Hoewel PDF een alomtegenwoordige dataformat is in het bedrijfsleven, is de data die in PDF-bestanden staat niet gemakkelijk toegankelijk voor integratie met andere systemen. PDF-bestanden zijn doorgaans ontworpen voor leesbare content met variabele opmaak en lay-outs, waardoor het extraheren van gestructureerde data een enorme uitdaging is. Ze kunnen tekst, afbeeldingen, tabellen en andere elementen bevatten, en de data is niet georganiseerd in een machineleesbaar formaat. Standaard tools voor het extraheren van data uit PDF-bestanden leveren mogelijk niet altijd accurate resultaten, vooral bij PDF-bestanden met complexe lay-outs. Daar komt de MapForce PDF Extractor om de hoek kijken.
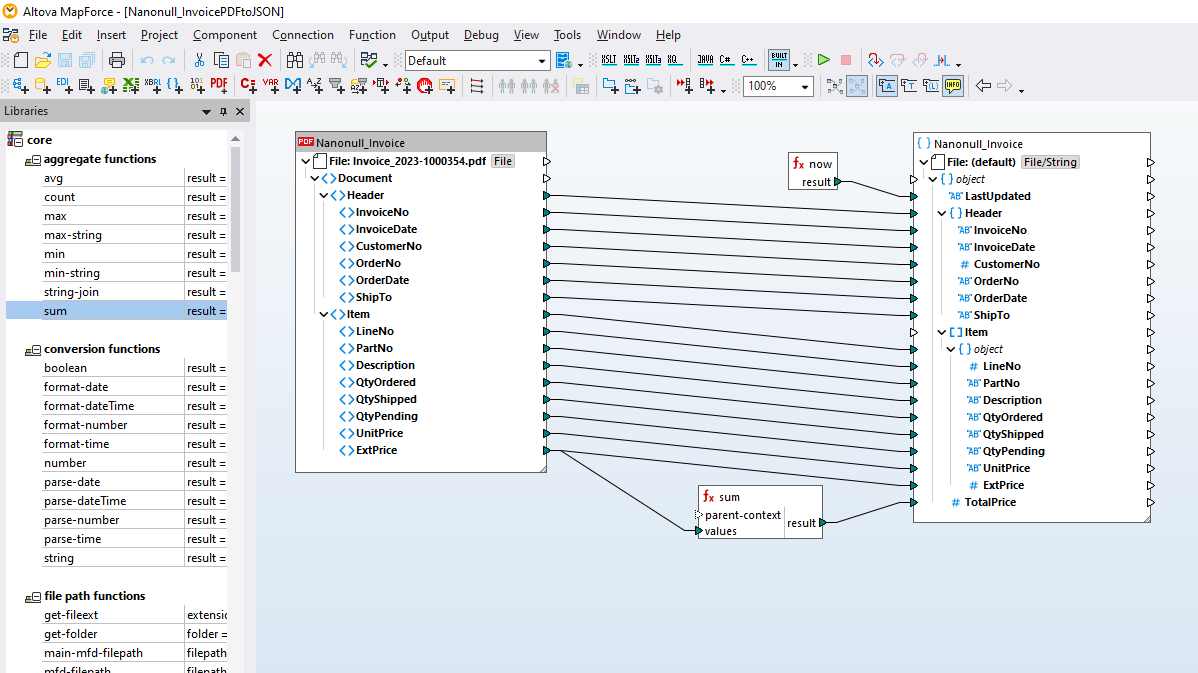
De MapForce PDF Extractor is een gebruiksvriendelijk hulpmiddel waarmee u snel de structuur van een PDF-document kunt definiëren en gegevens eruit kunt halen. Vervolgens kunnen deze PDF-gegevens in MapForce worden gebruikt voor verdere transformatie en conversie naar andere formaten, zoals XML, JSON, databases, Excel, enzovoort. Het is het ideale hulpmiddel voor het integreren van PDF-gegevens en voor ETL-projecten (Extract, Transform, Load).
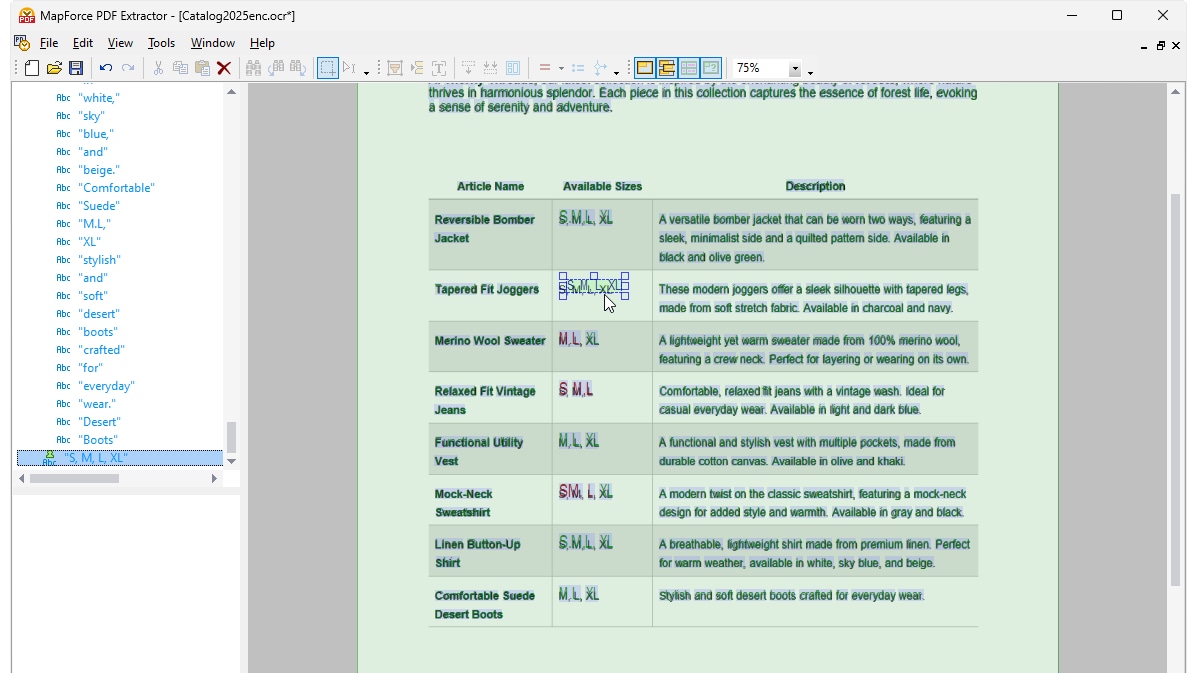
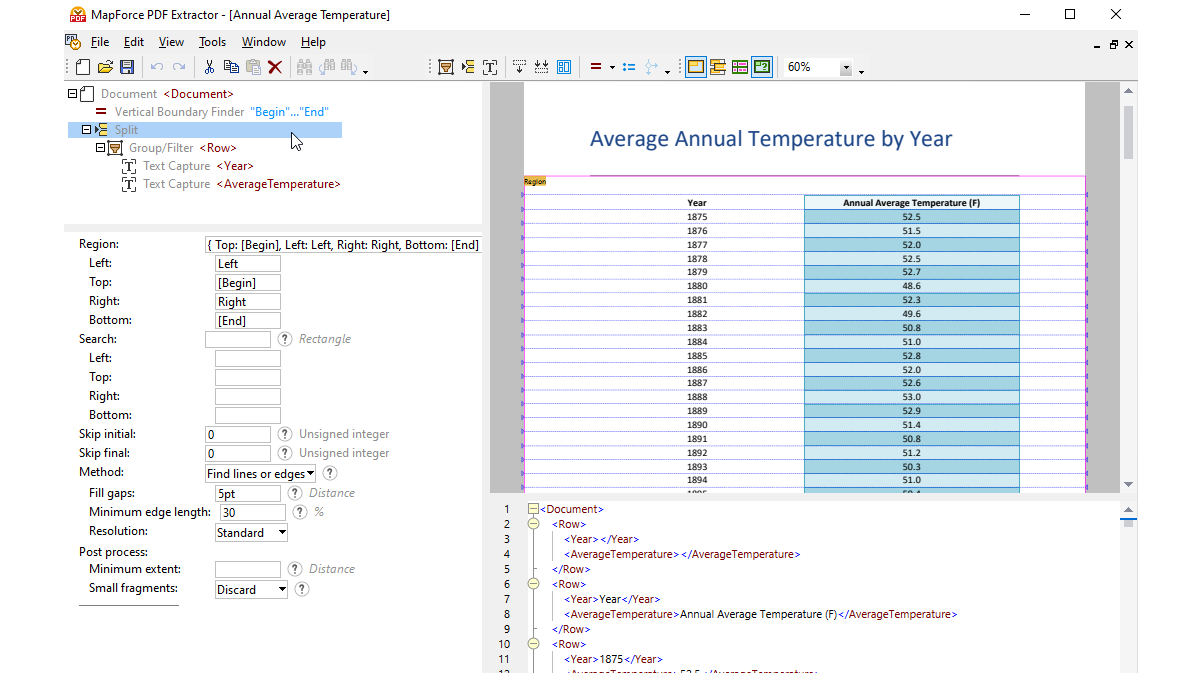
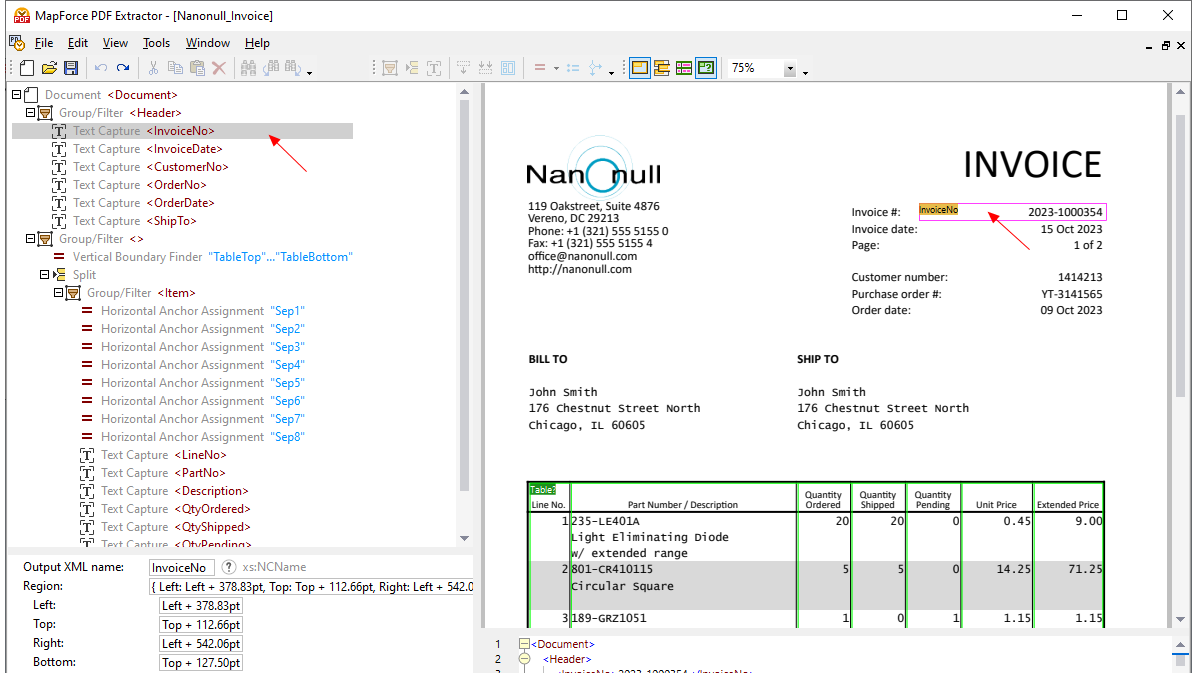
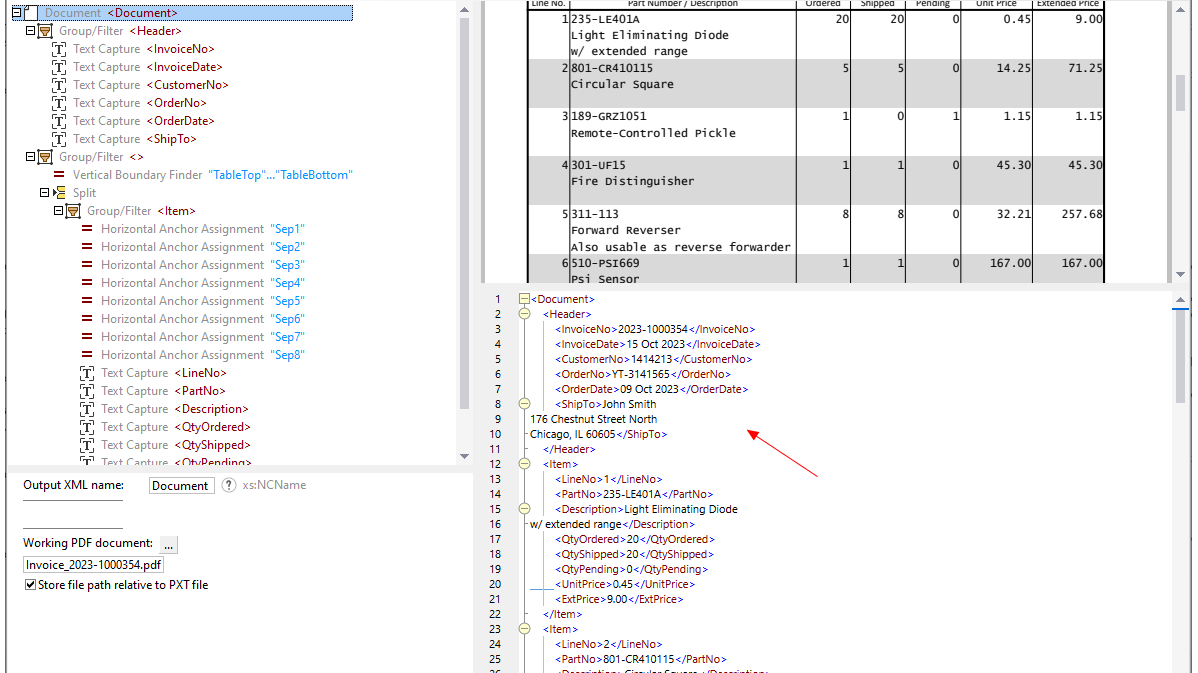
Met behulp van visuele hulpmiddelen in de MapForce PDF Extractor kunt u de structuur van een PDF-document definiëren en de gegevens ervan efficiënt extraheren. PDF Extractor is een zeer flexibel hulpmiddel waarmee u niet alleen delen van de tekst kunt extraheren in plaats van het hele document, maar ook informatie uit verschillende pagina's van hetzelfde PDF-bestand kunt combineren, tabellen in rijen kunt opsplitsen en gegevens in groepen kunt ordenen.
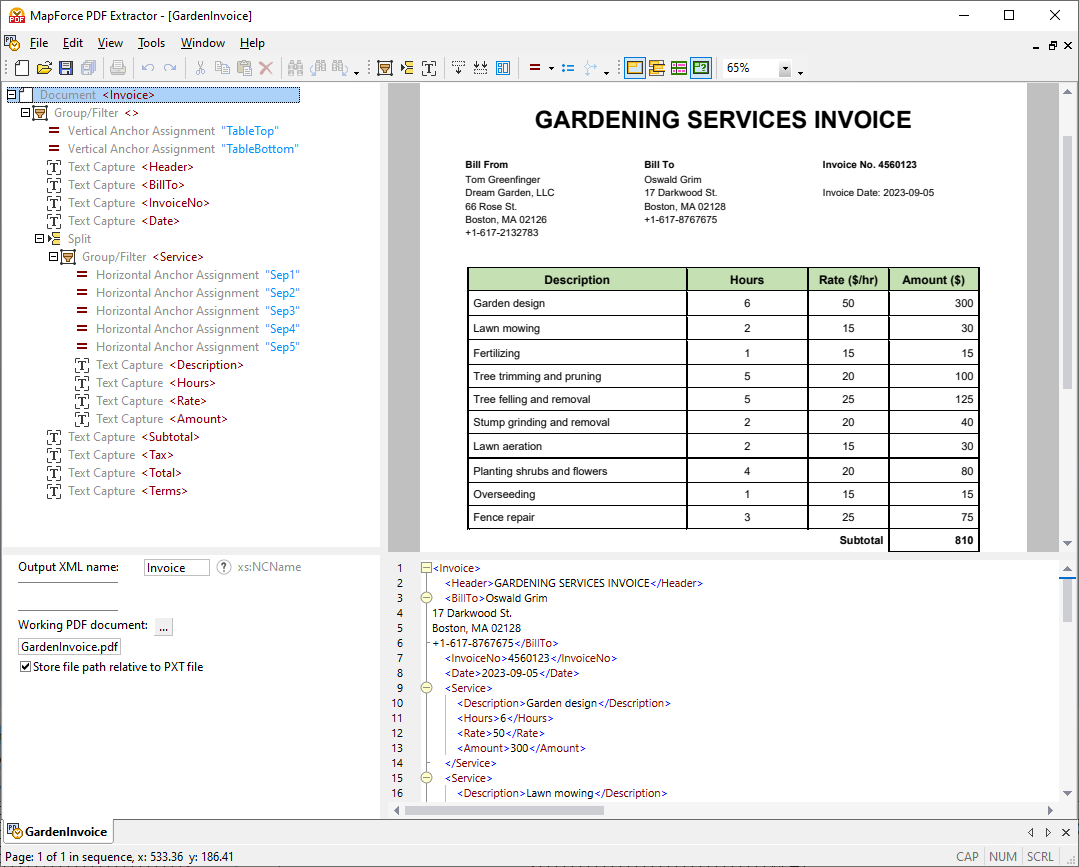
Het intuïtieve en overzichtelijke ontwerp van de MapForce PDF Extractor maakt het eenvoudig om de structuur van PDF-documenten op een visuele manier te definiëren, met behulp van functies waarmee u kunt klikken en slepen. Eindelijk kunnen de enorme hoeveelheden data die voorheen in PDF-bestanden waren opgesloten, worden omgezet naar andere formaten.