Depuración de XSLT: Identificación y corrección de errores de transformación
Para cualquier persona que trabaje con XML, XSLT es una herramienta poderosa e indispensable, pero también es notoriamente difícil de depurar. ¿Transforma un archivo XML grande y obtienes resultados inesperados? Podrías pasar horas tratando de averiguar si el problema está en la lógica de tu plantilla, en tus expresiones XPath o en los datos de origen. Sin las herramientas de depuración adecuadas, el desarrollo de XSLT se convierte en una fuente de frustración. Exploremos cómo el enfoque correcto para la depuración puede ahorrarte enormes cantidades de tiempo.

Esta es la tercera parte de nuestra serie sobre la edición de XML. No olvide consultar:
¿Qué hace XSLT (y por qué es importante)
XSLT (Lenguaje de Transformación de Hojas de Estilo Extensibles) es la forma estándar de convertir documentos XML de un formato a otro. Puede transformar XML a HTML para su visualización en la web, a CSV para hojas de cálculo, o a un esquema XML completamente diferente. XSLT se utiliza ampliamente en sistemas empresariales, gestión de contenidos, procesamiento de datos financieros y aplicaciones web.
Una hoja de estilo XSLT es un conjunto de reglas de plantilla que coinciden con patrones en su documento XML de origen. Cada plantilla define qué se debe generar como resultado cuando el procesador XSLT encuentra un elemento o estructura específica. El procesador recorre el documento de origen, compara los nodos con las plantillas y ensambla el resultado. Las plantillas pueden llamar a otras plantillas, aplicar lógica condicional, iterar sobre conjuntos de nodos y extraer datos de múltiples ubicaciones en el documento de origen. El orden de ejecución depende de los datos, no del orden en que las plantillas aparecen en el archivo.
La potencia de XSLT también es su complejidad. Una transformación es, en esencia, un programa: tiene lógica, flujo de control, variables y plantillas. Cuando ese programa no produce el resultado esperado, encontrar el error requiere comprender qué está haciendo realmente la transformación en cada paso.
¿Por qué la depuración de XSLT sin herramientas es tan difícil
Imagine que está transformando un documento XML con una hoja de estilo XSLT que utiliza 50 plantillas. Algo está mal con el resultado, pero no sabe dónde. Sus opciones, sin herramientas de depuración adecuadas, son muy limitadas:
Añada sentencias de registro (xsl:message) en toda su hoja de estilo, ejecute la transformación, revise decenas de líneas de registro, ajuste sus registros y ejecútelo de nuevo. Repita este proceso hasta que encuentre el error. Esto puede llevar horas.
Revise cuidadosamente el código fuente de su transformación XSLT, intentando ejecutarlo mentalmente y determinar dónde podría fallar. Para hojas de estilo complejas, esto es prácticamente imposible.
Simplifique sus datos de entrada para aislar el problema. Sin embargo, esto podría ocultar errores que solo aparecen con datos reales.
Reescriba secciones de la hoja de estilo, probando cada modificación. Esto es ineficiente e introduce nuevos errores.
Ninguno de estos enfoques es satisfactorio. Todos ellos consumen enormes cantidades de tiempo y energía.
La depuración paso a paso transforma su flujo de trabajo
Un depurador especializado en XSLT, como el que se encuentra en Altova XMLSpy, cambia fundamentalmente la forma en que aborda los problemas de transformación. En lugar de adivinar, puede ver exactamente lo que está sucediendo. Así es como funciona:
Puntos de interrupción y control de ejecución
Establezca puntos de interrupción en plantillas específicas o en líneas de código, y luego ejecute su transformación. La ejecución se detiene cuando alcanza un punto de interrupción, lo que le permite examinar el estado actual. Puede avanzar línea por línea, entrar en las plantillas llamadas, o saltarlas, avanzando a la siguiente llamada de plantilla. Este nivel de control es similar al que está acostumbrado en la programación convencional, y es igualmente potente para XSLT.
Inspección de variables y análisis del contexto
Mientras se ejecuta la transformación, puede examinar variables, parámetros y el contexto del nodo actual. ¿Qué valor tiene realmente esa variable en este momento? ¿Qué nodo se está procesando actualmente? ¿Está esa expresión XPath devolviendo el resultado esperado? Un depurador le muestra las respuestas de inmediato, eliminando las conjeturas.
Pila de llamadas y seguimiento de plantillas
Cuando una plantilla llama a otra, que a su vez llama a otra, es fundamental comprender el flujo de ejecución. Un depurador le muestra la pila de llamadas completa: qué plantilla llamó a qué otra, y en qué orden. Esto facilita la comprensión del proceso y la detección de errores lógicos.
Seguimiento de resultados
Puede ver cómo se genera la salida en tiempo real a medida que se ejecuta la transformación. Si la salida es incorrecta, puede rastrear hasta qué plantilla o instrucción la generó, lo que le permite identificar el error.
La depuración paso a paso es ideal cuando se tiene una idea aproximada de dónde se encuentra el problema. Pero, ¿qué ocurre cuando se parte de lo contrario: se observa un error en el resultado y es necesario retroceder para encontrar la causa? Ahí es donde la trazabilidad inversa resulta muy útil.
Utilice el mapeo inverso para perfeccionar su código XSLT
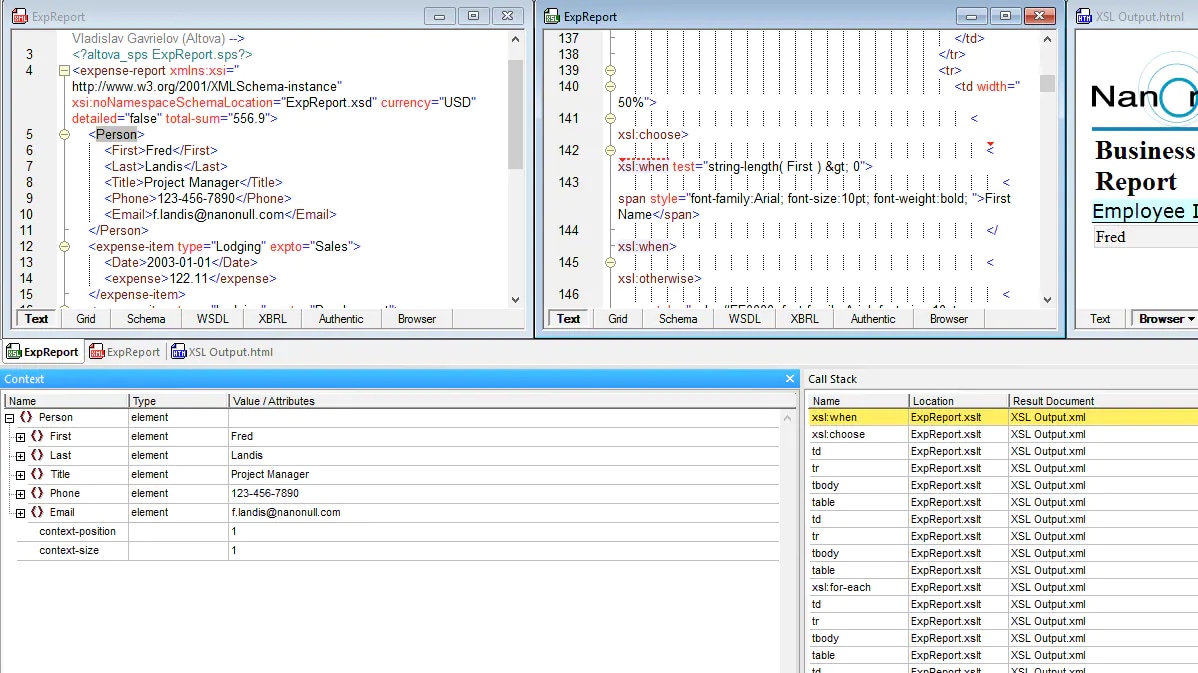
Una de las partes más difíciles de la depuración de XSLT es responder a una pregunta sencilla: ¿Qué instrucción generó esta salida? Cuando una transformación produce resultados inesperados, a menudo se encuentra uno teniendo que revisar manualmente las plantillas, intentando relacionar el resultado con los datos de origen y con el código XSLT que los procesó.
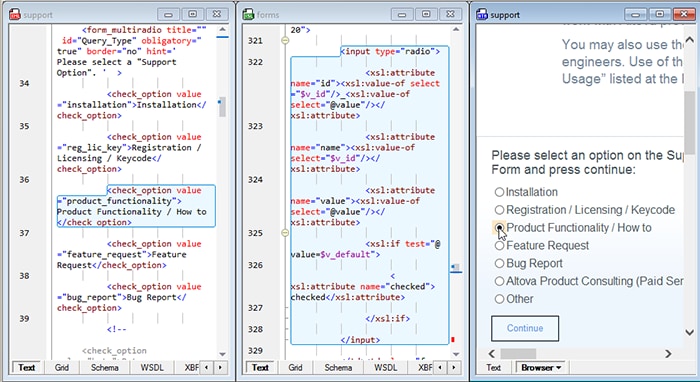
La función de "retro-mapeo" de XMLSpy resuelve este problema directamente. Actívela desde la barra de herramientas antes de ejecutar su transformación, y el documento resultante se vuelve interactivo. Haga clic en cualquier nodo en la salida, y XMLSpy resaltará tanto la instrucción XSLT que lo generó como los datos XML de origen de los que se extrajo. Si está revisando la salida HTML en la vista del navegador, simplemente puede pasar el cursor sobre una sección y verá automáticamente resaltados el código fuente correspondiente y la expresión XSLT.
También puede mostrar los documentos XML de origen, las hojas de estilo XSLT y los documentos de resultado uno al lado del otro después de la transformación, de modo que pueda ver los tres simultáneamente mientras sigue el proceso lógico.
Lo que hace que esto sea particularmente destacable es la forma en que XMLSpy lo logra. La función de "retro-mapeo" funciona sin inyectar ningún código o marcado adicional en su documento de salida. Los resultados de su transformación se mantienen limpios, tal como serían sin la función de retro-mapeo activada. Esto es una distinción importante si está depurando una transformación cuyo resultado se utiliza directamente en un proceso de producción.
Para cualquiera que tenga que mantener código XSLT que no escribió, lo cual es una situación muy común, la función de "retro-mapeo" convierte lo que antes implicaba horas de investigación en cuestión de clics.
Compatibilidad con las diferentes versiones de XSLT
XSLT ha evolucionado a través de múltiples versiones, cada una añadiendo nuevas funcionalidades. XMLSpy es compatible con XSLT 1.0, 2.0 y 3.0, por lo que puede trabajar con la versión que requiera su proyecto. La versión moderna, XSLT 3.0, introduce la transmisión de datos (para archivos grandes), funciones mejoradas y un rendimiento optimizado, pero la depuración funciona de manera fluida en todas las versiones.
Perfilado de rendimiento
Además de la depuración de errores lógicos, un editor XSLT profesional incluye funciones de análisis de rendimiento. Cuando su transformación es lenta, el analizador de rendimiento de XSLT le muestra qué plantillas están consumiendo más tiempo. Es posible que una plantilla se esté llamando miles de veces innecesariamente. Quizás una expresión XPath sea ineficiente. El analizador de rendimiento cuantifica el tiempo empleado en cada parte de su hoja de estilos, lo que le permite optimizar de forma sistemática.
Para transformaciones de gran envergadura, esto puede reducir el tiempo de ejecución de minutos a segundos.
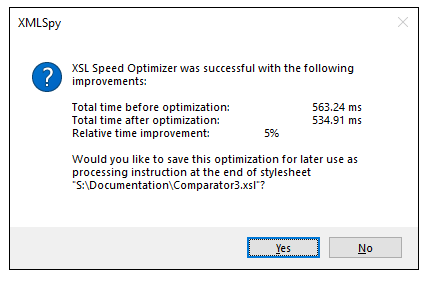
Una característica única de XMLSpy es el Optimizador de Velocidad XSL, que es un método patentado para acelerar las transformaciones XSLT hasta en un 20% o más. En lugar de que el desarrollador tenga que analizar los resultados del perfilador y actualizar su archivo, el Optimizador de Velocidad XSL detecta y prueba optimizaciones que se pueden aplicar automáticamente, sin necesidad de modificar nada.
La depuración aumenta su productividad
La depuración de XSLT no es un lujo reservado para usuarios avanzados; es esencial para cualquier persona que trabaje regularmente con transformaciones. XMLSpy integra un depurador de XSLT con todas las funciones necesarias, que le ofrece la misma experiencia de depuración a la que está acostumbrado en la programación convencional.
Y, las mismas herramientas de depuración están disponibles para XPath y XQuery.
¿Está listo para dejar de adivinar y empezar a depurar? Pruebe el depurador XSLT de XMLSpy con una prueba gratuita de 30 días.