Fusionner Source et Cible
Les objets Fusionner Source et Fusionner Cible vont de pair. L’objet Fusionner Source vous permet de découper un snippet de la page actuelle. Vous pouvez créer de multiples Fusionner Sources et les joindre ensemble en un seul Fusionner Cible qui traite les snippets recueillis de différentes pages en un seul groupe de pages. Fusionner Cible traite les snippets dans l’ordre dans lequel ils ont été ajoutés.
La combinaison de Fusionner Sources et Fusionner Cibles est bénéfique quand les données sont bien organisées et délimitées sur une page. Toutefois, dans des situations dans lesquelles, par exemple, une ligne commence sur une page et continue sur la prochaine page, il est recommandé d’utiliser un Collage.
Pour savoir comment ajouter les objets à l’arborescence modèle, voir Insérer un objet.
Propriétés dans le volet Propriétés
L’objet Fusionner Source possède deux propriétés dans le volet Propriétés : Région et Fusionner Cible. La propriété Région fait référence à l’emplacement de Fusionner Source sur la page. Pour les détails, voir la propriété Région dans l’objet Fractionner. La propriété Fusionner Cible fait référence au nom de l’objet Fusionner Cible qui recueillera Fusionner Sources en un seul groupe.
Notez que les valeurs du paramètre Fusionner Cible de toutes les Fusionner Sources que vous voulez joindre en un Fusionner Cible et le nom de leur Fusionner Cible correspondant (la propriété Nom) doivent être le même. Autrement, Fusionner Cible ne sera pas en mesure de joindre ces Fusionner Sources.
Exemple
Cet exemple affiche comment utiliser les objets Fusionner Source et Fusionner Cible. Le document PDF duquel vous voulez extraire les données est appelé BookCatalog.pdf. Le document a deux pages (capture d’écran ci-dessous) qui ont des mises en page légèrement différentes : Page 1 contient un en-tête, une table et un bas de page ; la table continue à la Page 2, et il existe également un bas de page. Le modèle d’extraction décrit dans cet exemple est disponible dans le dossier suivant : MapForceExamples\BookCatalog.pxt.
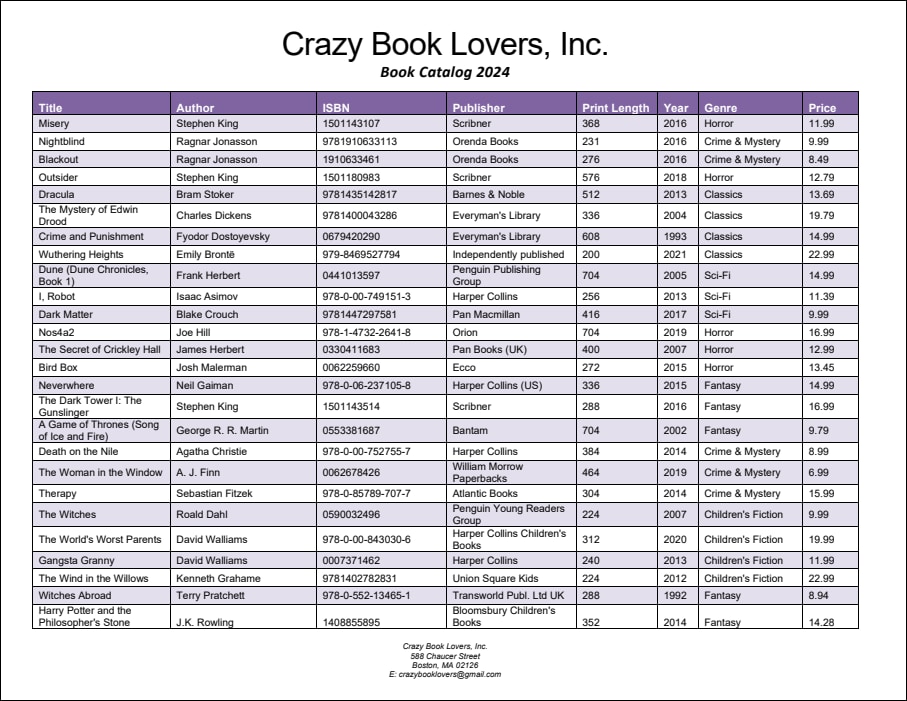
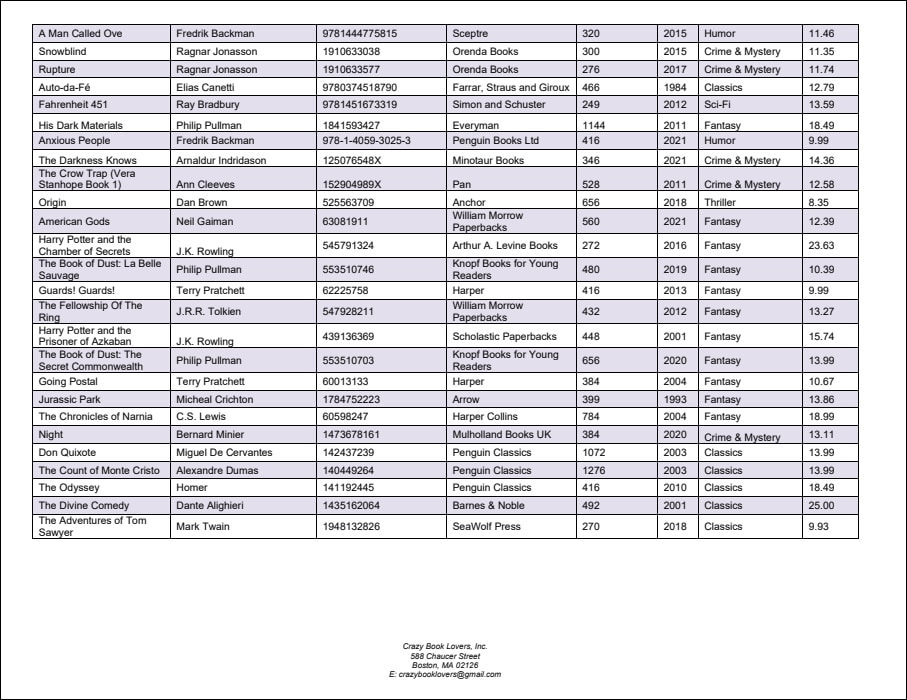
Objectifs
L'objectif de cet exemple est comme suit :
•Pour extraire le nom de l’entreprise
•Pour extraire toutes les données depuis la table des deux pages
•Pour exclure la ligne de bas de page et l’en-tête de la table du traitement
Mise en place
Pour obtenir des objectifs recensés ci-dessus, nous avons créé l’arborescence modèle suivante :
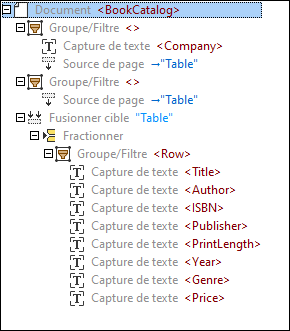
Sous l’élément racine appelé BookCatalog, il existe un objet Groupe/Filtre qui traite les objets uniquement à la première page (Sélectionner Groupes défini comme 1) du document PDF. L’objet Groupe/Filtre inclut deux Captures de texte comme nœuds enfant : Company, qui fait référence au nom de l’entreprise en haut du document PDF et CatalogYear (capture d’écran ci-dessous).


Cet objet Groupe/Filtre contient également un objet Fusionner Source qui a une région englobant toutes les lignes à la première page, à l’exception de la ligne d’en-tête. Nous avons défini la région manuellement (au lieu d’utiliser les suggestions de table automatiques). Un extrait de la région du premier Fusionner Source est illustré ci-dessous.

Le deuxième objet Groupe/Filtre traite la deuxième page (Sélectionner Groupes défini comme 2) du document PDF et inclut également un Fusionner Source. La raison pour laquelle nous créons deux groupes séparés est que les mises en page des pages ne sont pas les mêmes. Pour cette raison, nous ne pouvons pas appliquer la même logique de traitement à ces pages.
L’objet Fusionner Cible recueille les snippets des deux Fusionner Sources en un groupe. En ce qui concerne Fusionner Cible afin de recueillir correctement les Fusionner Sources pertinentes, les Fusionner Cible et Sources correspondantes doivent avoir les mêmes noms (dans notre exemple, Table). Une fois que tous les snippets ont été recueillis, ils sont regroupés en lignes (l’objet Groupe/Filtre avec Captures de texte). Chaque ligne contient des informations sur un livre, son auteur, l’ISBN, l’éditeur de publication, la longueur d’impression, l’année, le genre et le prix. L’objet Groupe/Filtre est enveloppé dans l’objet Fractionner et affiche le résultat du fractionnement de Fusionner Cible en lignes de données.
Sortie
La définition des règles d’extraction est complète. Le volet Sortie affiche la structure que nous avons défini et les données que nous avons choisi pour les extraire du document PDF. Un extrait de la sortie est affiché dans la liste de code suivante.
<BookCatalog>
<Company>Crazy Book Lovers, Inc.</Company>
<CatalogYear>2024</CatalogYear>
<Book>
<Title>Dune (Dune Chronicles, Book 1)</Title>
<Author>Frank Herbert</Author>
<ISBN>0441013597</ISBN>
<Publisher>Penguin Publishing Group</Publisher>
<PrintLength>704</PrintLength>
<Year>2005</Year>
<Genre>Sci-Fi</Genre>
<Price>14.99</Price>
</Book>
<Book>
<Title>Dark Matter</Title>
<Author>Blake Crouch</Author>
<ISBN>9781447297581</ISBN>
<Publisher>Pan Macmillan</Publisher>
<PrintLength>416</PrintLength>
<Year>2017</Year>
<Genre>Sci-Fi</Genre>
<Price>9.99</Price>
</Book>
<Book>
<Title>Nos4a2</Title>
<Author>Joe Hill</Author>
<ISBN>978-1-4732-2641-8</ISBN>
<Publisher>Orion</Publisher>
<PrintLength>704</PrintLength>
<Year>2019</Year>
<Genre>Horror</Genre>
<Price>16.99</Price>
</Book>
<...>
</ BookCatalog>