Débogage XSLT : Identification et correction des erreurs de transformation
Pour toute personne travaillant avec XML, XSLT est un outil puissant et indispensable, mais il est également notoirement difficile à déboguer. Vous transformez un grand fichier XML et obtenez un résultat inattendu ? Vous pourriez passer des heures à essayer de déterminer si le problème se situe dans la logique de votre modèle, dans vos expressions XPath ou dans vos données sources. Sans les bons outils de débogage, le développement XSLT devient une source de frustration. Examinons comment une approche appropriée du débogage peut vous faire gagner énormément de temps.

Voici la troisième partie de notre série sur l'édition de fichiers XML. N'oubliez pas de consulter :
Ce que fait XSLT (et pourquoi c'est important)
XSLT (eXtensible Stylesheet Language Transformations) est la méthode standard pour convertir des fichiers XML d'un format à un autre. Vous pouvez convertir des fichiers XML en HTML pour l'affichage sur le web, en CSV pour les tableurs, ou vers un schéma XML complètement différent. XSLT est omniprésent dans les systèmes d'entreprise, la gestion de contenu, le traitement des données financières et les applications web.
Une feuille de style XSLT est un ensemble de règles de modèle qui correspondent à des motifs dans votre document XML source. Chaque modèle définit ce qui doit être généré lorsque le processeur XSLT rencontre un élément ou une structure particulière. Le processeur parcourt le document source, compare les nœuds aux modèles et assemble le résultat. Les modèles peuvent appeler d'autres modèles, appliquer une logique conditionnelle, parcourir des ensembles de nœuds et extraire des données provenant de plusieurs emplacements dans le document source. L'ordre d'exécution dépend des données, et non de l'ordre dans lequel les modèles apparaissent dans le fichier.
La puissance de XSLT est également sa complexité. Une transformation est essentiellement un programme : elle comporte une logique, un flux de contrôle, des variables et des modèles. Lorsqu'un programme ne produit pas le résultat attendu, la recherche de l'erreur nécessite de comprendre ce que la transformation effectue réellement à chaque étape.
Pourquoi le débogage de XSLT sans outils est une tâche difficile
Imaginez que vous transformez un document XML à l'aide d'une feuille de style XSLT qui utilise 50 modèles. Le résultat est incorrect, mais vous ne savez pas où se situe le problème. Sans outils de débogage appropriés, vos options sont très limitées :
Ajoutez des instructions de journalisation (xsl:message) dans toute votre feuille de style, exécutez la transformation, parcourez des dizaines de lignes de journalisation, ajustez vos instructions de journalisation, et relancez le processus. Répétez ces étapes jusqu'à ce que vous trouviez le problème. Cela peut prendre des heures.
Passez en revue votre code source XSLT, en essayant de l'exécuter mentalement et en identifiant les endroits où il pourrait rencontrer des problèmes. Pour les feuilles de style complexes, cela est pratiquement impossible.
Simplifiez vos données d'entrée pour isoler le problème. Cependant, cela pourrait masquer des erreurs qui ne se manifestent qu'avec des données réelles.
Modifiez des sections de la feuille de style, en testant chaque modification. Cette méthode est inefficace et risque d'introduire de nouveaux bogues.
Aucune de ces approches n'est satisfaisante. Elles demandent toutes un temps et une énergie considérables.
Le débogage pas à pas transforme votre flux de travail
Un débogueur XSLT spécialisé, comme celui intégré à Altova XMLSpy, modifie fondamentalement la manière dont vous abordez les problèmes de transformation. Au lieu de procéder par essais et erreurs, vous voyez exactement ce qui se passe. Voici comment :
Points d'arrêt et contrôle de l'exécution
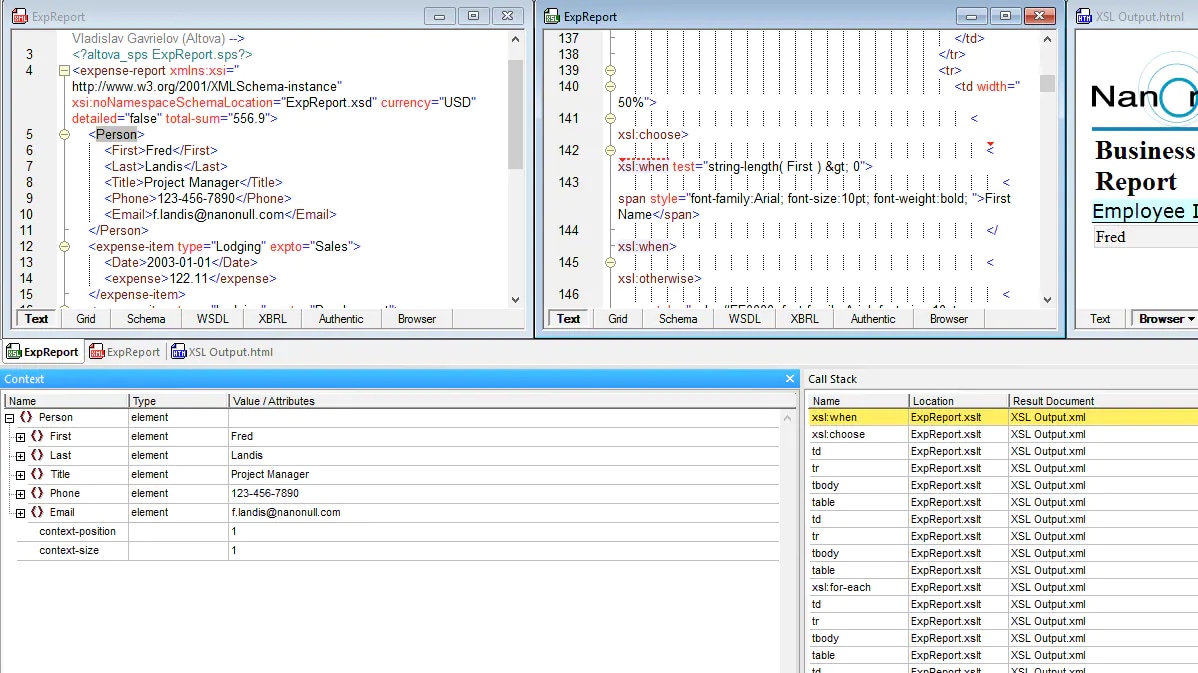
Définissez des points d'arrêt sur des modèles spécifiques ou des lignes de code, puis lancez votre transformation. L'exécution s'interrompt lorsqu'elle atteint un point d'arrêt, ce qui vous permet d'examiner l'état actuel. Vous pouvez parcourir le code ligne par ligne, entrer dans les modèles appelés, ou les ignorer pour passer à l'appel du modèle suivant. Ce niveau de contrôle est similaire à celui que vous utilisez en programmation classique, et il est tout aussi puissant pour XSLT.
Inspection des variables et du contexte
Pendant l'exécution de votre transformation, vous pouvez examiner les variables, les paramètres et le contexte du nœud actuel. Quelle est la valeur réelle de cette variable à ce moment précis ? Quel nœud est actuellement en cours de traitement ? Est-ce que.. XPath L'expression renvoie-t-elle le résultat attendu ? Un débogueur vous affiche les résultats immédiatement, ce qui élimine les suppositions.
Pile d'appels et suivi des modèles
Lorsque qu'un modèle appelle un autre modèle, qui lui-même appelle un autre, il est essentiel de comprendre le chemin d'exécution. Un débogueur vous montre la pile d'appels complète : quel modèle a appelé quel autre, et dans quel ordre. Cela facilite la compréhension du déroulement et permet de repérer les erreurs logiques.
Suivi des résultats
Vous pouvez observer la génération des résultats en temps réel pendant l'exécution de la transformation. Si les résultats sont incorrects, vous pouvez retracer l'origine du problème jusqu'au modèle ou à l'instruction qui les a générés, ce qui vous permet de localiser la source de l'erreur.
Le débogage pas à pas est idéal lorsque vous avez une idée approximative de l'endroit où se situe le problème. Mais que faire lorsque vous partez dans l'autre sens : vous constatez une erreur dans le résultat et vous devez remonter en arrière pour en trouver la cause ? C'est là que la rétro-analyse devient utile.
Utilisez la technique de rétro-cartographie pour optimiser votre code XSLT
L'une des parties les plus difficiles du débogage XSLT consiste à répondre à une question simple : quelle instruction a généré ce résultat Lorsque votre transformation produit des résultats inattendus, vous vous retrouvez souvent à parcourir manuellement les modèles, en essayant de relier le résultat aux données sources et à la transformation XSLT qui l'a produit.
La fonctionnalité de "rétro-cartographie" d'XMLSpy résout ce problème directement. Activez-la à partir de la barre d'outils avant d'exécuter votre transformation, et le document de résultat devient interactif. Cliquez sur n'importe quel nœud dans la sortie, et XMLSpy mettra en évidence à la fois l'instruction XSLT qui l'a généré et les données XML sources dont elle provient. Si vous examinez la sortie HTML dans la vue navigateur, vous pouvez simplement passer la souris sur une section et voir automatiquement la source correspondante et l'expression XSLT mises en évidence.
Vous pouvez également afficher côte à côte les documents XML source, les feuilles de style XSLT et les documents résultants après la transformation, ce qui vous permet de visualiser les trois simultanément pendant que vous analysez le processus.
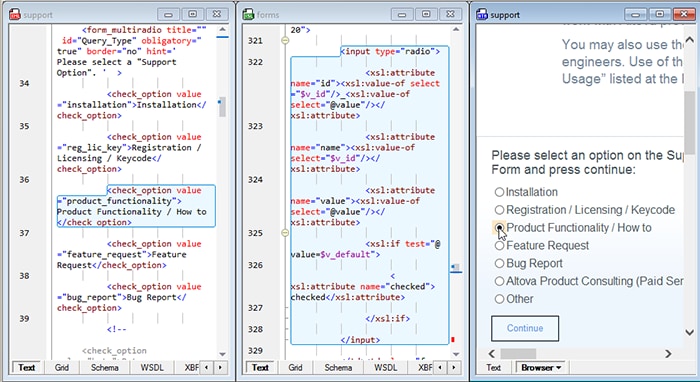
Ce qui est particulièrement remarquable, c'est la manière dont XMLSpy y parvient. La remontée d'informations fonctionne sans injecter de code ou de balises supplémentaires dans votre document de sortie. Les résultats de votre transformation restent propres, exactement comme ils le seraient sans l'activation de la remontée d'informations. C'est une distinction importante si vous déboguez une transformation dont la sortie est directement intégrée dans un processus de production.
Pour toute personne qui doit maintenir des feuilles de style XSLT qu'elle n'a pas écrites, ce qui est une situation très courante, la fonction de "rétro-traçage" transforme ce qui prenait autrefois des heures de recherche en quelques clics.
Prise en charge des différentes versions de XSLT
XSLT a évolué à travers plusieurs versions, chacune ajoutant de nouvelles fonctionnalités. XMLSpy prend en charge XSLT 1.0, 2.0 et 3.0, vous permettant ainsi de travailler avec la version requise par votre projet. La version moderne, XSLT 3.0, introduit le traitement en flux (pour les fichiers volumineux), de meilleures fonctions et une performance améliorée, mais le débogage fonctionne de manière transparente sur toutes les versions.
Profilage des performances
Au-delà de la correction des erreurs logiques, un éditeur XSLT professionnel intègre des fonctionnalités de profilage. Lorsque votre transformation est lente, le outil de profilage XSLT vous indique quels modèles prennent le plus de temps. Il se peut qu'un modèle soit appelé des milliers de fois inutilement. Il se peut également qu'une expression XPath soit inefficace. Le profileur quantifie le temps passé dans chaque partie de votre feuille de style, ce qui vous permet d'optimiser de manière systématique.
Pour les transformations importantes, cela peut réduire le temps d'exécution de quelques minutes à quelques secondes.
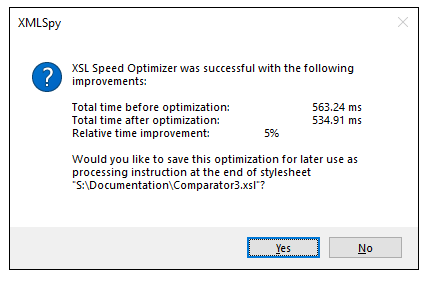
Une fonctionnalité unique à XMLSpy est la suivante : Optimisation de la vitesse XSL, qui constitue une approche brevetée permettant d'accélérer les transformations XSLT jusqu'à 20 % ou plus. Au lieu que le développeur doive analyser les résultats des outils de profilage et modifier son fichier, l'optimiseur de vitesse XSLT détecte et teste automatiquement les optimisations qu'il peut appliquer, sans nécessiter aucune modification du code.
Le débogage améliore considérablement votre productivité
Le débogage XSLT n'est pas un luxe réservé aux utilisateurs avancés ; c'est un outil essentiel pour tous ceux qui travaillent régulièrement avec des transformations. XMLSpy intègre un débogueur XSLT complet qui vous offre la même expérience de débogage que celle à laquelle vous êtes habitué en programmation classique.
De plus, les mêmes outils de débogage sont disponibles pour XPath et XQuery.
Prêt à arrêter de deviner et à commencer à déboguer ? Essayez le débogueur XSLT d'XMLSpy, avec.. Essai gratuit de 30 jours.