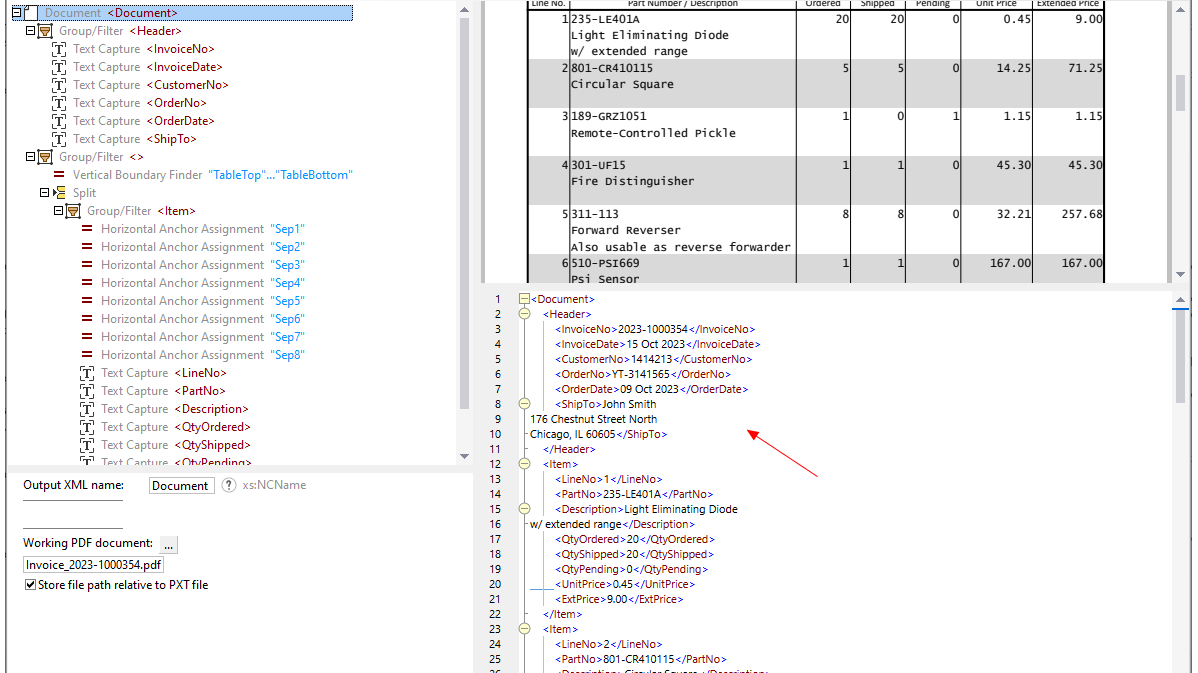
通过在 MapForce PDF 提取工具中使用可视化工具,您可以定义 PDF 文档的结构,并高效地提取其数据。PDF 提取工具是一个高度灵活的工具,它允许您仅提取文档的某些部分,而不是整个文档;您可以将来自同一 PDF 文件不同页面的信息片段进行组合;可以将表格拆分为行;还可以将数据组织成组。
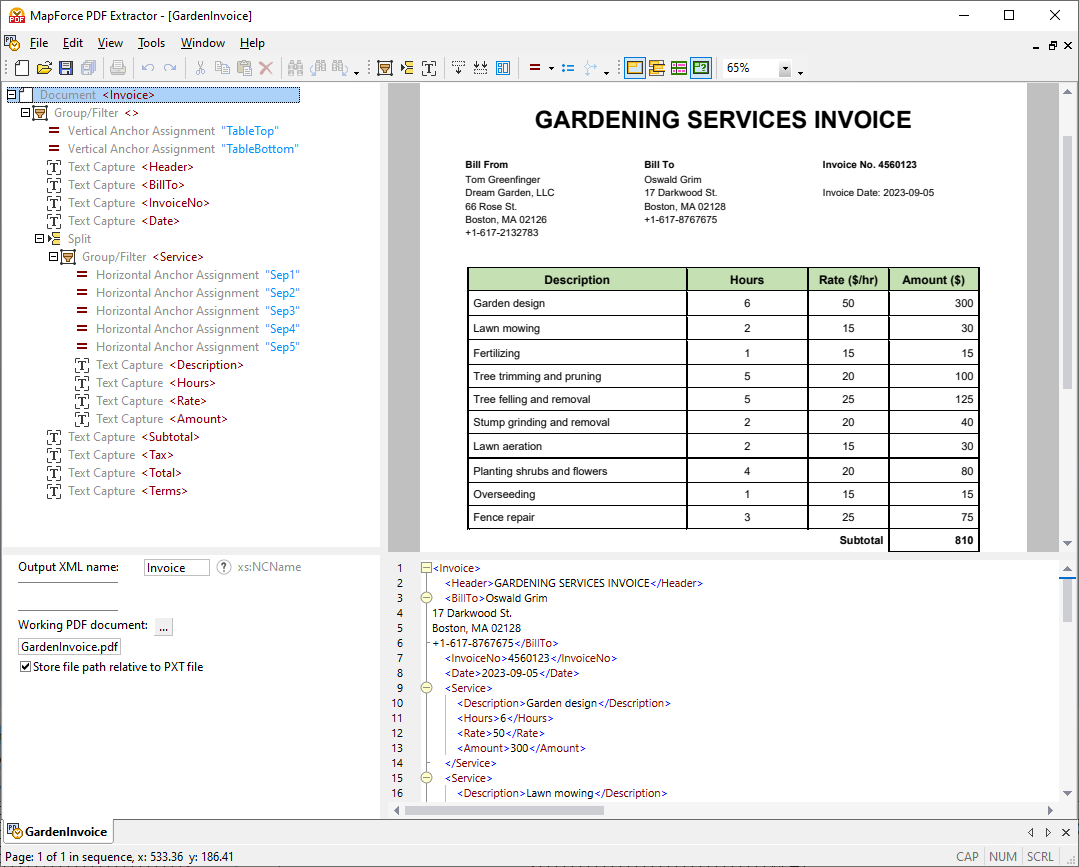
MapForce PDF提取器的设计直观且简单易用,用户可以通过点击和拖拽等操作,以可视化的方式轻松定义PDF文档的结构。 最终,之前被困在PDF文件中的大量数据现在可以被转换为其他格式,从而实现数据整合和利用。