Lire et écrire des Documents XML (C#)
Après avoir généré du code depuis le schéma de bibliothèque (voir Schéma d’exemple), une application C# test est créée, avec plusieurs bibliothèques Altova.
À propos des bibliothèques C# générées
La classe centrale du code généré est la classe Doc2qui représente le document XML. Une telle classe est générée pour tous les schémas et son nom dépend du nom de fichier de schéma. Veuillez noter que cette classe est appelée Doc2 pour éviter un conflit possible avec le nom d’espace de noms. Comme indiqué dans le diagramme, cette classe fournit des méthodes pour charger les documents depuis des fichiers, des streams binaires ou des strings (ou pour enregistrer des documents dans des fichiers, des streams, des strings). Pour consulter une description de cette classe, voir la référence de classe ( [YourSchema].[Doc] ).
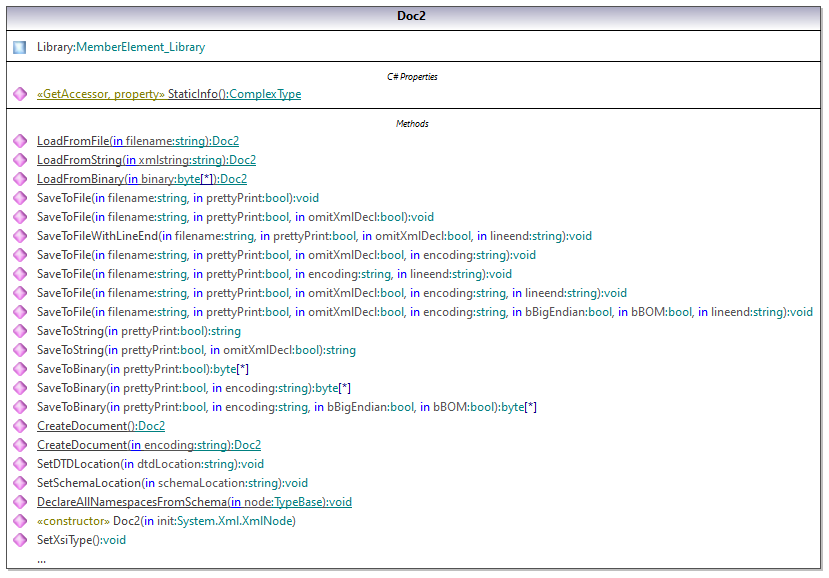
Le membre Library de la classe Doc2 représente la véritable racine du document.
Conformément aux règles de génération de code mentionnées dans À propos des Schema Wrapper Libraries (C#), les membres de classes sont générés pour chaque attribut et pour chaque élément d’un type. Dans le code généré, le nom de ce type de classes de membre est préfixé avec MemberAttribute_ et MemberElement_, respectivement. Des exemples de telles classes sont MemberAttribute_ID et MemberElement_Author, générés depuis l’élément Author et l’attribut ID d’un livre, respectivement (dans le diagramme ci-dessous, ils s’agit de classes imbriquées sous BookType). Ces classes vous permettent de manipuler à l’aide d’un programme les éléments et les attributs correspondants dans l’instance du document XML (par exemple, apposer, supprimer, définir une valeur, etc). Pour plus d'informations, voir la référence de classe [YourSchemaType].MemberAttribute et [YourSchemaType].MemberElement .
Puisque le DictionaryType est un type complexe dérivé depuis BookType dans le schéma, cette relation se retrouve aussi dans les classes générées. Comme illustré dans le diagramme, la classe DictionaryType hérite la classe BookType.

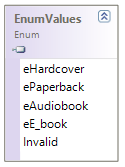
Si votre schéma XML définit des types simples en tant qu’énumérations, les valeurs énumérées deviennent disponibles en tant que valeurs Enum dans le code généré. Dans le schéma utilisé dans ces exemple, un format de livre peut être hardcover, paperback, e-book, etc. Dans le code généré, ces valeurs peuvent donc être disponibles via un Enum membre de la classe BookFormatType.
Écrire un document XML
1.Ouvrir la solution LibraryTest.sln dans Visual Studio généré depuis le schéma Library mentionné plus tôt dans cet exemple.
Tout en prototypant une application depuis un schéma XML changeant fréquemment, vous devrez éventuellement générer fréquemment du code dans le même répertoire, de manière à ce que les changements de schéma sont réfléchis immédiatement dans le code. Veuillez noter que l’application de test généré et les bibliothèques Altova sont écrasées à chaque fois que vous générez du code dans le même répertoire cible. C’est pourquoi il ne faut pas ajouter du code à l’application de test généré. Au lieu de cela, veuillez intégrer les bibliothèques dans votre projet (voir Intégrer des Bibliothèques Schema Wrapper). |
2.Dans Solution Explorer, ouvrir le fichier LibraryTest.cs, et éditer la méthode Example() comme indiqué ci-dessous.
protected static void Example() |
3.Appuyer sur F5 pour lancer le débogage. Si le code a été exécuté avec succès, un fichier GeneratedLibrary.xml est créé dans le répertoire de sortie de solution (généralement, bin/Debug).
Lire un document XML
1.Ouvrir la solution LibraryTest.sln dans Visual Studio.
2.Enregistrer le code-ci-dessous en tant que Library.xml dans le répertoire de sortie du projet (par défaut, bin/Debug). C’est le fichier qui sera lu par le code du programme.
<?xml version="1.0" encoding="utf-8"?> |
3.Dans Solution Explorer, ouvrir le fichier LibraryTest.cs, et éditer la méthode Example() comme indiqué ci-dessous.
protected static void Example() |
4.Appuyer sur F5 pour lancer le débogage. Si le code a été exécuté avec succès, Library.xml sera lu par le code de programme, et ses contenus seront affichés en tant que sortie de console.
Lire et écrire des éléments et des attributs
Les valeurs des éléments et des attributs peut être accédé en utilisant la propriété Value de la classe d’élément ou d'attribut du membre généré, par exemple :
// Output values of ID attribute and (first and only) title element |
Pour obtenir la valeur de l’élément Title dans cet exemple particulier, nous avons aussi utilisé la méthode First(), étant donné que c’est le premier (et seul) élément Title d’un livre. Dans les cas où vous devez choisir un élément spécifique depuis une liste par index, utiliser la méthode At().
La classe générée pour chaque élément de membre d’un type met en place l’interface standard System.Collections.IEnumerable. Cela permet de boucler dans plusieurs éléments du même type. Dans cet exemple particulier, vous pouvez boucler à travers tous les livres d’un objet Bibliothèque comme suit :
// Iteration: for each <Book>... |
Pour ajouter un nouvel élément, utiliser la méthode Append(). Par exemple, le code suivant appose l’élément racine au document :
// Append the root element to the library |
Vous pouvez définir la valeur d’un attribut (comme ID dans cet exemple) comme suit :
// Set the value of the ID attribute |
Lire et écrire des valeurs d’énumération
Si votre schéma XML définit des types simples en tant qu’énumérations, les valeurs énumérées deviennent disponibles en tant que valeurs Enum dans le code généré. Dans le schéma utilisé dans ces exemple, un format de livre peut être hardcover, paperback, e-book, etc. Dans le code généré, ces valeurs peuvent donc être disponibles via un Enum.
Pour attribuer des valeurs d’énumération à un objet, utiliser du code comme celui ci-dessous :
// Set the format of the book (enumeration) |
Vous pouvez lire ces valeurs d’énumération provenent de documents d’instance XML comme suit :
// Read and compare an enumeration value |
Si une condition "if" n’est pas suffisante, créer un interrupteur pour déterminer chaque valeur d’énumération et traiter comme requis.
Travailler avec des types xs:dateTime et xs:duration
Si le schéma à partir duquel vous avez généré du code utilise les types heure et durée comme xs:dateTime, ou xs:duration, ils sont convertis en classes natives Altova dans un code généré. C’est pourquoi, pour écrire une valeur date ou durée vers le document XML, procéder comme suit :
1.Construit un objet Altova.Types.DateTime ou Altova.Types.Duration (soit depuis System.DateTime, ou en utilisant des parties comme des heures et des minutes, voir Altova.Types.DateTime et Altova.Types.Duration pour plus d'informations).
2.Définir l’objet en tant que la valeur de l’élément ou de l’attribut requis, par exemple :
// Create the library generation date using Altova DateTime class |
Pour lire une date ou une durée depuis un document XML, procéder comme suit :
1.Déclarer la valeur d’élément (ou d’attribut) comme objet Altova.Types.DateTime ou Altova.Types.Duration .
2.Formate l’élément ou l’attribut requis, par exemple :
// Read the library generation date |
Pour plus d'informations, voir la référence de classe Altova.Types.DateTime et Altova.Types.Duration .
Travailler avec des types dérivés
Si votre schéma XML définit des types dérivés, vous pouvez préserver la dérivation de type dans des documents XML que vous créez ou chargez par le biais d’un programme. Prendre le schéma utilisé dans cet exemple, l’extrait de code suivant illustre comment créer un nouveau livre de type dérivéDictionaryType:
// Append a dictionary (book of derived type) and populate its attributes and elements |
Veuillez noter qu’il est important de définir l’attribut xsi:type du livre récemment créé. Cela garantit que le type de livre sera interprété correctement par le schéma losrque le document XML est validé.
Lorsque vous chargez des données depuis un document XML, l’extrait de code suivant montre comment identifier un livre de type dérivé DictionaryType dans l’instance XML chargée. Premièrement, le code trouve la valeur de l’attribut xsi:type du nœud de livre. Si l’espace de noms URI de ce nœud est http://www.nanonull.com/LibrarySample et si le préfixe et type de lookup URI correspond à la valeur de l’attribut xsi:type, alors il s’agit d’un dictionnaire :
// Determine if this book is of derived type |