Embora o formato PDF seja amplamente utilizado no mundo empresarial, os dados contidos em PDFs não estão facilmente disponíveis para serem integrados a outros sistemas. Os PDFs são geralmente concebidos para conteúdo legível por humanos, com formatação e layouts variáveis, o que torna a extração de dados estruturados extremamente difícil. Podem conter texto, imagens, tabelas e outros elementos, e os dados não estão organizados num formato legível por máquinas. As ferramentas típicas de extração de dados de PDFs podem não fornecer resultados precisos, especialmente para PDFs com layouts complexos. É aí que entra o MapForce PDF Extractor.
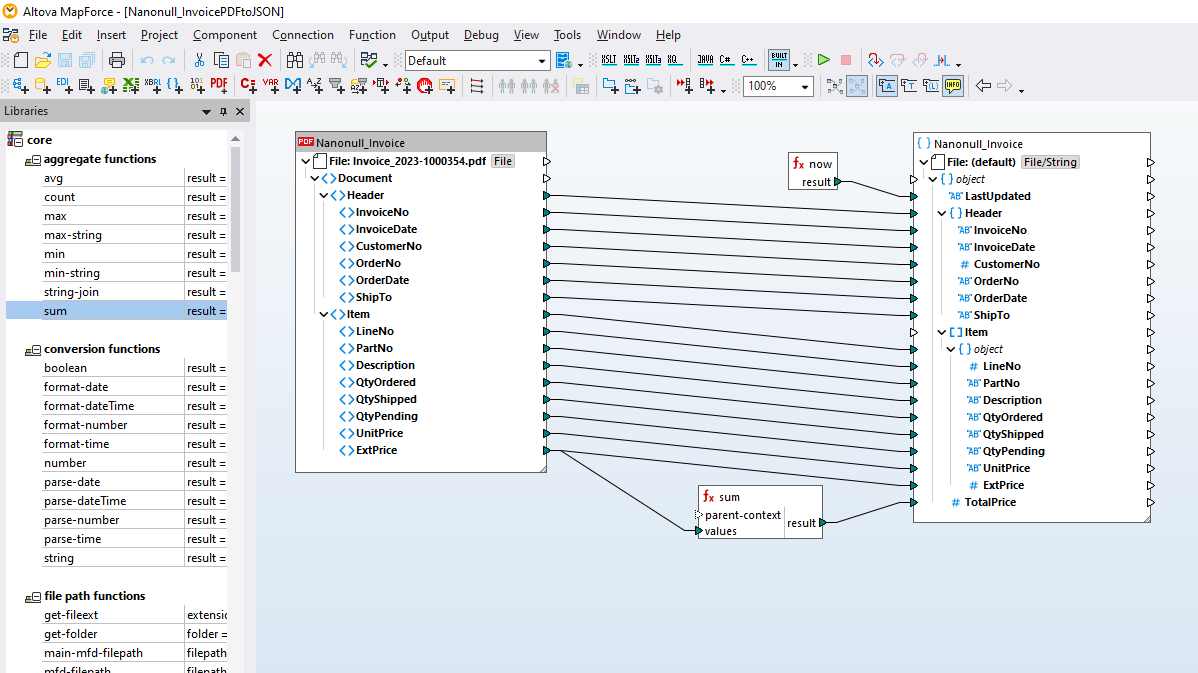
O MapForce PDF Extractor é uma ferramenta fácil de usar que permite definir rapidamente a estrutura de um documento PDF e extrair dados dele. Esses dados do PDF podem, posteriormente, ser acessados para transformação e conversão para outros formatos, como XML, JSON, bases de dados, Excel, e assim por diante, no MapForce. É a ferramenta ideal para facilitar a integração de dados PDF e projetos de ETL.
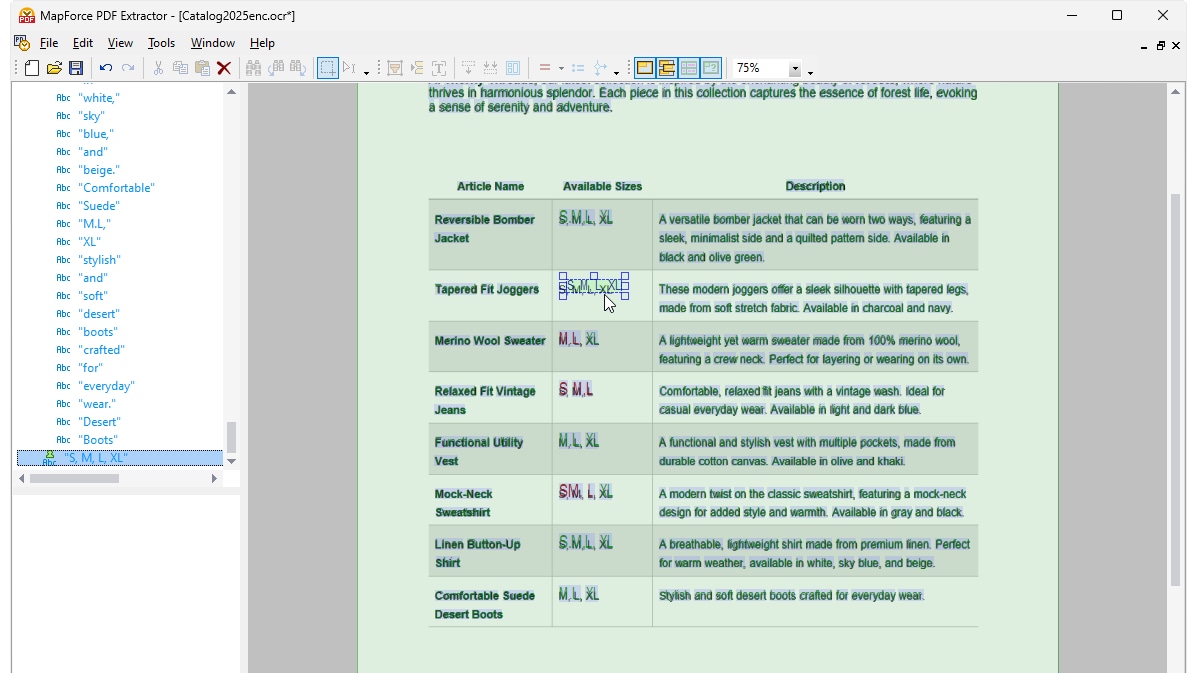
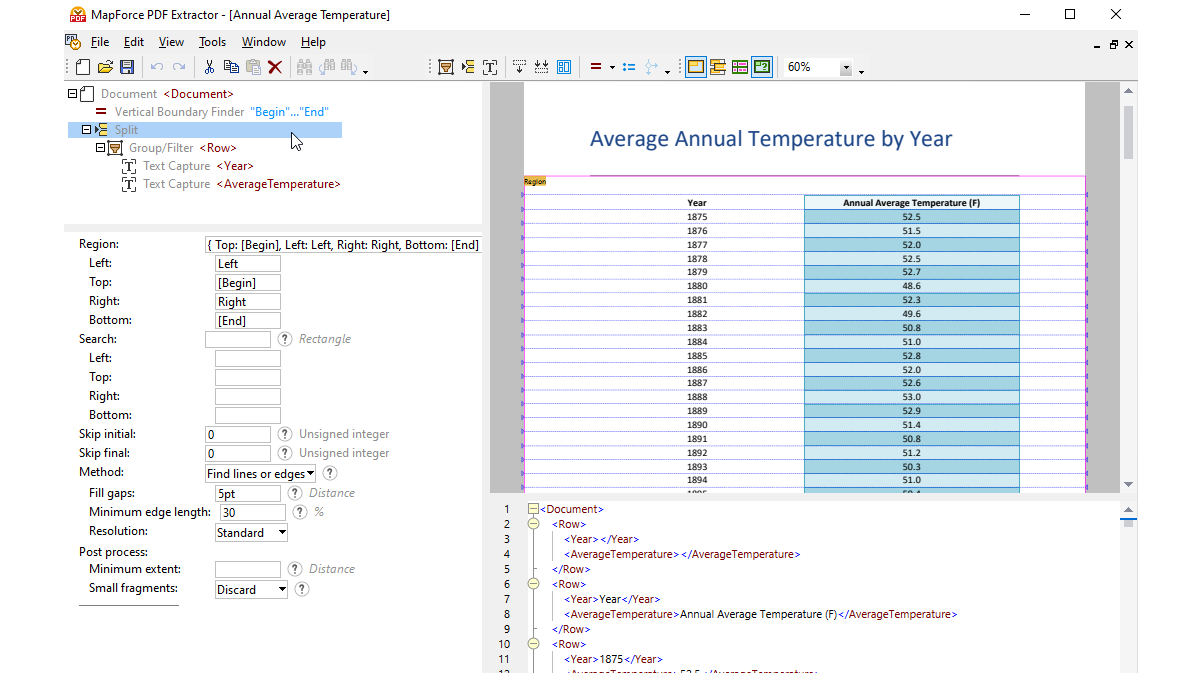
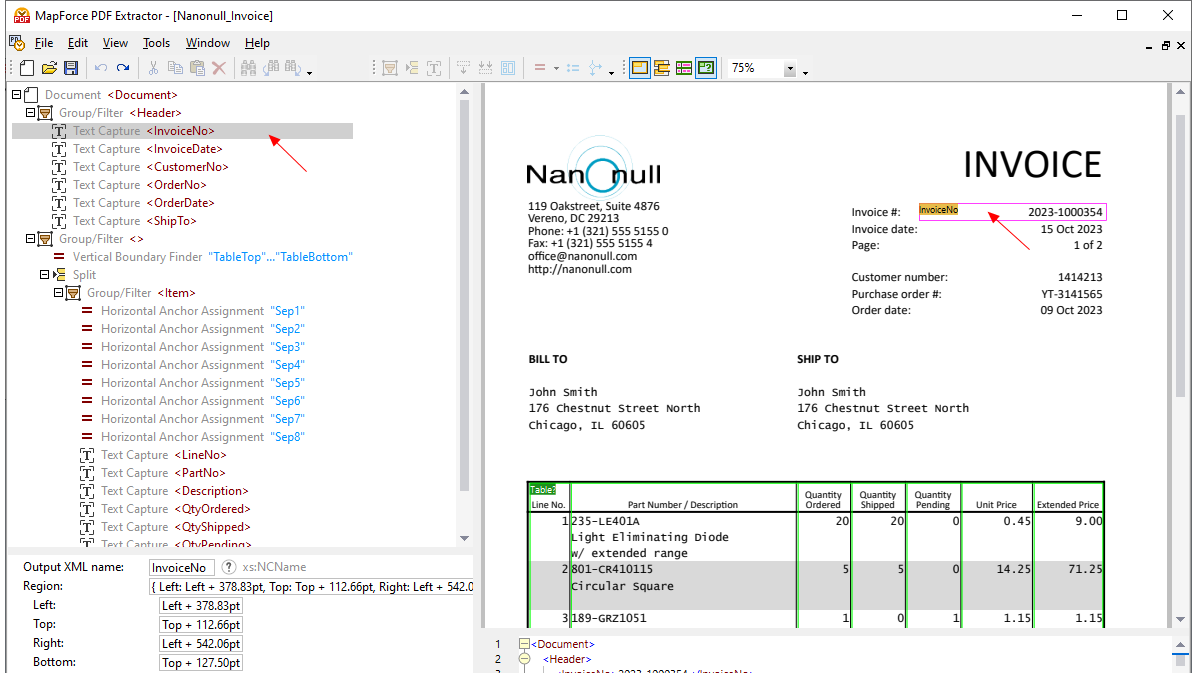
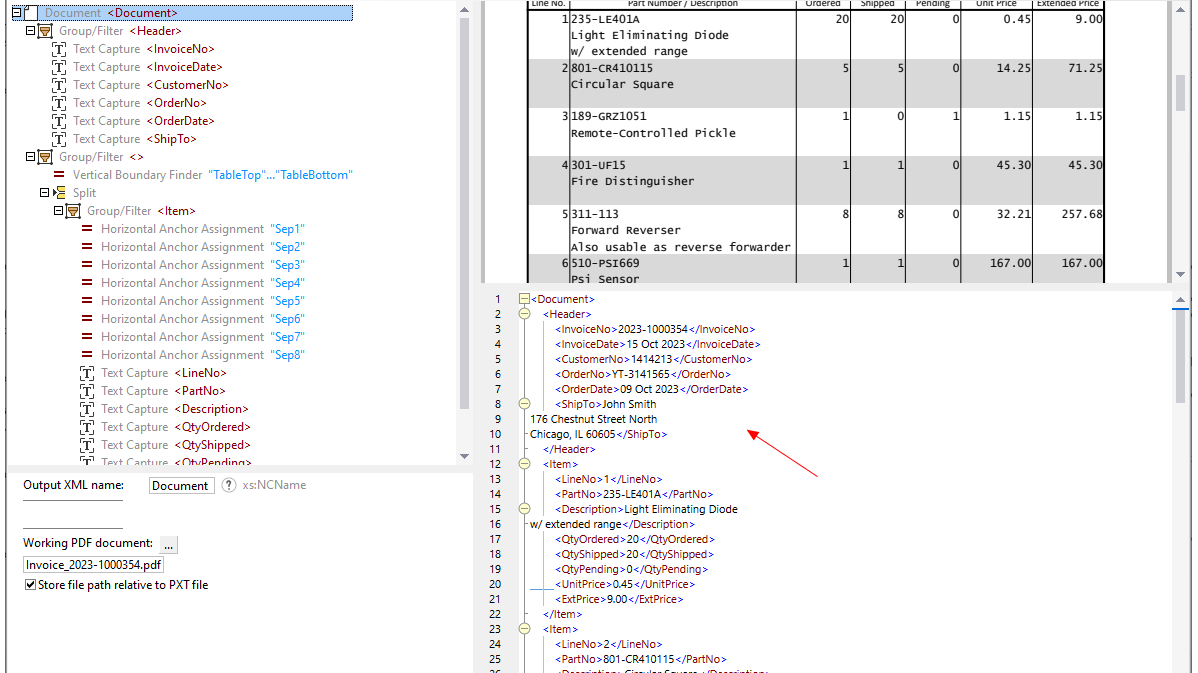
Utilizando ferramentas visuais no MapForce PDF Extractor, pode definir a estrutura de um documento PDF e extrair os seus dados de forma eficiente. O PDF Extractor é uma ferramenta altamente flexível que permite extrair apenas partes do texto, em vez de todo o documento, combinar informações de diferentes páginas do mesmo ficheiro PDF, dividir tabelas em linhas e organizar os dados em grupos.
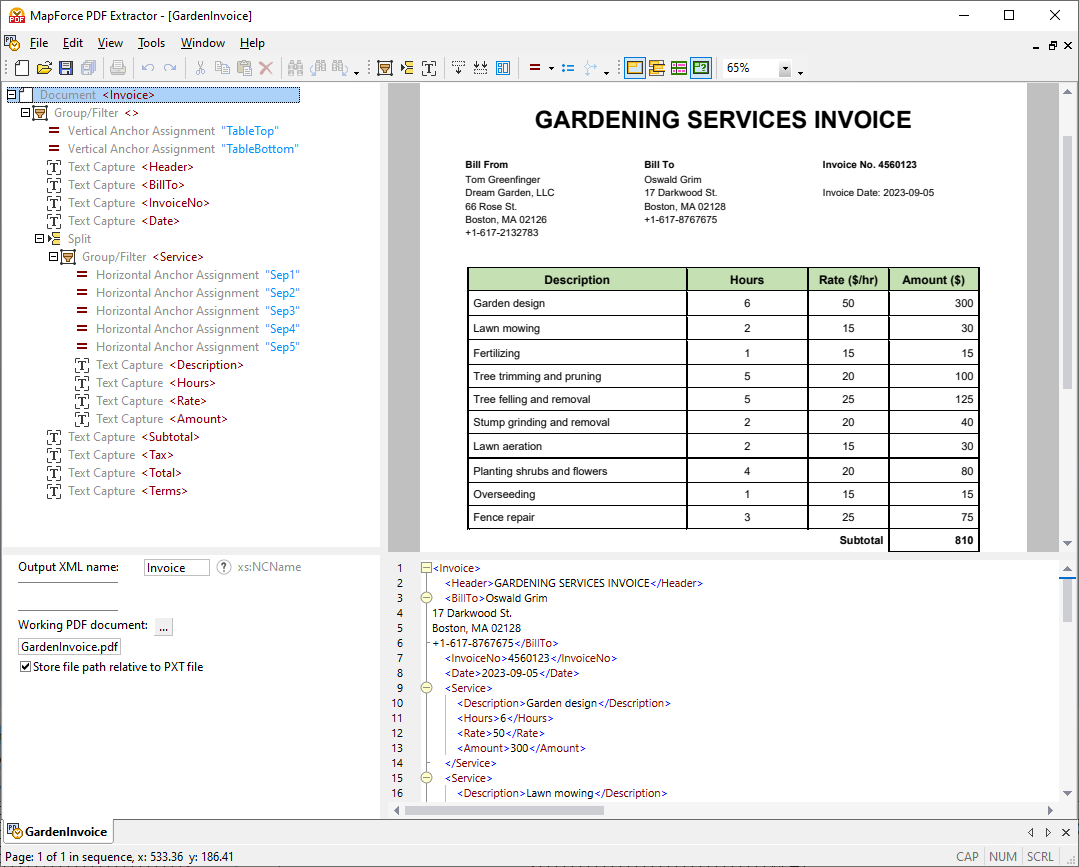
O design intuitivo e simples do MapForce PDF Extractor facilita a definição da estrutura de documentos PDF de forma visual, utilizando funcionalidades de seleção e arrastar e soltar. Finalmente, os grandes volumes de dados que antes estavam presos em documentos PDF estão agora disponíveis para serem convertidos para outros formatos.