Ajouter une base de données NoSQL
Pour pouvoir travailler avec les bases de données NoSQL dans MapForce, vous allez devoir ajouter une base de données NoSQL comme composant de mappage et y attribuer un schéma. Suivez les instructions ci-dessous :
Ajouter une base de données NoSQL à votre mappage
Pour les bases de données NoSQL, MapForce ne prend en charge que le langage de transformation Built-In. Les instructions ci-dessous expliquent comment ajouter des collections provenant d'une base de données MongoDB à un mappage. Notre base de données exemple s’appelle doc.
1.Dans un premier temps, nous devons sélectionner une base de données source (MongoDB dans notre cas). Allez au menu Insérer and cliquez sur base de données. En alternative, cliquez sur le bouton de la barre d’outils  (Insérer la base de données).
(Insérer la base de données).
2.Sélectionnez MongoDB dans l’assistant de connexion et cliquez sur Suite.
3.La boîte de dialogue Sélectionner une base de données vous demande de fournir les paramètres suivants : Hôte, Port, Base de données, Nom utilisateur et Mot de passe. Saisir les paramètres requis et cliquez sur Connecter. Dépendant du type de base de données, les détails de connexion varieront. Pour plus d’information, voir MongoDB Connection, CouchDB Connection, et CosmosDB Connection.
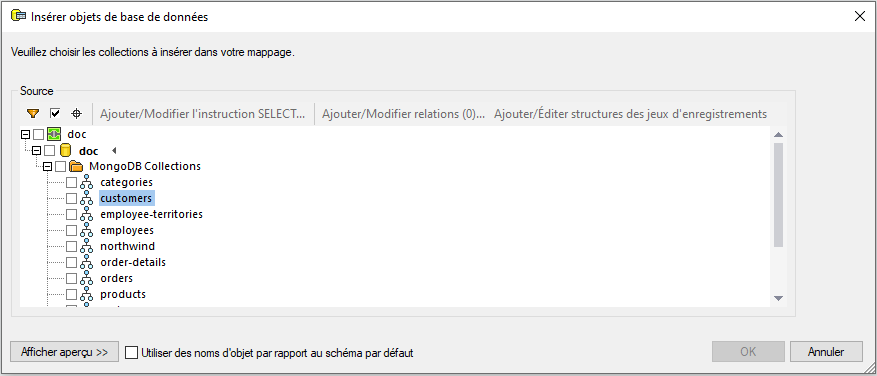
4.La boîte de dialogue Insérer les objets de base de données s’ouvrira et vous demandera de sélectionner les collections que vous aimeriez utiliser dans votre mappage (voir la capture d'écran ci-dessous). Vérifiez les cases pertinentes et cliquez sur OK.
5.Désormais, votre composant de base de données NoSQL contient une collection dénommée clients(voir la capture d’écran ci-dessous).
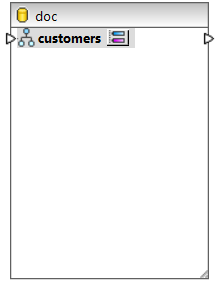
La prochaine étape attribuera un schéma JSON afin de définir la structure de votre collection.
Note : lorsque vous vous connectez à un cluster MongoDB, vous allez éventuellement devoir contacter votre département TI pour obtenir un accès pare-feu aux adresses IP de votre cluster et port.
Attribuer un Schéma JSON
Après avoir sélectionné les documents pertinents dans la collection doc, il faut attribuer un schéma JSON au composant NoSQL. Suivez les instructions ci-dessous :
1.Cliquez sur le ![]() bouton (Attribuer un schéma JSON) situé à droite du nom de la collection (clients). Ceci ouvre la boîte de dialogue Attribuer un schéma JSON à la collection (voir la capture d'écran ci-dessous).
bouton (Attribuer un schéma JSON) situé à droite du nom de la collection (clients). Ceci ouvre la boîte de dialogue Attribuer un schéma JSON à la collection (voir la capture d'écran ci-dessous).
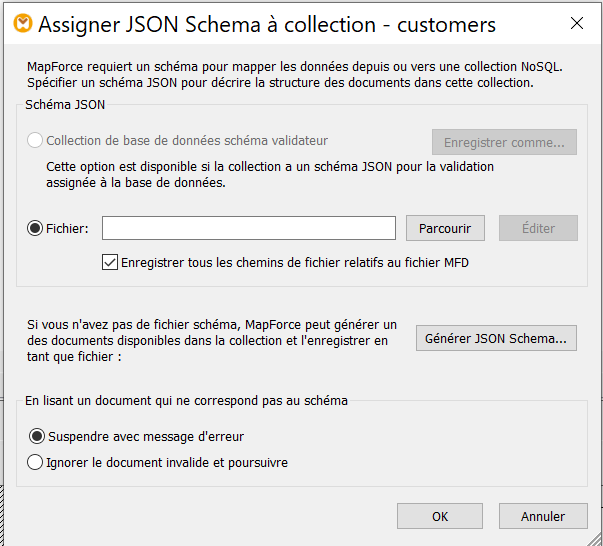
2.Pour assigner un schéma JSON, vous pouvez choisir l’une des trois options : (i) choisir un schéma assigné à votre base de données ; (ii) parcourir pour trouver le schéma JSON existant sur votre appareil local ; (iii) solliciter MapForce à générer un nouveau fichier de schéma.
i.Si vous choisissez la première option, vous serez à même d’exporter un schéma JSON depuis votre base de données (cliquez Enregistrer en tant que ).
ii.Si vous avez déjà un schéma JSON pour votre fichier source, cliquez sur Naviguer et recherchez le schéma pertinent. Quand vous choisissez de charger votre fichier de schéma, le bouton Editer est activé. Quand vous cliquez sur le bouton, votre fichier de schéma s’ouvrira dans Altova XMLSpy s’il est installé sur votre appareil.
iii.Si vous n'avez pas de schéma, MapForce peut vous en générer un. Dans ce cas, cliquez sur Générer le schéma JSON.
Vous devez également spécifier si le traitement du document s’arrêtera ou se poursuivra s’il y a des documents qui ne correspondent pas au schéma (voir la dernière section de la boîte de dialogue ci-dessus). Veuillez noter que ces deux options s’appliquent lors de l’exécution du mappage.
3.Si vous cliquez sur Générer le schéma JSON, la boîte de dialogue Générer le schéma JSON s’ouvrira. Laissez les zones de textes FILTRER et TRIER vides si vous ne voulez pas spécifier de critère de filtrage et de tri. Ensuite, cliquez sur OK. Veuillez noter que vous pouvez aussi spécifier le nombre de documents dont le parser a besoin pour l’analyse. L’option SKIP dit au parser d’ignorer les premiers documents N dans la collection. L’option LIMIT dit au parser d’analyser uniquement les premiers documents N dans la collection. Le schéma du composant de la base de données sera ensuite basé sur la structure des documents spécifiés par la combinaison de ces critères. Pour plus d'informations concernant FILTRER et TRIER, voir la sous-section ci-dessous.
4.Quand vous cliquez sur OK, vous allez devoir donner un nom au fichier de schéma et sélectionnez le dossier désiré dans lequel vous voulez l’enregistrer. Après avoir fait ceci, cliquez une nouvelle fois sur OK.
Désormais, votre composant de base de données a une structure arborescente et est prêt pour le mappage.
FILTRER et TRIER
Sans options de requête dans les zones de texte FILTRER et TRIER (la boîte de dialogue Générer le schéma JSON), MapForce lira tous les documents dans la collection pour générer un schéma. Toutefois, les collections peuvent contenir des milliers de documents, ce qui prendrait énormément de temps de traitement. Dans ce cas, la meilleure stratégie à adopter serait de sélectionner un sous-ensemble de documents, qui couvre toutes les variantes de structures, que vous désirez traiter dans votre mappage. Dans ce contexte, le terme variantes de structure spécifie quelles propriétés existent dans le document et quels types ces propriétés peuvent avoir.
Il est improbable que les documents dotés de structures complètement différentes seront stockés dans la même collection, mais il pourrait y avoir de nombreux champs supplémentaires qui n’apparaissent que dans quelques documents. Les scénarios suivants sont possibles :
•Si le filtre ne sélectionne que des documents qui n’ont pas de champ présent dans un autre document, le schéma ne contiendra pas ce champ. Si un tel champ est rencontré plus tard lors de l’exécution dans un document, une erreur de validation apparaitra ou alors il n’y aura pas de nœud vers lequel vous pourrez mapper dans le composant cible.
•Si tous les documents échantillonnés contiennent une propriété spécifique, cette propriété sera marquée, tel que requis dans le schéma, et un document (qui aura pu être ajouté plus tard à cette collection) sans cette propriété sera invalide par rapport au schéma.
Dans la pratique, un schéma généré d’un échantillon limité de documents pourrait être incomplet et requiert des modifications manuelles : par exemple, pour permettre des propriétés supplémentaires, rendre certaines propriétés optionnelles, ou permettre les types de données supplémentaires pour quelques propriétés.
Exemple FILTRER
Dans la sous-section Ajouter une base de données NoSQL, nous avons créé un composant de base de données NoSQL qui contient un document appelé clients. Maintenant nous aimerions que MapForce prenne en considération les critères de filtrage pendant qu’il génère un nouveau schéma. Dans notre collection clients, il existe des documents de deux types (voir ci-dessous).
doc.customers1
« CustomerID »: "ALFKI",
« CompanyName »: « Alfreds Futterkiste »,
« ContactName » : « Maria Anders »,
« ContactTitle » : « Sales Representative »,
« Adresse » : « Obere Str. 57 »,
« City » : « Berlin »,
« Région » : « NULL »,
« PostalCode » : "12209",
« Country » : « Germany »,
« Phone » : « 030-0074321 »,
« Fax » : « 030-0076545 »
doc.customers2
« 0 » : "BOTTM",
« 1 » : « Bottom-Dollar Markets »,
« 2 » : « Elizabeth Lincoln »,
« 3 » : « Accounting Manager »,
« 4 » : « 23 Tsawassen Blvd. »,
« 5 » : « Tsawassen »,
« 6 » : "BC",
« 7 » : « T2F 8M4 » :
« 8 » : « Canada »,
« 9 » : « (604) 555-4729 »,
« 10 » : « (604) 555-3745 »
Maintenant nous voulons que notre fichier de schéma soit basé sur la structure avec des champs de nom (doc.customers1). La capture d’écran ci-dessous illustre nos critères de filtrage, qui est exécuté comme suit : Sélectionnez uniquement ces documents dans lesquels le champ CustomerID existe (voir la capture d’écran ci-dessous). Le parser sera exécuté dans la liste de tous les documents de la collection et choisira uniquement ceux qui répondent à ce critère. Pour en savoir plus sur la syntaxe pour réaliser une requête de documents dans une collection, voir la documentation MongoDB.
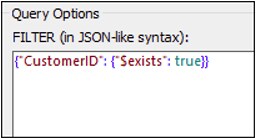
Après avoir filtré vos données, vous pourrez aussi choisir de les trier, par exemple, basé sur le champs City. Vous pourrez ensuite spécifier combien de documents de l’échantillon trié vous souhaitez ignorer (SKIP) et/ou prendre en compte (LIMIT) pour votre génération de schéma.
Important
Quand vous choisissez de filtrer et/ou trier vos données, un sous-ensemble de vos documents comme celui dans doc.customers2 ne correspondra pas au schéma généré, qui causera des erreurs de validation. Pour éviter ces erreurs, sélectionnez Ignorer les documents invalides et poursuivre dans la boîte de dialogue Assigner un schéma JSON à la collection (voir la capture d’écran ci-dessus). |