Integratie van gegevens via webdiensten
In een vorige post hebben we geschreven dat elke taak op het gebied van data-integratie en rapportage moet beginnen met een helder begrip van de brongegevens. Met behulp van de gridweergave in XMLSpy, de toonaangevende XML- en JSON-editor, hebben we JSON-gegevens geanalyseerd die betrekking hadden op 5-daagse weersvoorspellingen, verkregen van een webservice.
We zetten de eerder beschreven scenario voort en gebruiken MapForce, het bekroonde, grafische data-mapping-tool voor elke mogelijke conversie en integratie, om de voorspellingen voor een reeks belangrijke havens voor goederentransport om te zetten in overzichtelijke Excel-documenten. We willen daarbij eventuele voorspelde harde wind of hevige regenval benadrukken, die vertragingen kunnen veroorzaken door het gebruik van kranen voor het laden en lossen van containers te belemmeren, of door de snelheid van schepen die de havens binnenkomen en verlaten te verminderen.

De REST-aanvraag voor weersvoorspellingen accepteert breedte- en lengtegraden om een voorspelling voor de komende 5 dagen voor elke locatie ter wereld te genereren. Met één enkele MapForce-mapping kunnen meerdere invoer- en uitvoergegevens worden verwerkt. Daarom beginnen we met dit web service data-integratieproject door een lijst te maken van havenlocaties en hun coördinaten.
Het is snel om de lijst te creëren als een nieuw JSON-document in de weergave "Raster" in XMLSpy. U kunt de gegevens invoeren zonder zich zorgen te maken over de JSON-syntaxis. Op de afbeelding hieronder hebben we op het pictogram linksboven geklikt om de lijst in een tabelvorm weer te geven:
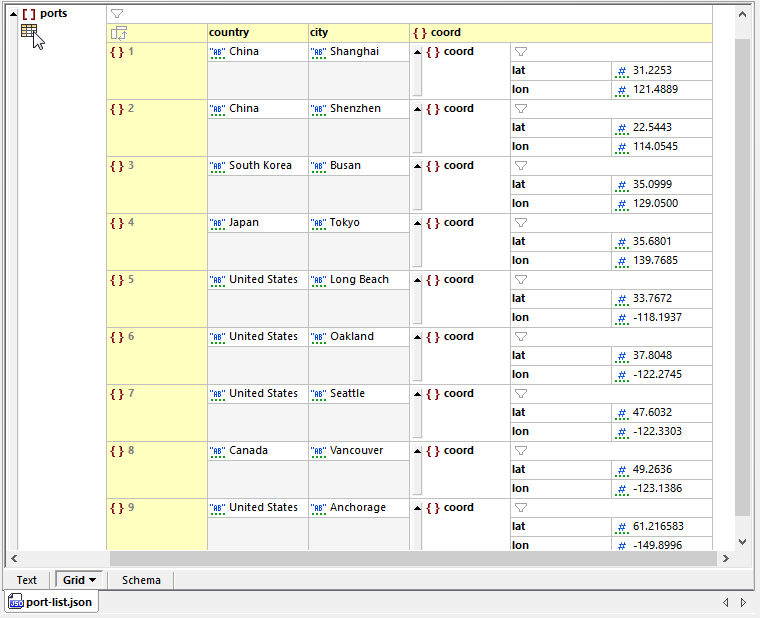
De weergave in tabelvorm maakt het veel gemakkelijker om de inhoud van een bestand te bekijken en te beoordelen, in tegenstelling tot de tekstweergave, die alle syntactische tekens weergeeft die nodig zijn in een geldig JSON-bestand.
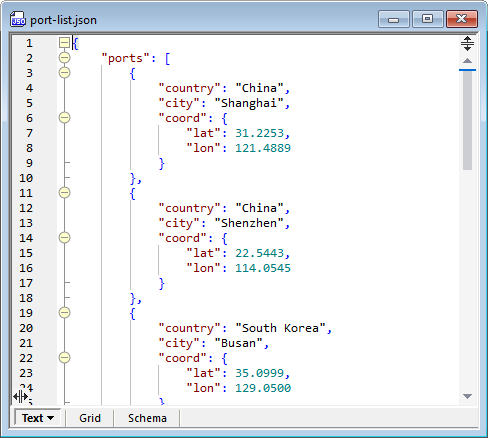
Overzicht van datamapping
Het MapForce-project voor data-integratie via een webdienst zal een lijst van havens als invoerbestand gebruiken. Vervolgens wordt voor elke set coördinaten een REST-verzoek gestuurd, en de resulterende JSON-gegevens voor elke haven worden omgezet in een Excel-werkblad.
MapForce gebruikt JSON-schema bestanden, die voldoen aan de specificaties van json-schema.org, om JSON-datastructuren te modelleren voor het uitvoeren van transformaties. MapForce kan automatisch een JSON-schema genereren op basis van een bestaand JSON-bestand. Dit werkt prima voor het enkele bestand "port-list.json".
We hebben ook een JSON-schema nodig om de data die door de webservice wordt geretourneerd te verwerken, wat iets complexer is. We hebben geen enkel .json-bestand met voorspellingen dat alle mogelijke variaties van vereiste en optionele data in de respons bevat.
Gelukkig kan XMLSpy een JSON-schema genereren op basis van meerdere documenten die zijn verzameld in een XMLSpy-projectmap.
Wanneer we het resulterende schema openen in de JSON Schema-weergave, zien we dat het "regen"-object optioneel is. Dit komt doordat ten minste één van de voorspellingsbestanden geen regen voorspelde over de gehele periode van 5 dagen, waardoor er in de reactie geen "regen"-objecten zijn opgenomen.
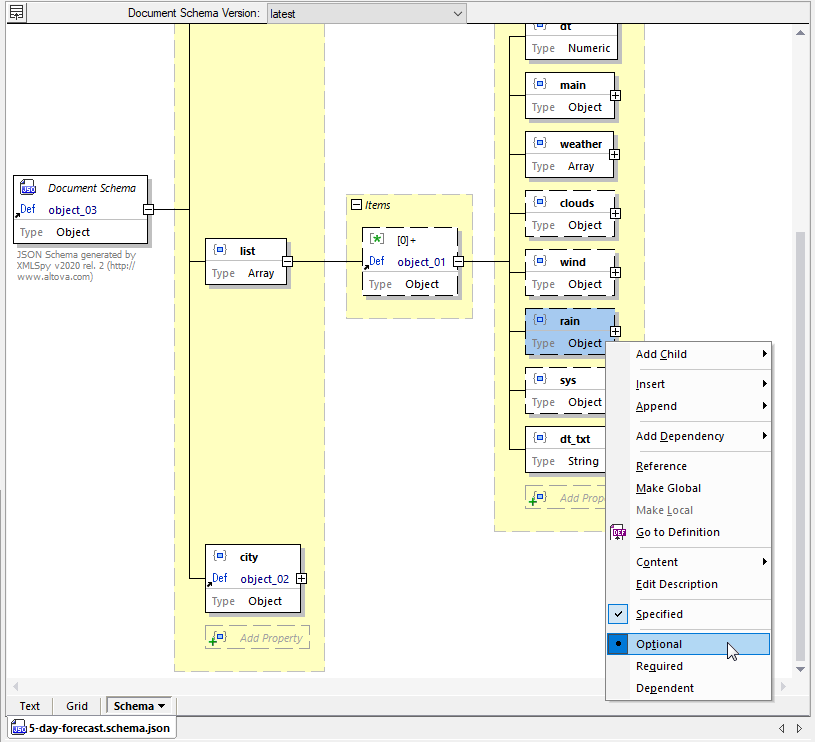
We kunnen dit schema gebruiken om de data die in de REST-response wordt teruggegeven, te beschrijven in de mapping.
Op de afbeelding hieronder zien we dat we zijn begonnen met het opzetten van de datamapping. Dit hebben we gedaan door het bestand "post-list.json" en een nieuwe webservice toe te voegen. We hebben de REST-URL toegevoegd en de breedte- en lengtecoördinaten als invoerparameters gebruikt om de aanvraag op te bouwen. Tot nu toe heeft de inhoud van het antwoord nog geen structuur.
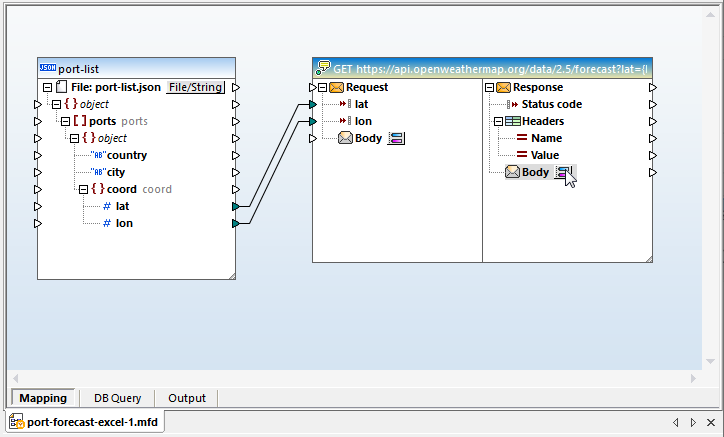
We kunnen op het hoofdgedeelte klikken om het dialoogvenster "Antwoordstructuur" te openen en het schema dat we in XMLSpy hebben gegenereerd, toewijzen:
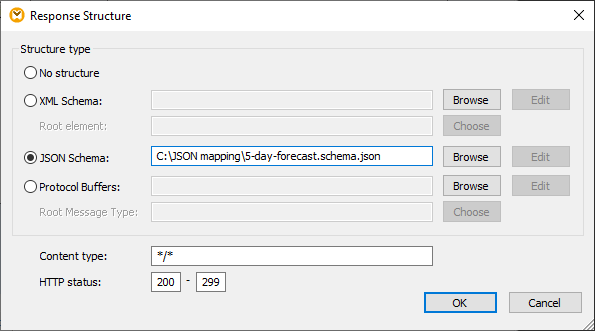
Zodra het schema is toegewezen, zijn alle elementen in de hoofdtekst beschikbaar om te koppelen
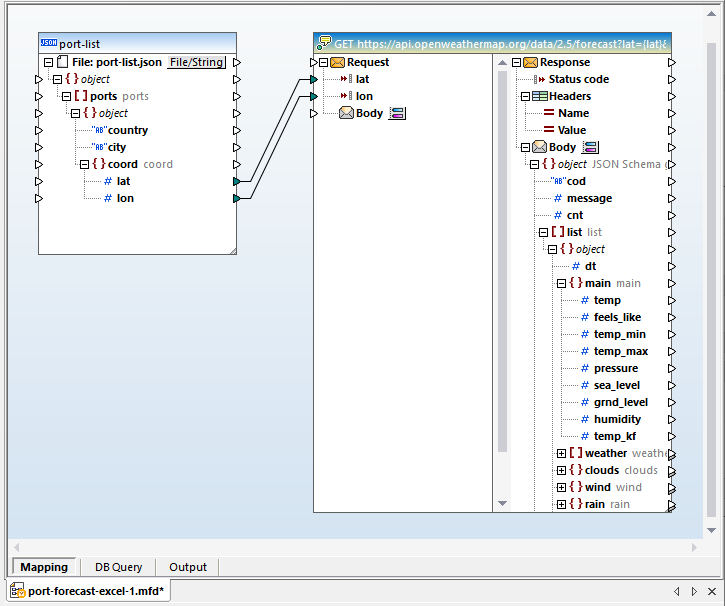
Nu kunnen we het doel-Excelbestand toevoegen. We hebben een voorbeeldspreadsheet gekregen die we als model kunnen gebruiken, met enkele celstijlen en grafieken, en met voorbeeldgegevens:
We kunnen deze spreadsheet toevoegen aan de dataintegratie-mapping van de webservice als doel, maar we moeten nog steeds bepalen welke cellen de data moeten ontvangen:
Door op de knop rechts van de invoervelden "Rijen 1, n=dyn" te klikken, wordt het dialoogvenster "Bereik selecteren" geopend. Rij 10 bevat de kolomkoppen voor de gegevens, dus we willen de hoofdtafel, beginnend bij rij 11, toewijzen aan de kolommen A tot en met K. De kolommen bevatten verschillende datatypes, die voornamelijk overeenkomen met tekst- of numerieke types in de JSON-bron en met opmaaktypes in Excel. Met het dialoogvenster "Bereik selecteren" kunnen we de exacte bestemmingen en datatypes definiëren:
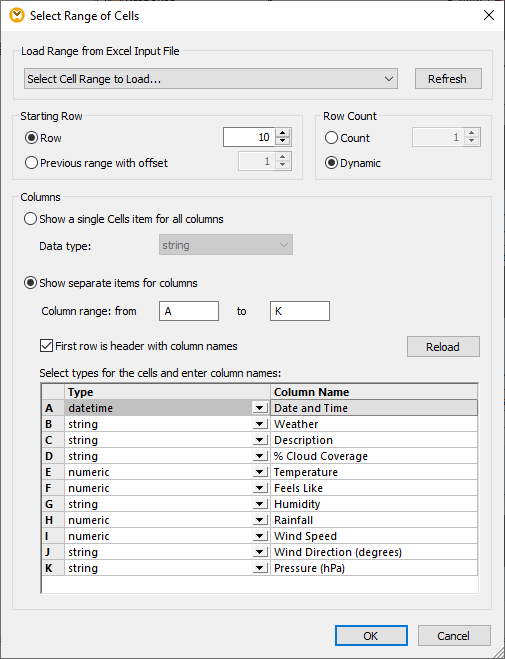
Het identificeren van de kolomnamen in het dialoogvenster "Selecteer bereik" voegt deze toe als labels in de uitvoermapping. Vervolgens kunnen we de logica opbouwen om elke prognose naar een apart Excel-bestand te schrijven, zoals hieronder te zien is:
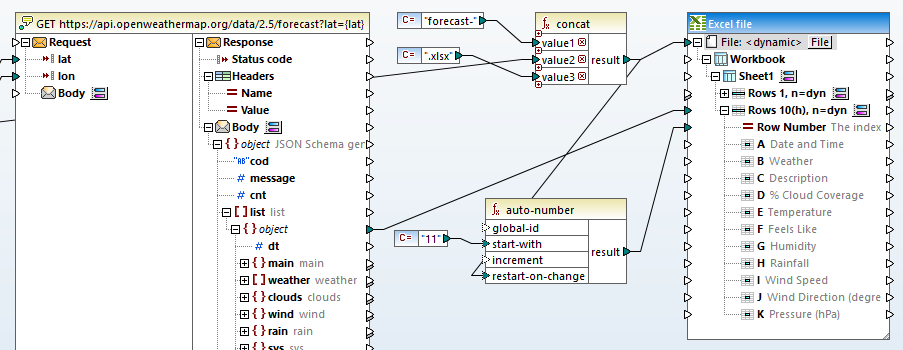
De bestandsnaam bovenaan in het Excel-doelbestand is ingesteld op
We moeten er ook voor zorgen dat de belangrijkste datatabel in elk bestand begint bij rij 11. Om dit te bereiken, hebben we het hoofdonderdeel van het lijstbestand gekoppeld aan de doelpositie bij rij 10, met n=dyn, en een automatische nummerfunctie gebruikt om de beginrij elke keer te resetten wanneer de bestandsnaam verandert.
Elk lijstobject in de reactie wordt toegewezen aan een nieuwe rij in de Excel-spreadsheet. Nu kunnen we de individuele items in de reactie koppelen aan kolommen in die rij. Op de afbeelding hieronder zien we dat alle items die geen verdere bewerking vereisen, zijn gekoppeld.
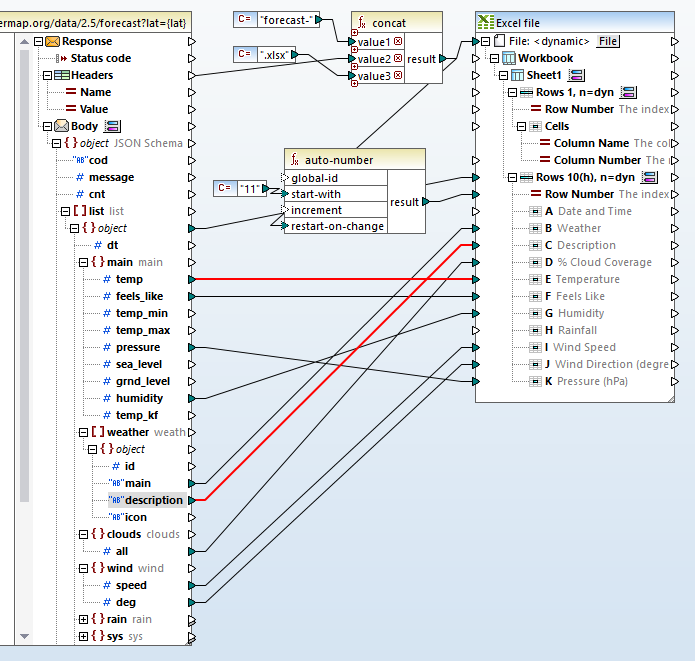
Voor de direct gekoppelde items komen de datatypes in de JSON-response overeen met de datatypes die we hebben opgegeven voor de kolommen in de spreadsheet. Zo is "Temp" in de bron-JSON numeriek, en kolom E in de doelbestemming is ook numeriek. Het datatype voor "description" in de bron is een string, en kolom B in de doelbestemming is ook een string, enzovoort.
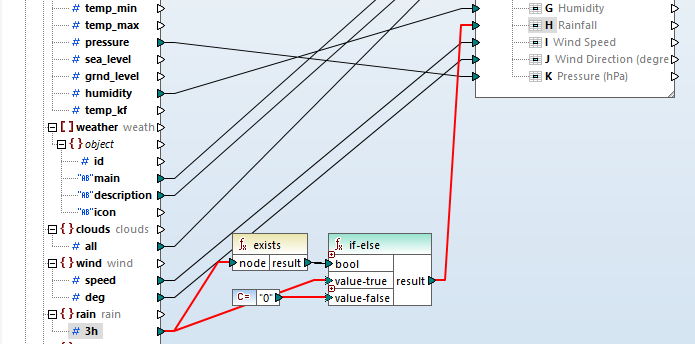
In het JSON-schema voor de reactie zagen we dat het object "regen" optioneel was. Als het niet bestaat, willen we de waarde vervangen door nul. Dit is eenvoudig te realiseren door een expressie te maken die de functies "bestaat" en "als-dan-anders" combineert:
Een beperking van het JSON-gegevensformaat is dat het slechts twee datatypes ondersteunt: string en numeriek. Datatypes zoals integer en datum/tijd, of speciale Excel-formaten zoals percentages en financiële berekeningen, zijn niet gedefinieerd in JSON. MapForce biedt handige, ingebouwde functies om brondata om te zetten naar de gewenste doeldatatypes in de mapping. Zo kunnen we het gewenste datum-/tijdformaat creëren in kolom A van de Excel-tabel.
Het veld "main.dt_text" in de JSON-data bevat een datum en tijd, weergegeven als een string, zoals: 2020-05-09 06:00:00. MapForce heeft een functie "parse-dateTime" die een string en een formatmodel als invoer accepteert en een resultaat in datum- en tijdformaat oplevert. Er is echter nog een complicatie: de dt-txt string is in de tijdzone GMT, en niet in de lokale tijd van de stad waarvoor de voorspelling is. De lokale tijdsverschil wordt aangegeven in het veld "city.timezone" als een positief of negatief aantal seconden.
Om het hoofdvenster voor het bewerken van gegevens overzichtelijk te houden, hebben we een gebruikersfunctie genaamd calc-local-time ontwikkeld. Deze functie neemt een string en een offset als invoer en berekent de lokale tijd. De gebruikersfunctie wordt op dezelfde manier gebruikt als een ingebouwde functie:
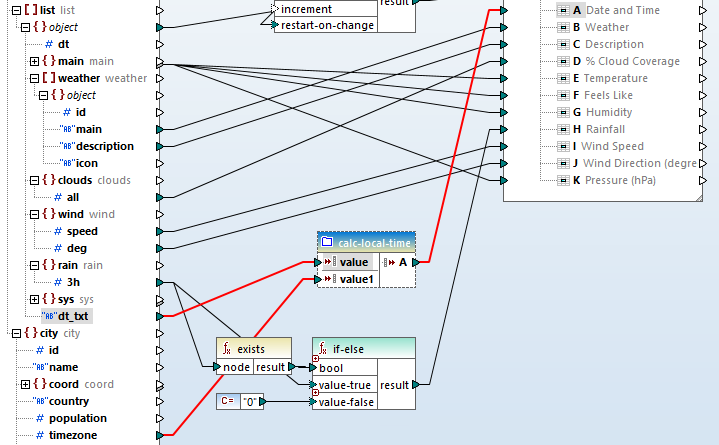
De laatste stap om de integratie van de webservicesgegevens te voltooien, is het combineren van de namen van de steden en landen en deze toevoegen aan rij 1, kolom C
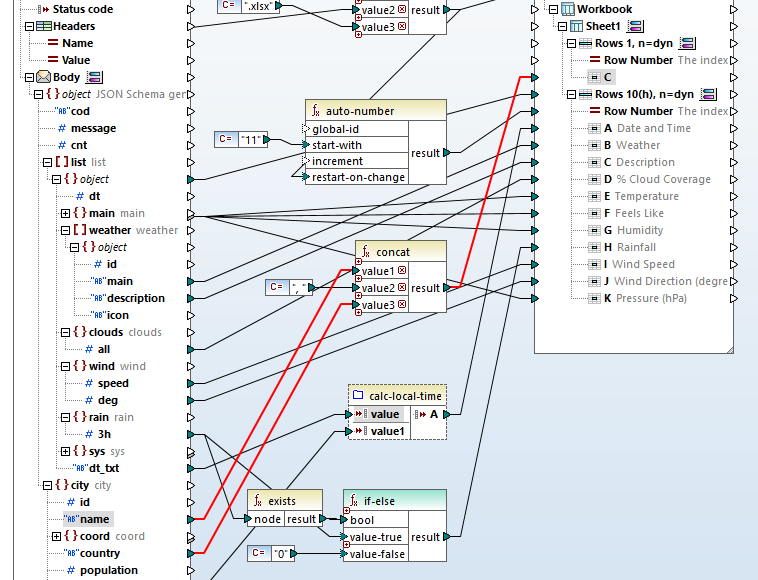
Hieronder vindt u een compleet overzicht van de definitieve indeling:
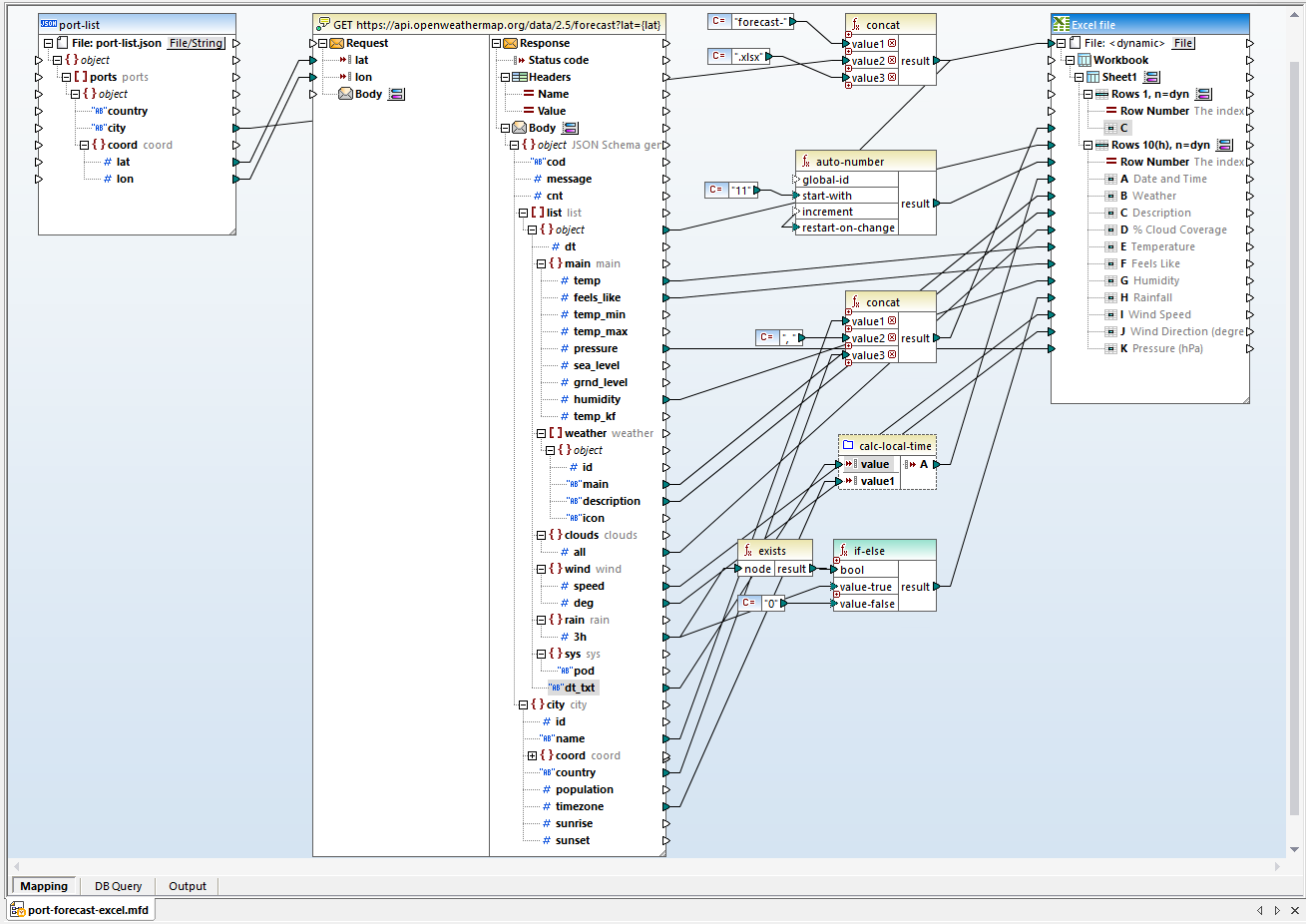
Om de Excel-documenten met de juiste opmaak voor elke stad te verkrijgen, hebben we een bestaand Excel-bestand nodig met de juiste opmaak, dat overeenkomt met elke gewenste bestandsnaam. Een batchbestand is een snelle manier om de originele bestanden te maken door herhaaldelijk een voorbeeld-Excelbestand te kopiëren, inclusief de opmaak en formules.
Resultaten van de integratie van web service data
Door op de knop "Uitvoer" linksonder in het venster voor de mapping te klikken, wordt de mapping uitgevoerd en worden de uitvoerbestanden gegenereerd. Als Excel op de werkstation is geïnstalleerd, wordt de uiteindelijke Excel-uitvoer weergegeven in het venster "Uitvoer":
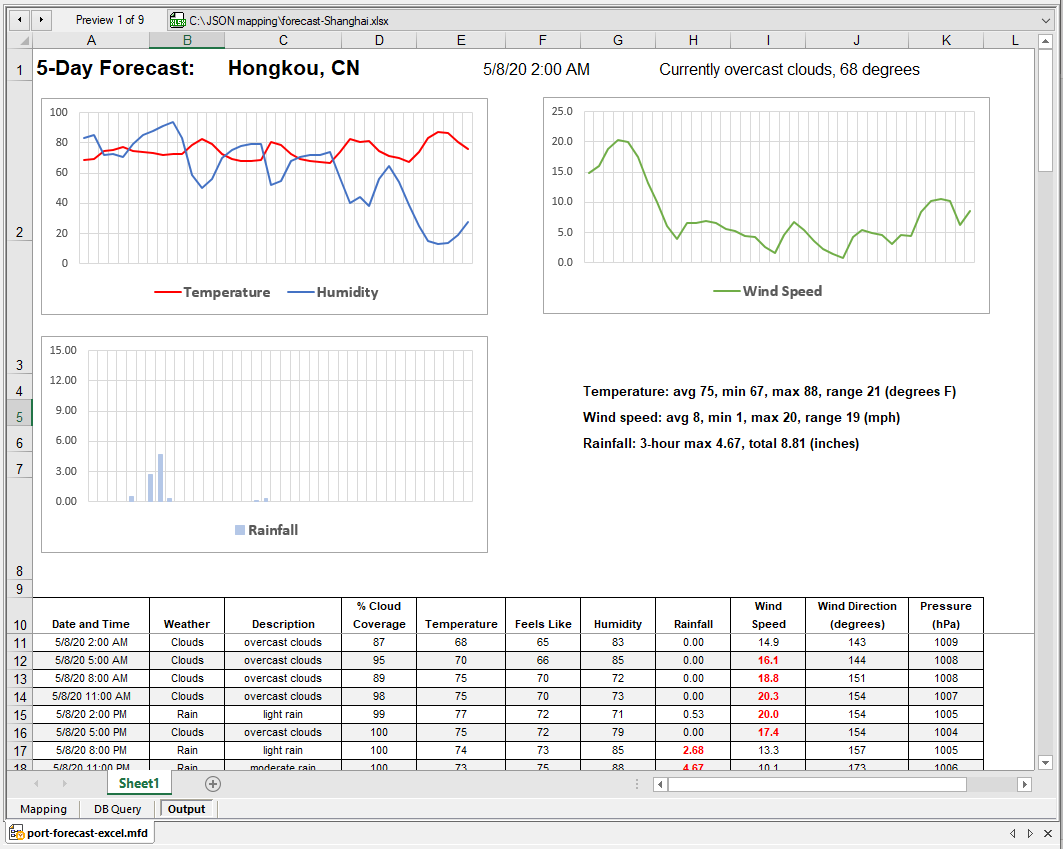
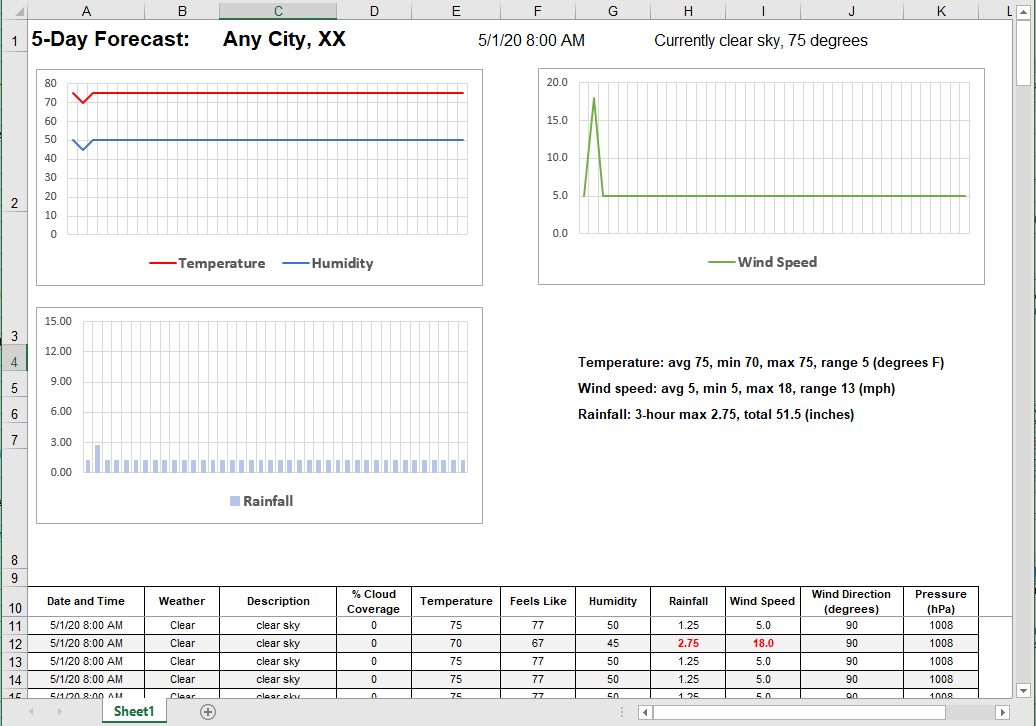
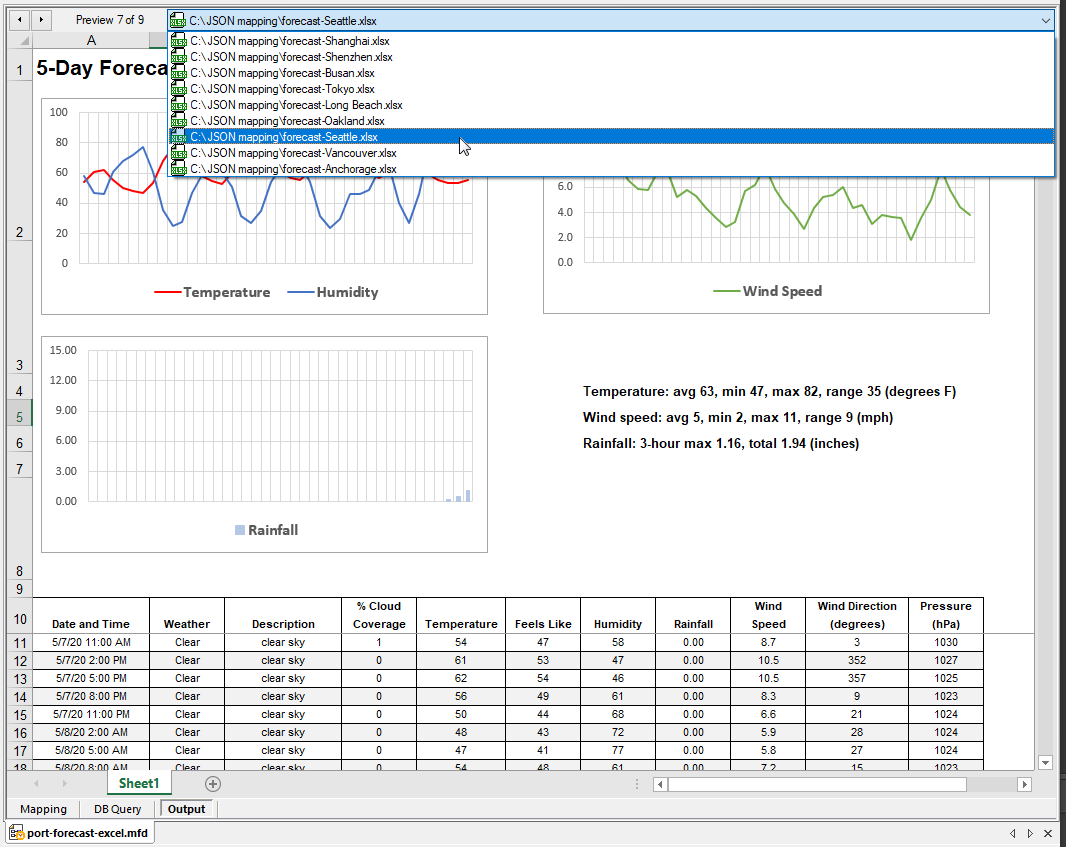
De datum en tijd, evenals het actuele weer, staan bovenaan, en de tekstsamenvattingen naast het neerslagdiagram worden gegenereerd door formules in de Excel-spreadsheet. Alle negen uitvoerbestanden zijn gemaakt, en we kunnen elk individueel bestand selecteren en bekijken. Hieronder staat de dropdown-lijst voor het selecteren van bestanden, en het zevende bestand met de voorspelling voor Seattle:
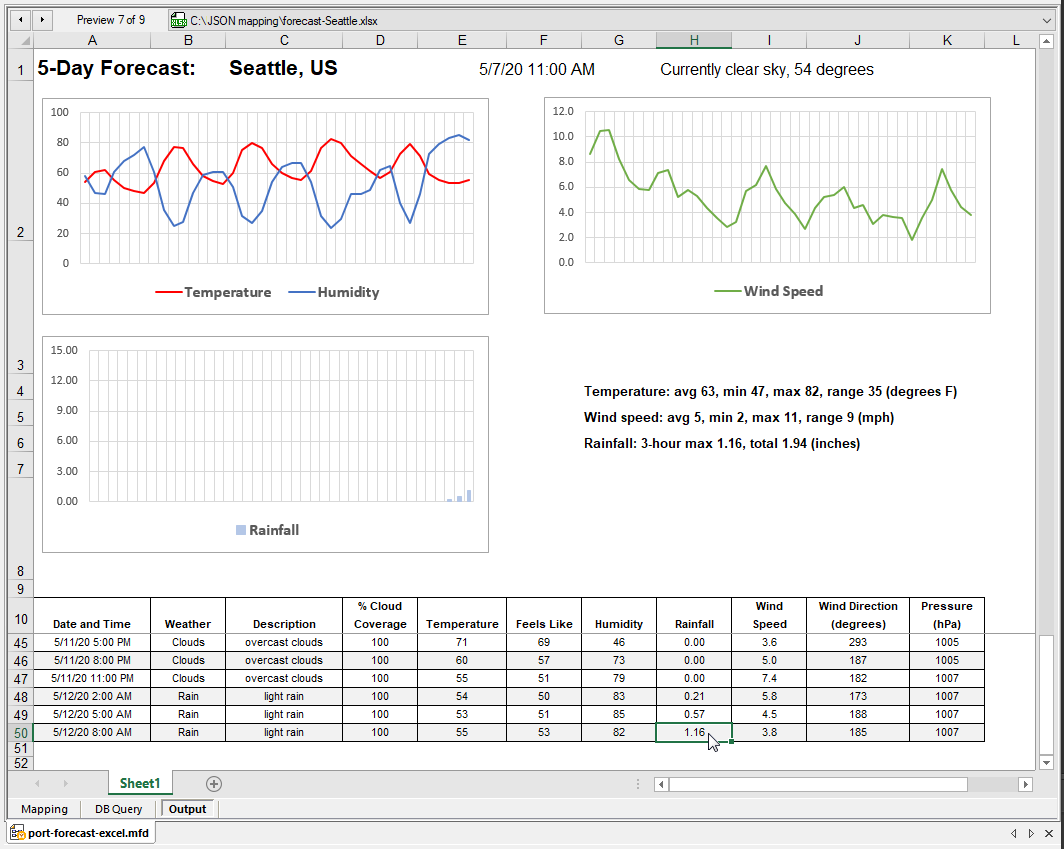
De functionaliteit van Excel is beschikbaar in het voorbeeldvenster. Zo maakt dit spreadsheet gebruik van een verdeeld scherm met scrollmogelijkheid, waarbij het bovenste gedeelte vaststaat. We kunnen naar de onderkant van de hoofdgegevens tabel scrollen om precies te zien hoeveel neerslag er in de laatste voorspelling wordt verwacht. Let op de rijnummers aan de linkerkant:
Als het resultaat bevredigend is, kunnen we één of alle gegenereerde bestanden opslaan:
Tussengegevens
MapForce is ontworpen voor efficiënte dataomzetting. We hoefden de tussenliggende JSON-data van de REST-response nooit op te slaan, te beheren of expliciet te manipuleren. De uitvoering van deze data-integratiemapping voor webdiensten slaat de tussenliggende data niet op.
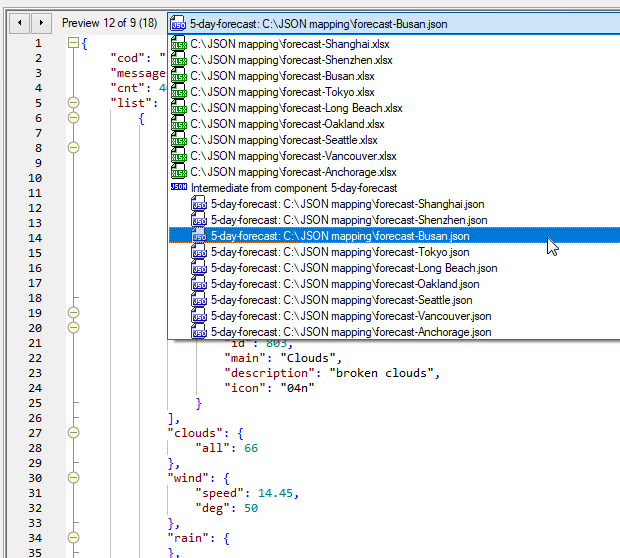
Als we de JSON-antwoordgegevens willen opslaan, samen met de uiteindelijke Excel-bestanden, biedt MapForce verschillende opties. Een mogelijkheid is het creëren van een gekoppelde mapping die de antwoordgegevens opslaat als een tussenliggend JSON-bestand, gebaseerd op hetzelfde schema als het antwoord. Vervolgens kunnen we dit JSON-bestand gebruiken om de Excel-output te genereren. Een gekoppelde mapping stelt u in staat om tussenliggende bestanden en het uiteindelijke resultaat te bekijken en op te slaan. Hieronder is een overzicht van de gegenereerde uitvoerbestanden van een gekoppelde mapping, met één van de JSON-bestanden in tekstweergave op de achtergrond:
Geautomatiseerde integratie van webbased data
Ons workflow-scenario vereist dagelijkse updates van de prognoses. We kunnen de mapping opslaan als een uitvoerbestand voor MapForce Server voor geautomatiseerde verwerking door MapForce Server, of we kunnen het direct implementeren op FlowForce Server om nieuwe prognoses te genereren volgens een geautomatiseerd schema. Een FlowForce Server-taak kan dataintegratietaken combineren met verschillende acties, waaronder systeemacties zoals het verplaatsen van bestanden of het verzenden van e-mails. Een FlowForce Server-taak kan ook complexe workflows uitvoeren die resultaten en parameters kunnen doorgeven om andere taken te activeren.
Bekijk een korte video-demo van MapForce, of download een gratis proefversie met tutorials, hulp en nog veel meer voorbeelden om aan de slag te gaan met uw eigen project voor de integratie van JSON- en webservices, of voor andere behoeften op het gebied van data-mapping, -conversie en -transformatie!